spark原理
SparkContext将应用程序代码分发到各Executors,最后将任务(Task)分配给executors执行
- Application: Appliction都是指用户编写的Spark应用程序,其中包括一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码
- Driver: Spark中的Driver即运行上述Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中有SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭,通常用SparkContext代表Driver
Driver重点:创建和关闭sparkcontext.
- Executor: 某个Application运行在worker节点上的一个进程, 该进程负责运行某些Task, 并且负责将数据存到内存或磁盘上,每个Application都有各自独立的一批Executor, 在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutor Backend。一个CoarseGrainedExecutor Backend有且仅有一个Executor对象, 负责将Task包装成taskRunner,并从线程池中抽取一个空闲线程运行Task, 这个每一个oarseGrainedExecutor Backend能并行运行Task的数量取决与分配给它的cpu个数
excutor重点:某个Application运行在worker节点上的一个进程,该进程负责运行某些Task,运行Task的数量取决与分配给它的cpu个数。
Work为子节点。
Job:根据Job构建基于Stage的DAG
Stage:多个taskset(task集合)
Task:执行的任务的最小单位。
Spark Cluster模式:
- 在YARN-Cluster模式中,当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
- 第一个阶段是把Spark的Driver(创建sparkcontext,构建环境)作为一个ApplicationMaster在YARN集群中先启动;
- 第二个阶段是由ApplicationMaster创建应用程序,然后为它向ResourceManager申请资源,并启动Executor来运行Task,同时监控它的整个运行过程,直到运行完成
- YARN-cluster的工作流程分为以下几个步骤
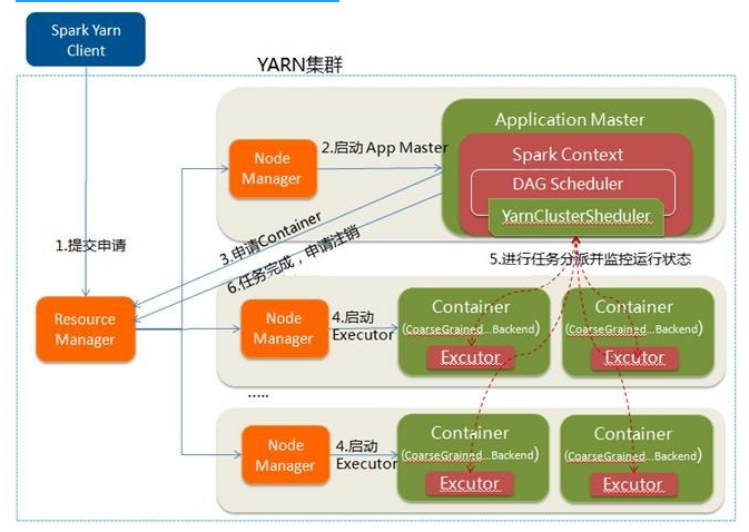
待续
spark原理的更多相关文章
- Spark原理分析目录
1 Spark原理分析 -- RDD的Partitioner原理分析 2 Spark原理分析 -- RDD的shuffle简介 3 Spark原理分析 -- RDD的shuffle框架的实现概要分析 ...
- Spark原理小总结
1.spark是什么? 快速,通用,可扩展的分布式计算引擎 2.弹性分布式数据集RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据 ...
- Update(Stage4):Spark原理_运行过程_高级特性
如何判断宽窄依赖: =================================== 6. Spark 底层逻辑 导读 从部署图了解 Spark 部署了什么, 有什么组件运行在集群中 通过对 W ...
- spark原理介绍
1.spark是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速.因此运行spark的机器应该尽量的大内存,如96G以上. 2.spark所有操作均基于RDD,操作主要分成2大类:tra ...
- spark原理介绍 分类: B8_SPARK 2015-04-28 12:33 1039人阅读 评论(0) 收藏
1.spark是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速.因此运行spark的机器应该尽量的大内存,如96G以上. 2.spark所有操作均基于RDD,操作主要分成2大类:tra ...
- Spark原理概述
原文来自我的个人网站:http://www.itrensheng.com/archives/Spark_basic_knowledge 一. Spark出现的背景 在Spark出现之前,大数据计算引擎 ...
- 《Spark大数据处理》---Spark原理
- 大数据组件原理总结-Hadoop、Hbase、Kafka、Zookeeper、Spark
Hadoop原理 分为HDFS与Yarn两个部分.HDFS有Namenode和Datanode两个部分.每个节点占用一个电脑.Datanode定时向Namenode发送心跳包,心跳包中包含Datano ...
- Spark基本架构及原理
Hadoop 和 Spark 的关系 Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁 ...
随机推荐
- shell脚本中获取当前所在目录地址
shell脚本中获取当前所在目录如下 #!/bin/bash work_path=$() cd ${work_path} work_path=$(pwd) cd ${work_path}/src
- 百度获取图片 json格式解析
var h,i: integer; ss, url: string; mem: TMemoryStream; str1: tstringlist; memstr: TStringStream; idd ...
- MySql:SELECT 语句(四)通配符的使用
1. LIKE 操作符 要在搜索子句中使用通配符,必须要使用 LIKE 操作符. 1)百分号通配符 最常用的通配符是百分号(%). % 表示任何字符出现的任意次数.但是 NULL 除外.可以匹配 0 ...
- 剑指offer——从上往下打印二叉树
题目描述:从上到下打印二叉树的节点,同一层的从左到右打印 思路:采用队列来存储单层的节点,然后通过删除队列的头结点操作,依次遍历每一层. 代码为: import java.util.ArrayList ...
- mysql安装好之后,查询显示MySQL不是内部命令或外部命令问题
使用cmd来调用MySQL的时候提示错误,错误是说MySQL不是内部或外部命令. 1.如图所示,遇到的mysql命令错误. 2.现在就要查询mysql是安装在哪,我们在计算机里面搜索mysql.exe ...
- Servlet中清除session
HttpSession sessions = request.getSession(false);//防止创建Session if(sessions == null){ response.sendRe ...
- PL/SQL简单使用——导入、导出数据表
1.使用PL/SQL导出.导入表 在使用PL/SQL操作oracle数据库时,经常使用的一个操作就是将自己写的数据表导出,或者想把他人的数据表导入到自己的数据库中.虽然是很简单的操作,但自己之前一直出 ...
- C博客01--顺序、分支结构
1.本章学习总结 1.1 思维导图 1.2 本章学习体会及代码量学习体会 1.2.1 学习体会 经过一周的初步学习,对C语言我有了一定的认识,也体验到了代码的乐趣,这应该为我以后的学习开了一个好头.在 ...
- oslo_db使用
oslo_db是openstak中封装数据库访问sqlachmy的模块,网上搜索的资源并不多,除了openstack官方文档,在实际使用中的例子凤毛麟角. 有感于资源太少,在学习heat源码的过程中, ...
- Java虚拟机运行时数据区域及垃圾回收算法
程序计数器 记录正在执行的虚拟机字节码指令的地址(如果正在执行的是本地方法则为空). Java 虚拟机栈 每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表.操作数栈.动态链接.方法出口 ...