[大牛翻译系列]Hadoop(15)MapReduce 性能调优:优化MapReduce的用户JAVA代码
6.4.5 优化MapReduce用户JAVA代码
MapReduce执行代码的方式和普通JAVA应用不同。这是由于MapReduce框架为了能够高效地处理海量数据,需要成百万次调用map和reduce函数。每次调用仅用较少时间。那么就不能用普通的经验来预测常见库(含JDK)的性能表现。
|
进一步阅读 Joshua Bloch的《Effective Java》中有很多如何调优JAVA代码的方法 |
在技术45中介绍如何用分析器(profiler)查找MapReduce代码中消耗时间的地方。这里要用同样的技术来确定一下代码中的潜在问题。
public void map(LongWritable key, Text value,
OutputCollector<LongWritable, Text> output,
Reporter reporter) throws IOException { String[] parts = value.toString().split("\\.");
Text outputValue = new Text(parts[0]);
output.collect(key, outputValue);
}
在这部分中将介绍前面章节介绍过的两个影响代码性能的问题(正则表达式和缺乏代码重用),以及一些常见的方法。
正则表达式
正则表达式有非常丰富灵活的特性。然而灵活性意味着性能下降。有的时候,性能会降低到不可接受的地步。那么,作为一般准则,就应该在MapReduce中避免使用正则表达式。如果非用不可,也应该尽量寻找替代方法。
字符串令牌化(TOKENIZATION)
JAVA的文档推荐使用String.split和Scanner类来实现字符串令牌化。实际上,它们都是基于正则表达式,在MapReduce中会很慢。然后,就要考虑用JAVA文档不推荐的StringTokenizer。但是,StringTokenizer的算法性能也不是最优。Apache commons中的StringUtils类效率要更好。如图6.42所示。
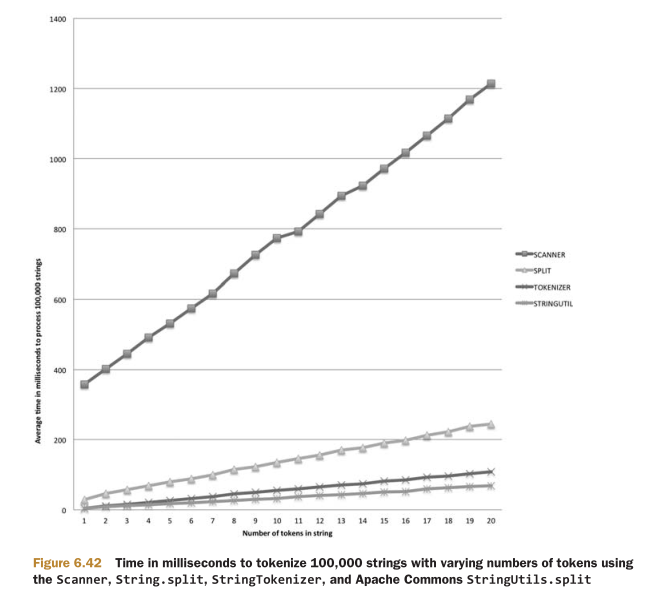
这个性能测试是在如下环境中完成:JDK 1.6.0_29,OS X,四核2.7GHz CPU。
对象重用
第二个消耗CPU时间的是类似如下的代码:
Text outputValue = new Text(parts[0]);
由于这段代码在每个键值对都要执行一次,就要执行成千上万次。代码就会在对象分配上浪费大量的时间。对象分配在JAVA中是非常昂贵的,包含创建时调用CPU,销毁时调用垃圾收集器。如果能够重用,将节约大量的时间。以下代码介绍如何达到最大重用率:
Text outputValue = new Text(); public void map(LongWritable key, Text value,
OutputCollector<LongWritable, Text> output,
Reporter reporter) throws IOException {
String[] parts = StringUtils.split(value.toString(), "."));
outputValue.set(parts[0]);
output.collect(key, outputValue);
}
在Hadoop中,当reduce将数据填充到值迭代器的时候,应用了对象重用。这个特性对缓存机制有潜在影响。在reduce中缓存值对象的数据的时候,需要克隆这个对象。实现代码如下:
public static class Reduce extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
List<Text> cached = new ArrayList<Text>();
for (Text value : values) {
cached.add(WritableUtils.clone(value, context.getConfiguration()));
}
}
}
字符串连接
JAVA中有一个非常古老的规则,就是应当避免使用加号来进行字符串连接。代码如下:
String results = a + b;
用加号连接字符串需要调用StringBuffer类。StringBuffer类是同步类,会降低执行的效能。近来,加号连接字符串有的情况下会调用StringBuilder类,一个非同步类。但这并不代表加号可以放心使用。当字符串长度大于16的时候,就很难说。具体参考http://goo.gl/9NGe8。最安全的方法就是使用StringBuilder类,并预先分配足够的空间,以防空间不足导致的空间再分配。
对象的内存资源消耗
在map和reduce任务中,常常需要缓存数据,例如第4章中的map端连接技术。然而,在JAVA中缓存数据成本高昂。首先来了解一下字符类和数组的内存资源消耗情况。预估一下下面这段代码的资源消耗。
ArrayList<String> strings = new ArrayList<String>();
strings.add("a");
string.add("b");
以下是对字符串数组列表的内存资源消耗的计算:
- 每个JAVA对象占用8字节作为基础开支。数组列表对象最开始申请8个字节。
- 数组列表对象包括一个整形原始字段占用4个字节。
- 数组列表使用对象数组存储数据。每个引用字段占用4字节。
- 每个对象占用内存字节数必须是8的倍数。以上内存占用总计为16字节。不需要凑整。
在没有存储任何数据的时候,数组列表已经占用了24字节。
接下来看数组列表中的对象数组的内存占用。
- 一个数组需要12字节作为基础开支。在8个字节外,它还需要4字节来存储数组的大小。
- 数组中的每个元素需要4字节来存储对象引用。两个元素一共8字节。
- 因为每个对象的内存字节数必须是8的倍数。上述字节数之和为20,凑整得到24。
那么现在数组列表占24字节,对象数组站24字节。最后需要理解字符串的内存占用,如下所示:
字符串内存占用字节数=(字符个数x2)+38
同样需要去整得到8的倍数。那么每个字符串占用40字节。最后存储了两个字符串的数组列表的内存占用是128字节。
这里进行这么详细计算的目的是建立对在JAVA中缓存数据的敏感性。在MapReduce中也一样,能够精确计算需要缓存数据的内存消耗是非常有益的。JAVA的内存使用详情可见:http://goo.gl/V8sZi。
[大牛翻译系列]Hadoop(15)MapReduce 性能调优:优化MapReduce的用户JAVA代码的更多相关文章
- [大牛翻译系列]Hadoop 翻译文章索引
原书章节 原书章节题目 翻译文章序号 翻译文章题目 链接 4.1 Joining Hadoop(1) MapReduce 连接:重分区连接(Repartition join) http://www.c ...
- 【Xamarin挖墙脚系列:应用的性能调优】
原文:[Xamarin挖墙脚系列:应用的性能调优] 官方提供的工具:网盘地址:http://pan.baidu.com/s/1pKgrsrp 官方下载地址:https://download.xamar ...
- [大牛翻译系列]Hadoop(16)MapReduce 性能调优:优化数据序列化
6.4.6 优化数据序列化 如何存储和传输数据对性能有很大的影响.在这部分将介绍数据序列化的最佳实践,从Hadoop中榨出最大的性能. 压缩压缩是Hadoop优化的重要部分.通过压缩可以减少作业输出数 ...
- [大牛翻译系列]Hadoop(8)MapReduce 性能调优:性能测量(Measuring)
6.1 测量MapReduce和环境的性能指标 性能调优的基础系统的性能指标和实验数据.依据这些指标和数据,才能找到系统的性能瓶颈.性能指标和实验数据要通过一系列的工具和过程才能得到. 这部分里,将介 ...
- [大牛翻译系列]Hadoop(11)MapReduce 性能调优:诊断一般性能瓶颈
6.2.4 任务一般性能问题 这部分将介绍那些对map和reduce任务都有影响的性能问题. 技术37 作业竞争和调度器限制 即便map任务和reduce任务都进行了调优,但整个作业仍然会因为环境原因 ...
- [大牛翻译系列]Hadoop(19)MapReduce 文件处理:基于压缩的高效存储(二)
5.2 基于压缩的高效存储(续) (仅包括技术27) 技术27 在MapReduce,Hive和Pig中使用可分块的LZOP 如果一个文本文件即使经过压缩后仍然比HDFS的块的大小要大,就需要考虑选择 ...
- [大牛翻译系列]Hadoop(17)MapReduce 文件处理:小文件
5.1 小文件 大数据这个概念似乎意味着处理GB级乃至更大的文件.实际上大数据可以是大量的小文件.比如说,日志文件通常增长到MB级时就会存档.这一节中将介绍在HDFS中有效地处理小文件的技术. 技术2 ...
- [大牛翻译系列]Hadoop(20)附录A.10 压缩格式LZOP编译安装配置
附录A.10 LZOP LZOP是一种压缩解码器,在MapReduce中可以支持可分块的压缩.第5章中有一节介绍了如何应用LZOP.在这一节中,将介绍如何编译LZOP,在集群做相应配置. A.10.1 ...
- [大牛翻译系列]Hadoop(21)附录D.1 优化后的重分区框架
附录D.1 优化后的重分区框架 Hadoop社区连接包需要将每个键的所有值都读取到内存中.如何才能在reduce端的连接减少内存开销呢?本文提供的优化中,只需要缓存较小的数据集,然后在连接中遍历较大数 ...
随机推荐
- web开发下的各种下载方法
利用TransmitFile方法,解决Response.BinaryWrite下载超过400mb的文件时导致Aspnet_wp.exe进程回收而无法成功下载的问题. 代码如下: Response.Co ...
- C# 读取与修改配置文件
System.Configuration.ConfigurationSettings.AppSettings["Key"]; 但是现在FrameWork2.0已经明确表示此属性已经 ...
- Subsequence poj 3061 二分(nlog n)或尺取法(n)
Subsequence Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 9236 Accepted: 3701 Descr ...
- [JavaEE] WEB-INF有关的目录路径总结
1.资源文件只能放在WebContent下面,如 CSS,JS,image等.放在WEB-INF下引用不了. 2.页面放在WEB-INF目录下面,这样可以限制访问,提高安全性.如JSP,html 3. ...
- iOS - UI - UITableView
1.UITableView 表格视图 服从数据源 - (UIView *)tableView:(UITableView *)tableView viewForHeaderInSection:(NSIn ...
- 解决xcode7添加启动图片不显示
xcode7添加启动图片步骤: 在target中将Launch Screen File置为空,不使用自带的LaunchScreen.storyboard作为启动图(LaunchScreen.story ...
- mysql优化方法
1.选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快.因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽 ...
- 写多个物件css3循环动画案例原理
div { background-color: #67CF22; height: 100%; width: 6px; display: inline-block; -webkit-animation: ...
- javascript触摸事件touch使用
详细内容请点击 Apple在iOS 2.0中引入了触摸事件API,Android正迎头赶上这一事实标准,缩小差距.最近一个W3C工作组正合力制定这一触摸事件规范. 在本文深入研究iOS和 ...
- Java之循环练习2
吐槽O(∩_∩)O:由于前几天电脑坏了,除了在弄电脑的同时又在练习科目三了,又是晒了三天网鱼都没打了.计划还是赶不上变化,真的是让人乱了节拍啊.咔!吐槽完毕,让我们的循环练习继续. 练习一:一个人很倒 ...