Solr游标查询提高翻页效率
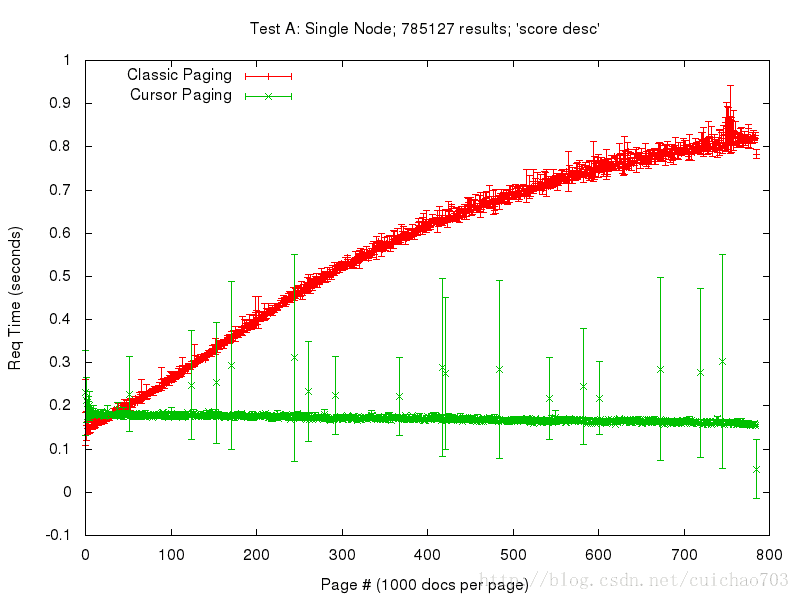
长期以来,我们一直有一个深分页问题。如果直接跳到很靠后的页数,查询速度会比较慢。这是因为Solr的需要为查询从开始遍历所有数据。直到Solr的4.7这个问题一直没有一个很好的解决方案。与最近发布的Solr的版本中,Solr使用了所谓的游标大幅度提高深翻页的性能。
问题
深分页的问题是很清楚。Solr必须为返回的搜索结果准备一个列表,并返回它的一部分。如果该部分来源于该列表的前面并不难。但如果我们想返回第10000页(每页20条记录)的数据,Solr需要准备一个包含大小为200000(10000
* 20)的列表。这样,它不仅需要时间,还需要内存。
令人高兴的是,Solr
4.7的发布改变了这一状况,引入了游标的概念。游标是一个动态结构,不需要存储在服务器上。游标包含了查询的结果的偏移量,因此,Solr的不再需要每次从头开始遍历结果直到我们想要的记录,游标的功能可以大幅提升深翻页的性能。但是是以消耗内存为代价的。(据个人测算10G的索引需要jvm为3.5G左右)。
用法
游标的使用非常简单。在第一个查询中,我们需要传递一个额外的参数- cursorMark = *,告诉Solr返回游标。在返回中除了搜索结果,我们还可以得到nextCursorMark信息。看看下面这个例子。
例如:
1.我们从一个简单的查询开始:
curl 'localhost:8983/solr/select?q=*:*&rows=1&sort=score+desc,id+asc&cursorMark=*
这里我们传入一个cursorMark = *参数,告诉Solr的,我们要使用的光标。
返回值除了平时返回的结果外,还多了一个游标数据nextCursorMark="AoIIP4AAACgwNTc5QjAwMg==",使用这个值作为我们翻下一页的参数。
2.下一页查询:
curl 'localhost:8983/solr/select?q=*:*&rows=1&sort=score+desc,id+asc&cursorMark=AoIIP4AAACgwNTc5QjAwMg=='
这样就查询出下一页数据,同样也返回了nextCursorMark参数。依次迭代即可实现翻页功能。
总结
Solr的4.7引入的这个游标参数非常简单,大大提升了翻页的效果
详细的测试报告看这里:
http://searchhub.org/2013/12/12/coming-soon-to-solr-efficient-cursor-based-iteration-of-large-result-sets
Solr游标查询提高翻页效率的更多相关文章
- solr facet查询及solrj 读取facet数据[转]
solr facet查询及solrj 读取facet数据 | 所属分类:solr facet solrj 一. Facet 简介 Facet 是 solr 的高级搜索功能之一 , 可以给用户提供更 ...
- Elasticsearch系列---搜索执行过程及scroll游标查询
概要 本篇主要介绍一下分布式环境中搜索的两阶段执行过程. 两阶段搜索过程 回顾我们之前的CRUD操作,因为只对单个文档进行处理,文档的唯一性很容易确定,并且很容易知道是此文档在哪个node,哪个sha ...
- SpringBoot整合Elasticsearch游标查询(scroll)
游标查询(scroll)简介 scroll 查询 可以用来对 Elasticsearch 有效地执行大批量的文档查询,而又不用付出深度分页那种代价. 游标查询会取某个时间点的快照数据. 查询初始化之后 ...
- Solr 排除查询
前言 solr排除查询也就是我们在数据库和程序中经常处理的不等于,solr的语法是在定语前加[-].. StringBuilder sbHtml=new StringBuilder(); shBhtm ...
- 【solr】之solr界面查询返回距离并排序
使用solr界面查询 {!geofilt}距离函数 star:[4 TO 5]星级排序 geodist() desc 距离排序 pt :31.221717,121.580891 sfield:loca ...
- 【转】Solr客户端查询参数总结
今天还是不会涉及到.Net和数据库操作,主要还是总结Solr 的查询参数,还是那句话,只有先明白了solr的基础内容和查询语法,后续学习solr 的C#和数据库操作,都是水到渠成的事.这里先列出sol ...
- Oracle使用游标查询指定数据表的所有字段名称组合而成的字符串
应用场合:参考网上查询数据表的所有字段名代码,使用游标生成指定单个表的所有字段名跟逗号组成的用于select 逗号隔开的字段名列表 from字符串等场合. 查询结果输出如下: 当前数据表TB_UD_ ...
- 如何大幅优化solr的查询性能(转)
提升软件性能,通常喜欢去调整各种启动参数,这没有多大意义,小伎俩. 性能优化要从架构和策略入手,才有可能得到较大的收益 Solr的查询是基于Field的,以Field为基本单元,例如一个文章站要索引 ...
- elasticsearch 布尔过滤器 游标查询 Scroll
组合过滤器 | Elasticsearch: 权威指南 | Elastic https://www.elastic.co/guide/cn/elasticsearch/guide/current/co ...
随机推荐
- Java单播、广播、多播(组播)---转
一.通信方式分类 在当前的网络通信中有三种通信模式:单播.广播和多播(组播),其中多播出现时间最晚,同时具备单播和广播的优点. 单播:单台主机与单台主机之间的通信 广播:当台主机与网络中的所有主机通信 ...
- react-router v4.0 知识点
react-router 提供了一个withRouter组件 withRouter可以包装任何自定义组件,将react-router 的 history,location,match 三个对象传入. ...
- 怎么在vi和vim上查找字符串
教你怎么在vi和vim上查找字符串 我们以samba的配置文件为例,搜索一个user的字符串. vim /etc/samba/smb.conf 打开smb.conf 命令模式下,输入/use ...
- 推荐四款 Bug 管理系统,最适合你的才是最好的!
转载自:https://www.jianshu.com/p/e7d3121eaaec 在这个移动互联网的时代,每天都会涌入大量新的 App,想要留住你的用户,必须时刻保持产品创新与系统的稳定.对于 ...
- 让Delphi XE5跟其他版本的Delphi共存 [转]
找到Delphi XE5的安装根目录 .... \Program Files (x86)\Embarcadero\RAD Studio\12.0\bin下的cglm.ini文件, 打开cglm.i ...
- git 克隆指定分支
git clone -b v2.8.1 https://git.oschina.net/oschina/android-app.git
- 车载文档记录(ROM)
一,缩写词定义 1,ECU和ECM ECU: Engine Control Unit 发动机控制单元:从用途上讲则是汽车专用微机控制器.ECM: Engine Control Module 发动机控制 ...
- 卸载QQ,360,迅雷,搜狗
如题. 以及一切中国的流行软件. 这帮家伙都不是一个人,后面都跟着一帮子助手,杀毒,自我保护,管家,桌面,播放器,等等等等,你也不知道电脑速度为什么会这么慢,但是他变慢了. 今天头天用 360优化速度 ...
- 宝塔linux面板运行jsp文件的配置工作
第一步宝塔安装和软件安装我们先安装宝塔面板(这个不需要我说咋弄吧) 安装完成后登录到宝塔面板然后安装软件我个人喜欢nginx最新版,mysql由于服务器配置很菜所以没发装56,php什么的我用不到就没 ...
- 【分布式session】Spring-session的使用
概述 Session用于保存用户信息,通常一个Session保存一个用户信息,在以Tomcat为Servlet Container的web应用中,用户信息都保存在HttpSession中: 当用户发起 ...