cuda编程-并行规约
利用shared memory计算,并避免bank conflict;通过每个block内部规约,然后再把所有block的计算结果在CPU端累加
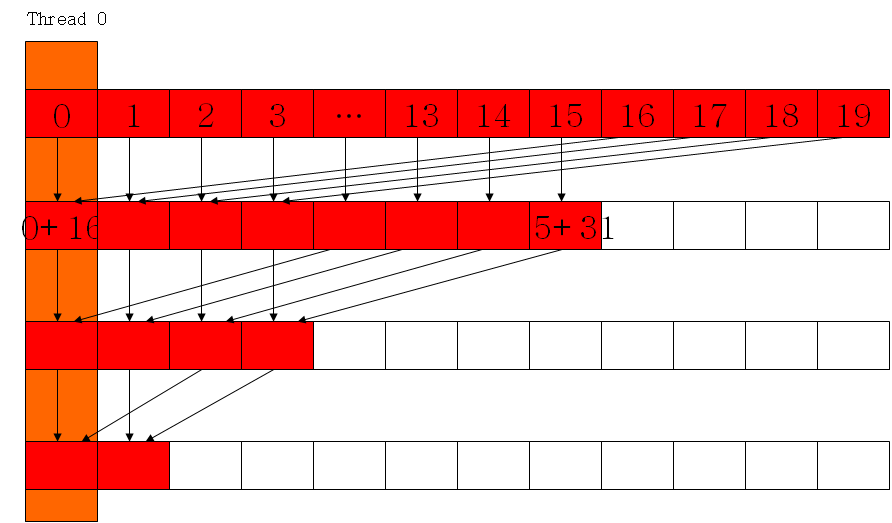
代码:
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <stdio.h>
#include <stdlib.h>
#include <memory>
#include <iostream> #define DATA_SIZE 128
#define TILE_SIZE 64 __global__ void reductionKernel(float *in, float *out){
int tx = threadIdx.x;
int bx = blockIdx.x; __shared__ float data_shm[TILE_SIZE];
data_shm[tx] = in[bx * blockDim.x + tx];
__syncthreads(); for (int i = blockDim.x / ; i > ; i >>= ){
if (tx < i){
data_shm[tx] += data_shm[tx + i];
}
__syncthreads();
} if (tx == )
out[bx] = data_shm[];
} void reduction(){
int out_size = (DATA_SIZE + TILE_SIZE - ) / TILE_SIZE;
float *in = (float*)malloc(DATA_SIZE * sizeof(float));
float *out = (float*)malloc(out_size*sizeof(float));
for (int i = ; i < DATA_SIZE; ++i){
in[i] = i;
}
memset(out, , out_size*sizeof(float)); float *d_in, *d_out;
cudaMalloc((void**)&d_in, DATA_SIZE * sizeof(float));
cudaMalloc((void**)&d_out, out_size*sizeof(float));
cudaMemcpy(d_in, in, DATA_SIZE * sizeof(float), cudaMemcpyHostToDevice); dim3 block(TILE_SIZE, );
dim3 grid(out_size, );
reductionKernel << <grid, block >> >(d_in, d_out); cudaMemcpy(in, d_in, DATA_SIZE * sizeof(float), cudaMemcpyDeviceToHost);
cudaMemcpy(out, d_out, out_size * sizeof(float), cudaMemcpyDeviceToHost); float sum = ;
for (int i = ; i < out_size; ++i){
sum += out[i];
}
std::cout << sum << std::endl; // Check on CPU
float sum_cpu = ;
for (int i = ; i < DATA_SIZE; ++i){
sum_cpu += in[i];
}
std::cout << sum_cpu << std::endl; }
cuda编程-并行规约的更多相关文章
- CUDA中并行规约(Parallel Reduction)的优化
转自: http://hackecho.com/2013/04/cuda-parallel-reduction/ Parallel Reduction是NVIDIA-CUDA自带的例子,也几乎是所有C ...
- 【Cuda编程】加法归约
目录 cuda编程并行归约 AtomicAdd调用出错 gpu cpu下时间计算 加法的归约 矩阵乘法 矩阵转置 统计数目 平方和求和 分块处理 线程相邻 多block计算 cuda编程并行归约 At ...
- CUDA编程(六)进一步并行
CUDA编程(六) 进一步并行 在之前我们使用Thread完毕了简单的并行加速,尽管我们的程序运行速度有了50甚至上百倍的提升,可是依据内存带宽来评估的话我们的程序还远远不够.在上一篇博客中给大家介绍 ...
- cuda编程基础
转自: http://blog.csdn.net/augusdi/article/details/12529247 CUDA编程模型 CUDA编程模型将CPU作为主机,GPU作为协处理器(co-pro ...
- CUDA学习笔记(一)——CUDA编程模型
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm56.html CUDA的代码分成两部分,一部分在host(CPU)上运行,是普通的C代码:另一部分在d ...
- CUDA编程
目录: 1.什么是CUDA 2.为什么要用到CUDA 3.CUDA环境搭建 4.第一个CUDA程序 5. CUDA编程 5.1. 基本概念 5.2. 线程层次结构 5.3. 存储器层次结构 5.4. ...
- CUDA编程-(1)Tesla服务器Kepler架构和万年的HelloWorld
结合CUDA范例精解以及CUDA并行编程.由于正在学习CUDA,CUDA用的比较多,因此翻译一些个人认为重点的章节和句子,作为学习,程序将通过NVIDIA K40服务器得出结果.如果想通过本书进行CU ...
- CUDA编程模型
1. 典型的CUDA编程包括五个步骤: 分配GPU内存 从CPU内存中拷贝数据到GPU内存中 调用CUDA内核函数来完成指定的任务 将数据从GPU内存中拷贝回CPU内存中 释放GPU内存 *2. 数据 ...
- CUDA编程之快速入门
CUDA(Compute Unified Device Architecture)的中文全称为计算统一设备架构.做图像视觉领域的同学多多少少都会接触到CUDA,毕竟要做性能速度优化,CUDA是个很重要 ...
随机推荐
- piwik源码安装部署
一简单介绍1.piwik介绍Piwik是一个PHP和MySQL的开放源代码的Web统计软件,它给你一些关于你的网站的实用统计报告,比如网页浏览人数,访问最多的页面,搜索引擎关键词等等.Piwik拥有众 ...
- vue 生产环境 background 背景图不显示原因
通常我们使用img标签引入文件,npm run build 打包后 ,因为img为html标签,打包后他的路径是由index.html开始访问的,他走static/img/'图片名'是能正确访问到图片 ...
- form,ajax注册,logging日志使用
一.form表单类型提交注册信息 二.ajax版本提交注册信息 <!DOCTYPE html> <html lang="en"> <head> ...
- Python全栈开发之路 【第七篇】:面向对象编程设计与开发(1)
本节内容 一.编程范式 编程指的是写程序.敲代码,就是指程序员用特定的语法.数据结构和算法编写的代码,目的是来告诉计算机如何执行任务的. 在编程的世界里最常见的两大流派是:面向过程与面向对象.“功夫的 ...
- H5 38-背景图片和插入图片区别
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- AtCoder Beginner Contest 053
D - Card Eater Time limit : 2sec / Memory limit : 256MB Score : 400 points Problem Statement Snuke h ...
- ubuntu中搭建svn服务器步骤
1.安装软件包: sudo apt-get install subversion 2.建立相关文件夹(这里svn放在home文件夹中) cd /home sudo mkdir svn cd /home ...
- Jenkins部署net core小记
作为一个不熟悉linux命令的neter,在centos下玩Jenkins真的是一种折磨啊,但是痛并快乐着,最后还是把demo部署成功!写这篇文章是为了记录一下这次部署的流程,和心得体会. 网上很多资 ...
- Django之事务
Django之事务 事务就是将一组操作捆绑在一起,只有当这一组操作全部都成功以后这个事务才算成功;当这组操作中有任何一个没有操作成功,则这个操作就会回滚,回到操作之前的状态. 其中牵扯到向数据库中写数 ...
- Alibaba Cloud Toolkit for Eclipse & ECS、EDAS 或容器服务 Kubernetes
UserGuide_V2.1.0http://toolkit.aliyun.com/eclipse/?spm=5176.2020520130.105.3.3c3b697bOHma9f&msct ...