决策树--信息增益,信息增益比,Geni指数的理解
- 特征选择
- 决策树生成
- 决策树剪枝
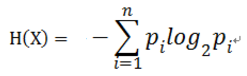
对于样本集合D来说,随机变量X是样本的类别,即,假设样本有k个类别,每个类别的概率是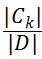 ,其中|Ck|表示类别k的样本个数,|D|表示样本总数
,其中|Ck|表示类别k的样本个数,|D|表示样本总数
则对于样本集合D来说熵(经验熵)为:
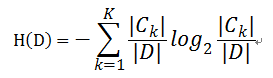
- 信息增益( ID3算法 )
定义: 以某特征划分数据集前后的熵的差值
在熵的理解那部分提到了,熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大。因此可以使用划分前后集合熵的差值来衡量使用当前特征对于样本集合D划分效果的好坏。
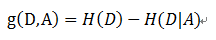
- 解决方法 : 信息增益比( C4.5算法 )
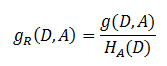
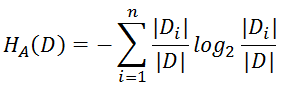
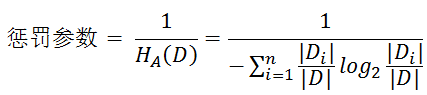
- 基尼指数( CART算法 ---分类树)
定义:基尼指数(基尼不纯度):表示在样本集合中一个随机选中的样本被分错的概率。
注意: Gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。
即 基尼指数(基尼不纯度)= 样本被选中的概率 * 样本被分错的概率
书中公式:
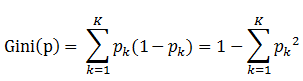
说明:
1. pk表示选中的样本属于k类别的概率,则这个样本被分错的概率是(1-pk)
2. 样本集合中有K个类别,一个随机选中的样本可以属于这k个类别中的任意一个,因而对类别就加和
3. 当为二分类是,Gini(P) = 2p(1-p)
样本集合D的Gini指数 : 假设集合中有K个类别,则:
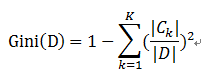
基于特征A划分样本集合D之后的基尼指数:
需要说明的是CART是个二叉树,也就是当使用某个特征划分样本集合只有两个集合:1. 等于给定的特征值 的样本集合D1 , 2 不等于给定的特征值 的样本集合D2
实际上是对拥有多个取值的特征的二值处理。
举个例子:
假设现在有特征 “学历”,此特征有三个特征取值: “本科”,“硕士”, “博士”,
当使用“学历”这个特征对样本集合D进行划分时,划分值分别有三个,因而有三种划分的可能集合,划分后的子集如下:
- 划分点: “本科”,划分后的子集合 : {本科},{硕士,博士}
- 划分点: “硕士”,划分后的子集合 : {硕士},{本科,博士}
- 划分点: “硕士”,划分后的子集合 : {博士},{本科,硕士}
对于上述的每一种划分,都可以计算出基于 划分特征= 某个特征值 将样本集合D划分为两个子集的纯度:
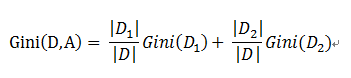
因而对于一个具有多个取值(超过2个)的特征,需要计算以每一个取值作为划分点,对样本D划分之后子集的纯度Gini(D,Ai),(其中Ai 表示特征A的可能取值)
然后从所有的可能划分的Gini(D,Ai)中找出Gini指数最小的划分,这个划分的划分点,便是使用特征A对样本集合D进行划分的最佳划分点。
决策树--信息增益,信息增益比,Geni指数的理解的更多相关文章
- python实现简单决策树(信息增益)——基于周志华的西瓜书数据
数据集如下: 色泽 根蒂 敲声 纹理 脐部 触感 好瓜 青绿 蜷缩 浊响 清晰 凹陷 硬滑 是 乌黑 蜷缩 沉闷 清晰 凹陷 硬滑 是 乌黑 蜷缩 浊响 清晰 凹陷 硬滑 是 青绿 蜷缩 沉闷 清晰 ...
- 《机器学习实战》学习笔记第三章 —— 决策树之ID3、C4.5算法
主要内容: 一.决策树模型 二.信息与熵 三.信息增益与ID3算法 四.信息增益比与C4.5算法 五.决策树的剪枝 一.决策树模型 1.所谓决策树,就是根据实例的特征对实例进行划分的树形结构.其中有两 ...
- 决策树与树集成模型(bootstrap, 决策树(信息熵,信息增益, 信息增益率, 基尼系数),回归树, Bagging, 随机森林, Boosting, Adaboost, GBDT, XGboost)
1.bootstrap 在原始数据的范围内作有放回的再抽样M个, 样本容量仍为n,原始数据中每个观察单位每次被抽到的概率相等, 为1/n , 所得样本称为Bootstrap样本.于是可得到参数θ的 ...
- [机器学习]信息&熵&信息增益
关于对信息.熵.信息增益是信息论里的概念,是对数据处理的量化,这几个概念主要是在决策树里用到的概念,因为在利用特征来分类的时候会对特征选取顺序的选择,这几个概念比较抽象,我也花了好长时间去理解(自己认 ...
- 决策树-预测隐形眼镜类型 (ID3算法,C4.5算法,CART算法,GINI指数,剪枝,随机森林)
1. 1.问题的引入 2.一个实例 3.基本概念 4.ID3 5.C4.5 6.CART 7.随机森林 2. 我们应该设计什么的算法,使得计算机对贷款申请人员的申请信息自动进行分类,以决定能否贷款? ...
- 【Machine Learning】决策树案例:基于python的商品购买能力预测系统
决策树在商品购买能力预测案例中的算法实现 作者:白宁超 2016年12月24日22:05:42 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本 ...
- 决策树和基于决策树的集成方法(DT,RF,GBDT,XGBT)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 内容: 1.算法概述 1.1 决策树(DT)是一种基本的分类和回归方法.在分类问题中它可以认为是if-the ...
- 决策树模型 ID3/C4.5/CART算法比较
决策树模型在监督学习中非常常见,可用于分类(二分类.多分类)和回归.虽然将多棵弱决策树的Bagging.Random Forest.Boosting等tree ensembel 模型更为常见,但是“完 ...
- 决策树和基于决策树的集成方法(DT,RF,GBDT,XGB)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 内容: 1.算法概述 1.1 决策树(DT)是一种基本的分类和回归方法.在分类问题中它可以认为是if-the ...
随机推荐
- JAVA链表中迭代器的实现
注:本文代码出自<java数据结构和算法>一书. PS:本文中类的名字定义存在问题,Link9应改为Link.LinkList9应该为LinkList.由于在同包下存在该名称,所以在后面接 ...
- github使用心得和链接
在本次使用github过程中,刚打开github主界面的时候,吓了一跳,满眼的英文加上各种没用过的命令,真是一个头两个大,废话不多说,下面我就说一下我在使用github过程中遇到的两个问题.: 问题一 ...
- 13.14.15.16.17&《一个程序猿的生命周期》读后感
13.TDS 的标准是什么,怎么样才能认为他是一个标准的TDS?? 14.软件的质量包括哪些方面,如何权衡软件的质量? 15.如何解决功能与时间的矛盾,优秀的软件团队会发布有已知缺陷的软件么? 16. ...
- JAVA中方法和变量在继承中的覆盖和隐藏
出处:http://renyanwei.iteye.com/blog/258304 我们知道,在JAVA中,子类可以继承父类,如果子类声明的方法与父类有重名的情况怎么办,大伙儿都知道要是重写,但是实际 ...
- Vim列模式(块选择)输入
https://www.ibm.com/developerworks/cn/linux/l-cn-vimcolumn/ https://www.zhihu.com/question/19968224 ...
- Spring事务银行转账示例
https://www.imooc.com/video/9331 声明式事务 @Transactiona() 编程式事务 非模板式(不使用TransactionTemplate) http://cai ...
- python3_字符串
一.字符串的表示 >>> s = "narjaja never give up" #字符串的创建和初始化 >>> s = 'narjaja ne ...
- Python装饰器的深入理解
装饰器 #装饰器:本质上是函数,(装饰其他函数)就是为其他函数添加附加功能 #原则: 1.不能修改被装饰的函数的源代码 # 2.不能修改被装饰的函数的调用方式 #实现装饰器知识储备 #1.函数即变量 ...
- 睡前小dp-poj1276-多重背包+二进制优化
http://poj.org/problem?id=1276 简单的多重背包,不过需要优化一下才能过.网上还有暴力的做法. 二进制优化在背包九讲里讲的比较清楚.对于多重背包的每一件物品,使用二进制的形 ...
- ASP.NET MVC5使用Area区域
转载:http://www.lanhusoft.com/Article/217.html 在大型的ASP.NET mvc5项目中一般都有许多个功能模块,这些功能模块可以用Area(中文翻译为区域)把它 ...