ssdb主从及双主模型配置和简单管理
ssdb主从及双主模型配置和简单管理
levelDB是一个key->value 的数据存储库,其只能在本地保存数据,支持持久化,并且支持保存非常大的数据,单机redis在保存较大数据的时候数十G的时候会出现响应慢等问题,而单机levelDB数据在150G以内的时候依然可以保持比较好的性能,其随机写入key->value的数据每秒可达到40W条,每秒随机读在6W,写比读还要快,因此适用于写操作大于读操作的场景,并且不支持网络传输, 即只能本机访问数据,官网地址http://leveldb.org/,国内有360基于levelDB开发支持了网络接口的SSDB,SSDB是一个 C/C++ 语言开发的高性能 NoSQL 数据库, 支持 KV, list, map(hash), zset(sorted set) 等数据结构, 用来替代或者与 Redis 配合存储十亿级别列表的数据,SSDB支持100倍与redis的容量,因此宣称要替换redis,SSDB支持网络、支持redis客户端、支持python/java/go/PHP/C++语言、支持持久化、支持主从复制、主主复制和负载均衡等功能
官方文档:http://ssdb.io/zh_cn/
安装文档:http://ssdb.io/docs/zh_cn/install.html
SSD可以用于保证数据不丢失的场景而不是单单的数据缓存场景,用了SSDB尽量要每天晚上备份文件目录,即使做了主从也要对目录使用其自带的ssdb-dump工具进行备份。
环境: centos 7.X x86_64
centos6.X系统环境可能python版本和作者使用的有兼容性问题需要注意
一、ssdb服务的安装和配置
1.安装依赖
# yum install -y jemalloc-devel autoconf
2.下载安装包并编译
# cd /usr/local/src
# wget --no-check-certificate https://github.com/ideawu/ssdb/archive/master.zip
# unzip master.zip
[root@node2 src]# cd ssdb-master/
[root@node2 ssdb-master]# make
# 默认安装在 /usr/local/ssdb 目录下
[root@node2 ssdb-master]# make install
3.修改启动脚本
[root@node2 ssdb-master]# cp tools/ssdb.sh /etc/init.d/ssdb [root@node2 ssdb-master]# vim /etc/init.d/ssdb
configs="/usr/local/ssdb/ssdb.conf"
4.加入启动项
[root@node2 src]# chkconfig --add ssdb
[root@node2 src]# chkconfig ssdb on
[root@node2 src]# chkconfig --list ssdb
ssdb :off :off :on :on :on :on :off
5.配置命令路径
# vim /etc/profile PATH=$PATH:/usr/local/ssdb
export PATH # source /etc/profile
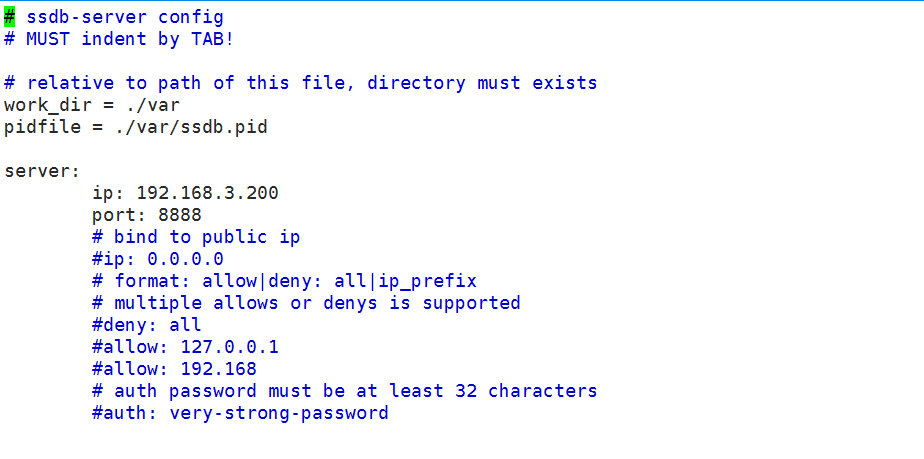
5.修改配置文件
# vim /usr/local/ssdb/ssdb.conf
server:
ip: 192.168.3.200
port:
6.启动服务
[root@node2 ssdb-master]# /etc/init.d/ssdb start
Reloading systemd: [ OK ]
Starting ssdb (via systemctl): [ OK ] [root@node2 ssdb-master]# ss -tnlp|grep
LISTEN 192.168.3.200: *:* users:(("ssdb-server",pid=,fd=))
连接服务测试
[root@node2 ssdb-master]# ssdb-cli -h 192.168.3.200 -p
ssdb (cli) - ssdb command line tool.
Copyright (c) - ssdb.io 'h' or 'help' for help, 'q' to quit. ssdb-server 1.9. ssdb 192.168.3.200:> set name jack
ok
(0.001 sec)
ssdb 192.168.3.200:> set age
ok
(0.001 sec)
ssdb 192.168.3.200:> get name
jack
二、配置主从同步
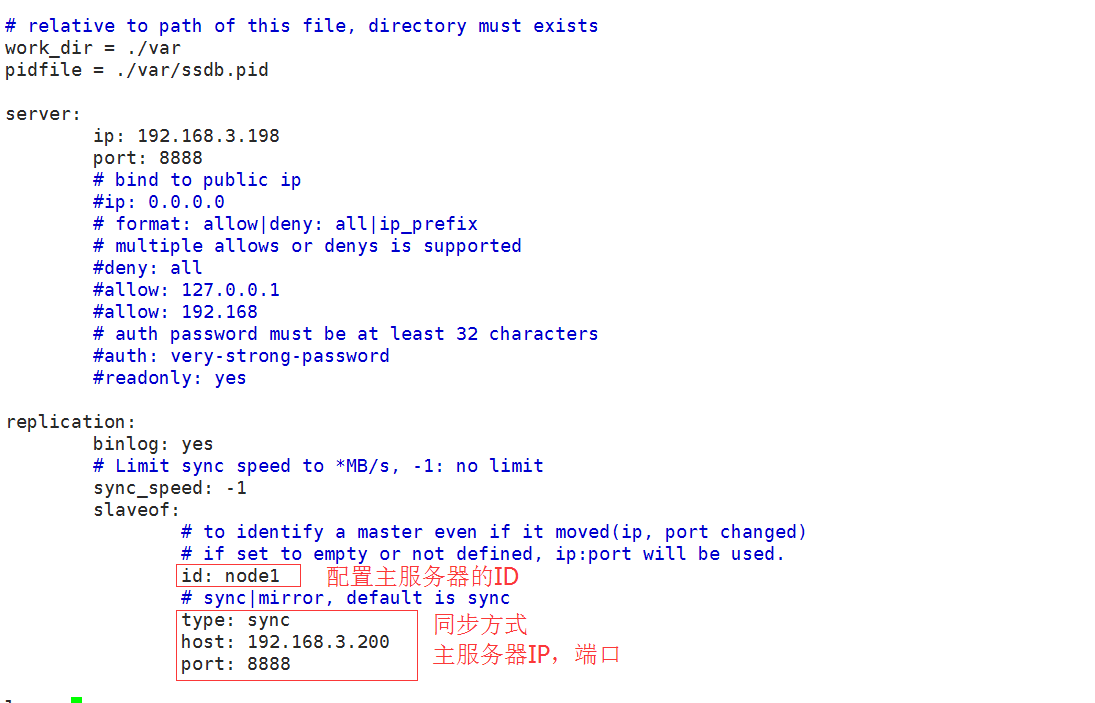
从服务器配置:
配置主服务器的ID、type、host、port即可
replication:
binlog: yes
sync_speed: -
slaveof:
id: node1
type: sync
host: 192.168.3.200
port:
测试在主节点上添加一个key在从节点上就可以马上看到
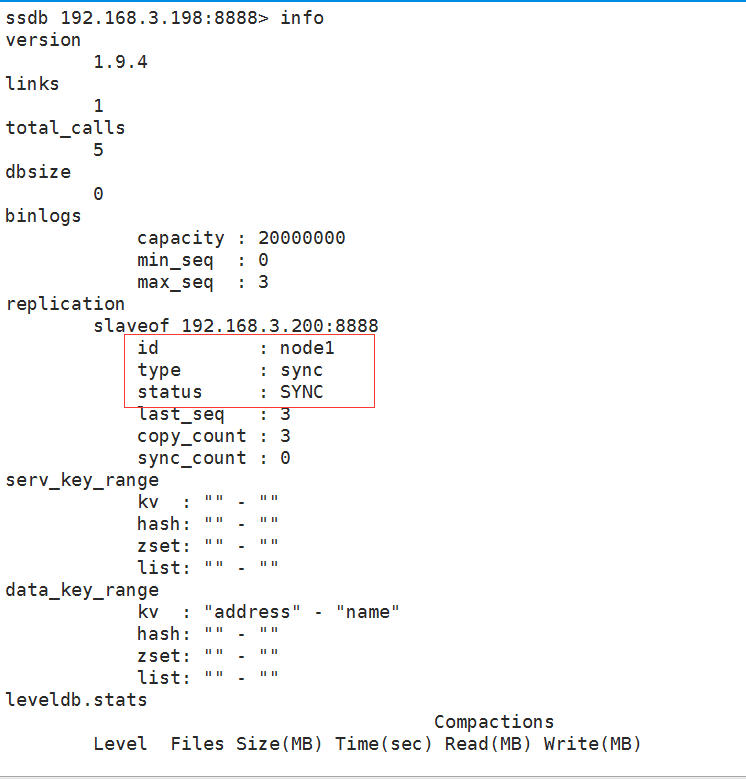
从服务器info信息
ssdb 192.168.3.198:> info
version
1.9.
links total_calls dbsize binlogs
capacity :
min_seq :
max_seq :
replication
slaveof 192.168.3.200:
id : node1
type : sync
status : SYNC
last_seq :
copy_count :
sync_count :
serv_key_range
kv : "" - ""
hash: "" - ""
zset: "" - ""
list: "" - ""
data_key_range
kv : "address" - "salary"
hash: "" - ""
zset: "" - ""
list: "" - ""
leveldb.stats
Compactions
Level Files Size(MB) Time(sec) Read(MB) Write(MB)
主服务器info信息
ssdb 192.168.3.200:> info
version
1.9.
links total_calls dbsize binlogs
capacity :
min_seq :
max_seq :
replication
client 192.168.3.198:
type : sync
status : SYNC
last_seq :
serv_key_range
kv : "" - ""
hash: "" - ""
zset: "" - ""
list: "" - ""
data_key_range
kv : "address" - "name"
hash: "" - ""
zset: "" - ""
list: "" - ""
leveldb.stats
Compactions
Level Files Size(MB) Time(sec) Read(MB) Write(MB)
二、配置双主同步(主要是高可用)
SSDB 数据库是支持双主(双 Master)和多主架构的. 而且, 我们的应用也是部署双主架构, 但当作单主来用. 也就是说, 平时只往其中一个写, 当出现故障时, 整体切换到另一个主上面. 如果应用层已经解决了数据拆分, 也即不会两个节点同时操作一个 key, 那么就可以放心使用双主同时写入.
SSDB 双主的配置非常简单:
只需要将 type 设置为 mirror, 然后每个节点各指向对方即可.
如果是多主, 则每个节点要指向其它 n-1 个节点.
node1中的配置信息:
server:
ip: 192.168.3.200
port: replication:
binlog: yes
sync_speed: -
slaveof:
id: node2
type: mirror
host: 192.168.3.198
port:
node2中的配置信息:
server:
ip: 192.168.3.198
port: replication:
binlog: yes
sync_speed: -
slaveof:
id: node1
type: mirror
host: 192.168.3.200
port:

node1中的info信息:
ssdb 192.168.3.200:> info
version
1.9.
links total_calls dbsize binlogs
capacity :
min_seq :
max_seq :
replication
client 192.168.3.198:
type : mirror
status : SYNC
last_seq :
replication
slaveof 192.168.3.198:
id : node2
type : mirror
status : SYNC
last_seq :
copy_count :
sync_count :
serv_key_range
kv : "" - ""
hash: "" - ""
zset: "" - ""
list: "" - ""
data_key_range
kv : "address" - "salary"
hash: "" - ""
zset: "" - ""
list: "" - ""
leveldb.stats
Compactions
Level Files Size(MB) Time(sec) Read(MB) Write(MB)
--------------------------------------------------
node2中的info信息:
ssdb 192.168.3.198:> info
version
1.9.
links total_calls dbsize binlogs
capacity :
min_seq :
max_seq :
replication
client 192.168.3.200:
type : mirror
status : SYNC
last_seq :
replication
slaveof 192.168.3.200:
id : node1
type : mirror
status : SYNC
last_seq :
copy_count :
sync_count :
serv_key_range
kv : "" - ""
hash: "" - ""
zset: "" - ""
list: "" - ""
data_key_range
kv : "address" - "salary"
hash: "" - ""
zset: "" - ""
list: "" - ""
leveldb.stats
Compactions
Level Files Size(MB) Time(sec) Read(MB) Write(MB)
--------------------------------------------------
此时在任意节点写入数据都会在另外的节点查询到
四、监控工具的使用
将php文件上传到/var/www/html/phpssdbadmin目录
lnmp架构的方法
# yum -y install php php-mysql nginx php-gd* php-mcrypt
修改/etc/nginx/nginx.conf
location /phpssdbadmin {
try_files $uri $uri/ /phpssdbadmin/index.php?$args;
}
index index.php;
root /var/www/html;
location ~ \.php$ {
include fastcgi_params;
fastcgi_pass 127.0.0.1:;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
}
lamp架构的方法
lamp架构的方法
yum install -y httpd php php-gd*
编辑/etc/httpd/conf/httpd.conf
打开rewrite模块
LoadModule rewrite_module modules/mod_rewrite.so DocumentRoot "/var/www/html"
<Directory />
Options FollowSymLinks
AllowOverride All # 修改为All
</Directory> <Directory "/var/www/html">
Order allow,deny
Allow from all
AllowOverride All # 改为all
</Directory>
在根目录下简历.htaccess文件内容如下:
# cat phpssdbadmin/.htaccess
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /var/www/html/phpssdbadmin
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /phpssdbadmin/index.php [L]
</IfModule>
OK,然后重启服务器,service httpd restart ,这样.htaccess就可以使用了
ssdb主从及双主模型配置和简单管理的更多相关文章
- Apache+lvs高可用+keepalive(主从+双主模型)
Apache+lvs高可用+keepalive(主从+双主模型) keepalive实验准备环境: httpd-2.2.15-39.el6.centos.x86_64 keepalived-1 ...
- MySQL Replication, 主从和双主配置
MySQL Replication, 主从和双主配置 MySQL的Replication是一种多个MySQL的数据库做主从同步的方案,特点是异步,广泛用在各种对MySQL有更高性能,更高可靠性要求的场 ...
- keepalived + haproxy 实现web 双主模型的高可用负载均衡--转
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://xz159065974.blog.51cto.com/8618592/140581 ...
- 2、Keepalived提供日志与双主模型演示
Keepalived实例演示: 利用keepalived流动一个VIP,在提供LVS的高可用以及实现对LVS后端的real server做健康状态检测,最后实现高可用nginx. HA Clust ...
- 【 Linux 】Keepalived实现双主模型高可用集群
要求: 1. 两台web服务器安装wordpress,数据库通过nfs共享 2. 使用keepalived实现双主模型 环境: 主机: 系统:CentOS6.7 x64 ...
- Linux-实现双主模型的nginx的高可用
实现双主模型的ngnix高可用(一) 准备:主机7台 client: 172.18.x.x 调度器:keepalived+nginx 带172.18.x.x/16 网卡 192.168.234.27 ...
- Keepalive双主搭建配置
Keepalive 双主搭建配置 keepalived保证双主数据库的可用性 环境说明 192.168.1.10 keepalive 主1 192.168.1.20 keepalive 主2 19 ...
- haproxy+keepalived主备与双主模式配置
Haproxy+Keepalived主备模式 主备节点设置 主备节点上各安装配置haproxy,配置内容且要相同 global log 127.0.0.1 local2 chroot /var/lib ...
- mysql传统主从、双主复制+keepalived配置步骤
mysql主从.主主复制(双主复制)配置步骤 一:MySQL复制: MySQL复制简介: 将master服务器中主数据库的ddl和dml操作通过二进制日志传到slaves服务器上,然后在master服 ...
随机推荐
- python+selenium 模拟登陆,自动下单
目前写的实在太粗糙,留着,以后来写上
- 自己制作redis 和mongo 镜像
root@docker-lab:~/redis# ll total drwxr-xr-x root root Feb : ./ drwx------ root root Feb : ../ -rw-r ...
- 酷狗.kgtemp文件加密算法逆向
该帖转载于孤心浪子--http://www.cnblogs.com/KMBlog/p/6877752.html 酷狗音乐上的一些歌曲是不能免费下载的,然而用户仍然可以离线试听,这说明有缓存文件,并且极 ...
- JDK源码之数组
序言 <1>栈内存和堆内存当一个方法执行时,每个方法都会建立自己的内存栈,在这方法内定义的变量将会逐个放入这块栈内存里,随着方法的执行结束,这个方法的内存栈也将自然销毁.所有在方法中定义的 ...
- 三十四、Linux 进程与信号——信号特点、信号集和信号屏蔽函数
34.1 信号特点 信号的发生是随机的,但信号在何种条件下发生是可预测的 进程杠开始启动时,所有信号的处理方式要么默认,要么忽略:忽略是 SIGUSR1 和 SIGUSR2 两个信号,其他都采取默认方 ...
- 六、文件IO——fcntl 函数 和 ioctl 函数
6.1 fcntl 函数 6.1.1 函数介绍 #include <unistd.h> #include <fcntl.h> int fcntl(int fd, int cmd ...
- 【SRM-07 D】天才麻将少女KPM
Description 天才麻将少女KPM立志要在日麻界闯出一番名堂.KPM上周叒打了n场麻将,但她这次又没控分,而且因为是全市参与的麻将大赛,所以她的名次范围是0..10^5.名次可能等于0是因为K ...
- form表单post提交的数据格式
1.浏览器行为:Form表单提交 action:url 地址,服务器接收表单数据的地址 method:提交服务器的http方法,一般为post和get name:最好好吃name属性的唯一性 enct ...
- luogu P3242 [HNOI2015]接水果
传送门 其实这题难点在于处理路径包含关系 先求出树的dfn序,现在假设路径\(xy\)包含\(uv(dfn_x<dfn_y,dfn_u<dfn_v)\) 如果\(lca(u,v)!=u\) ...
- nnet3中的数据类型
目标与背景 之前的nnet1和nnet2基于Component对象,是一个组件的堆栈.每个组件对应一个神经网络层,为简便起见,将一个仿射变换后接一个非线性表示为一层网络,因此每层网络有两个组件.这些旧 ...