spark原理
SparkContext将应用程序代码分发到各Executors,最后将任务(Task)分配给executors执行
- Application: Appliction都是指用户编写的Spark应用程序,其中包括一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码
- Driver: Spark中的Driver即运行上述Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中有SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭,通常用SparkContext代表Driver
Driver重点:创建和关闭sparkcontext.
- Executor: 某个Application运行在worker节点上的一个进程, 该进程负责运行某些Task, 并且负责将数据存到内存或磁盘上,每个Application都有各自独立的一批Executor, 在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutor Backend。一个CoarseGrainedExecutor Backend有且仅有一个Executor对象, 负责将Task包装成taskRunner,并从线程池中抽取一个空闲线程运行Task, 这个每一个oarseGrainedExecutor Backend能并行运行Task的数量取决与分配给它的cpu个数
excutor重点:某个Application运行在worker节点上的一个进程,该进程负责运行某些Task,运行Task的数量取决与分配给它的cpu个数。
Work为子节点。
Job:根据Job构建基于Stage的DAG
Stage:多个taskset(task集合)
Task:执行的任务的最小单位。
Spark Cluster模式:
- 在YARN-Cluster模式中,当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
- 第一个阶段是把Spark的Driver(创建sparkcontext,构建环境)作为一个ApplicationMaster在YARN集群中先启动;
- 第二个阶段是由ApplicationMaster创建应用程序,然后为它向ResourceManager申请资源,并启动Executor来运行Task,同时监控它的整个运行过程,直到运行完成
- YARN-cluster的工作流程分为以下几个步骤
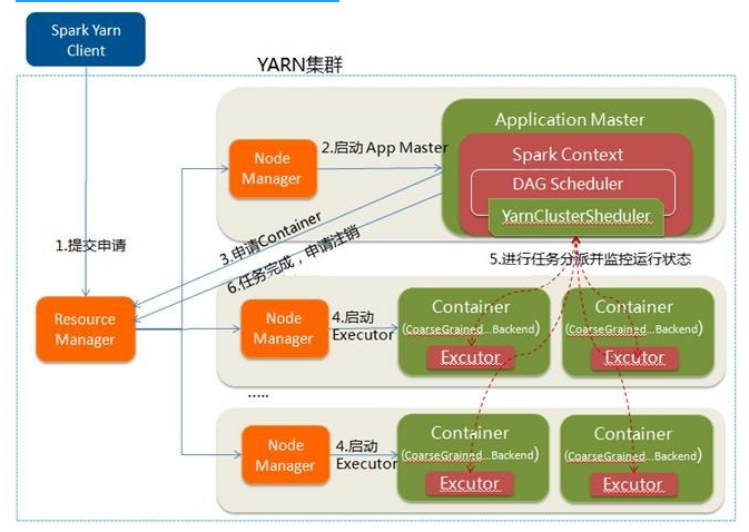
待续
spark原理的更多相关文章
- Spark原理分析目录
1 Spark原理分析 -- RDD的Partitioner原理分析 2 Spark原理分析 -- RDD的shuffle简介 3 Spark原理分析 -- RDD的shuffle框架的实现概要分析 ...
- Spark原理小总结
1.spark是什么? 快速,通用,可扩展的分布式计算引擎 2.弹性分布式数据集RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据 ...
- Update(Stage4):Spark原理_运行过程_高级特性
如何判断宽窄依赖: =================================== 6. Spark 底层逻辑 导读 从部署图了解 Spark 部署了什么, 有什么组件运行在集群中 通过对 W ...
- spark原理介绍
1.spark是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速.因此运行spark的机器应该尽量的大内存,如96G以上. 2.spark所有操作均基于RDD,操作主要分成2大类:tra ...
- spark原理介绍 分类: B8_SPARK 2015-04-28 12:33 1039人阅读 评论(0) 收藏
1.spark是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速.因此运行spark的机器应该尽量的大内存,如96G以上. 2.spark所有操作均基于RDD,操作主要分成2大类:tra ...
- Spark原理概述
原文来自我的个人网站:http://www.itrensheng.com/archives/Spark_basic_knowledge 一. Spark出现的背景 在Spark出现之前,大数据计算引擎 ...
- 《Spark大数据处理》---Spark原理
- 大数据组件原理总结-Hadoop、Hbase、Kafka、Zookeeper、Spark
Hadoop原理 分为HDFS与Yarn两个部分.HDFS有Namenode和Datanode两个部分.每个节点占用一个电脑.Datanode定时向Namenode发送心跳包,心跳包中包含Datano ...
- Spark基本架构及原理
Hadoop 和 Spark 的关系 Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁 ...
随机推荐
- nginx问题集锦
1.配置访问指定路径的文件 以访问/mnt/data/logs下文件为例,修改nginx.conf配置,执行命令重新加载/usr/local/nginx/sbin/nginx -s reload lo ...
- vue 动态添加 <style> 样式 vue动态添加 绑定自定义字体样式
created(){ //动态添加自定义字体样式 let style = document.createElement('style'); style.type = "text/css&qu ...
- C# 异步示例代码
在 使用BackgroundWorker组件 一文中,阐述了在Winform编程中,使用BackgroundWorker组件实现异步调用,本文主要讲述利用委托实现异步. 以下描述摘抄于MSDN: 异步 ...
- Jquery中小数取整
var uu=Math.floor(5.36) 向下取整 结果为5 var uu=Math.floor(5.88) 结果为5 Math.ceil(5.33) 向上取整,结果为6 Math.round( ...
- 云笔记项目-Spring事务学习-传播SUPPORTS
接下来测试事务传播属性SUPPORTS Service层 Service层将方法的事务传播属性设置为SUPPORTS LayerT层代码 package LayerT; import javax.an ...
- html入门第二天。
二·1.图片与多媒体:-------------- img标签(重中之重): 网页中的图片展示就是用的img标签实现,img元素相网页中嵌入一幅图形,行内标签,单标签. 基础语句:<img sr ...
- 使用quaggaJS识别图片中的条形码
quaggaJS是一个纯JS的插件,用于识别图片中的条形码,很方便.一般用于移动端拍照识别,也可以在网页端上传图片识别. github下载地址 首先要指定正确格式的条形码,常见的条形码编码类型有EAN ...
- Python设计模式 - UML - 通信图(Communication Diagram)
简介 通信图表示对象之间的消息往来,是表述时序图中信息交互的另一种UML图,介绍完时序图就要对照学习一下通信图,二者是一体两面的. 通信图和时序图可以相互转换,二者的侧重点不同,通信图侧重哪些对象发送 ...
- VS下.net开发常用扩展、配置
Vue.js Pack Copy As Html HTML Tools Word Highlight With Margin 绿豆沙颜色:R:199 G:237 U:204
- 针对特定网站scrapy爬虫的性能优化
在使用scrapy爬虫做性能优化时,一定要根据不同网站的特点来进行优化,不要使用一种固定的模式去爬取一个网站,这个是真理,以下是对58同城的爬取优化策略: 一.先来分析一下影响scrapy性能的set ...