决策树--信息增益,信息增益比,Geni指数的理解
- 特征选择
- 决策树生成
- 决策树剪枝
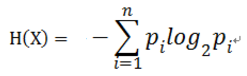
对于样本集合D来说,随机变量X是样本的类别,即,假设样本有k个类别,每个类别的概率是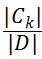 ,其中|Ck|表示类别k的样本个数,|D|表示样本总数
,其中|Ck|表示类别k的样本个数,|D|表示样本总数
则对于样本集合D来说熵(经验熵)为:
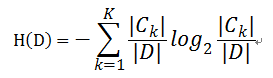
- 信息增益( ID3算法 )
定义: 以某特征划分数据集前后的熵的差值
在熵的理解那部分提到了,熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大。因此可以使用划分前后集合熵的差值来衡量使用当前特征对于样本集合D划分效果的好坏。
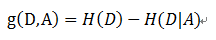
- 解决方法 : 信息增益比( C4.5算法 )
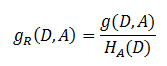
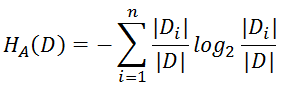
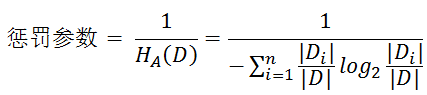
- 基尼指数( CART算法 ---分类树)
定义:基尼指数(基尼不纯度):表示在样本集合中一个随机选中的样本被分错的概率。
注意: Gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。
即 基尼指数(基尼不纯度)= 样本被选中的概率 * 样本被分错的概率
书中公式:
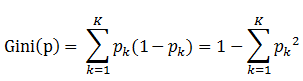
说明:
1. pk表示选中的样本属于k类别的概率,则这个样本被分错的概率是(1-pk)
2. 样本集合中有K个类别,一个随机选中的样本可以属于这k个类别中的任意一个,因而对类别就加和
3. 当为二分类是,Gini(P) = 2p(1-p)
样本集合D的Gini指数 : 假设集合中有K个类别,则:
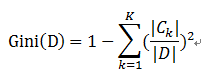
基于特征A划分样本集合D之后的基尼指数:
需要说明的是CART是个二叉树,也就是当使用某个特征划分样本集合只有两个集合:1. 等于给定的特征值 的样本集合D1 , 2 不等于给定的特征值 的样本集合D2
实际上是对拥有多个取值的特征的二值处理。
举个例子:
假设现在有特征 “学历”,此特征有三个特征取值: “本科”,“硕士”, “博士”,
当使用“学历”这个特征对样本集合D进行划分时,划分值分别有三个,因而有三种划分的可能集合,划分后的子集如下:
- 划分点: “本科”,划分后的子集合 : {本科},{硕士,博士}
- 划分点: “硕士”,划分后的子集合 : {硕士},{本科,博士}
- 划分点: “硕士”,划分后的子集合 : {博士},{本科,硕士}
对于上述的每一种划分,都可以计算出基于 划分特征= 某个特征值 将样本集合D划分为两个子集的纯度:
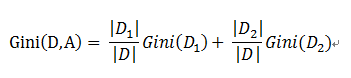
因而对于一个具有多个取值(超过2个)的特征,需要计算以每一个取值作为划分点,对样本D划分之后子集的纯度Gini(D,Ai),(其中Ai 表示特征A的可能取值)
然后从所有的可能划分的Gini(D,Ai)中找出Gini指数最小的划分,这个划分的划分点,便是使用特征A对样本集合D进行划分的最佳划分点。
决策树--信息增益,信息增益比,Geni指数的理解的更多相关文章
- python实现简单决策树(信息增益)——基于周志华的西瓜书数据
数据集如下: 色泽 根蒂 敲声 纹理 脐部 触感 好瓜 青绿 蜷缩 浊响 清晰 凹陷 硬滑 是 乌黑 蜷缩 沉闷 清晰 凹陷 硬滑 是 乌黑 蜷缩 浊响 清晰 凹陷 硬滑 是 青绿 蜷缩 沉闷 清晰 ...
- 《机器学习实战》学习笔记第三章 —— 决策树之ID3、C4.5算法
主要内容: 一.决策树模型 二.信息与熵 三.信息增益与ID3算法 四.信息增益比与C4.5算法 五.决策树的剪枝 一.决策树模型 1.所谓决策树,就是根据实例的特征对实例进行划分的树形结构.其中有两 ...
- 决策树与树集成模型(bootstrap, 决策树(信息熵,信息增益, 信息增益率, 基尼系数),回归树, Bagging, 随机森林, Boosting, Adaboost, GBDT, XGboost)
1.bootstrap 在原始数据的范围内作有放回的再抽样M个, 样本容量仍为n,原始数据中每个观察单位每次被抽到的概率相等, 为1/n , 所得样本称为Bootstrap样本.于是可得到参数θ的 ...
- [机器学习]信息&熵&信息增益
关于对信息.熵.信息增益是信息论里的概念,是对数据处理的量化,这几个概念主要是在决策树里用到的概念,因为在利用特征来分类的时候会对特征选取顺序的选择,这几个概念比较抽象,我也花了好长时间去理解(自己认 ...
- 决策树-预测隐形眼镜类型 (ID3算法,C4.5算法,CART算法,GINI指数,剪枝,随机森林)
1. 1.问题的引入 2.一个实例 3.基本概念 4.ID3 5.C4.5 6.CART 7.随机森林 2. 我们应该设计什么的算法,使得计算机对贷款申请人员的申请信息自动进行分类,以决定能否贷款? ...
- 【Machine Learning】决策树案例:基于python的商品购买能力预测系统
决策树在商品购买能力预测案例中的算法实现 作者:白宁超 2016年12月24日22:05:42 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本 ...
- 决策树和基于决策树的集成方法(DT,RF,GBDT,XGBT)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 内容: 1.算法概述 1.1 决策树(DT)是一种基本的分类和回归方法.在分类问题中它可以认为是if-the ...
- 决策树模型 ID3/C4.5/CART算法比较
决策树模型在监督学习中非常常见,可用于分类(二分类.多分类)和回归.虽然将多棵弱决策树的Bagging.Random Forest.Boosting等tree ensembel 模型更为常见,但是“完 ...
- 决策树和基于决策树的集成方法(DT,RF,GBDT,XGB)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 内容: 1.算法概述 1.1 决策树(DT)是一种基本的分类和回归方法.在分类问题中它可以认为是if-the ...
随机推荐
- 个人作业——final
一 . 对M1M2的一个总结 我特别感谢我们组的PM.以前我觉得女生学计算机这个专业,跟男生比差太远了.总觉得我们女生就是上上课写写作业考考试还行,但是一到开发什么项目啊,实战之类的,总觉得自己的能力 ...
- 《linux内核设计与实现》第五章
第五章 系统调用 一.与内核通信 系统调用在用户空间进程和硬件设备之间添加了一个中间层.作用: 为用户空间提供了一种硬件的抽象接口. 系统调用保证了系统的稳定和安全. 每个进程都运行在虚拟系统中,而在 ...
- Linux内核读书笔记第三周 调试
内核调试的难点在于它不能像用户态程序调试那样打断点,随时暂停查看各个变量的状态. 也不能像用户态程序那样崩溃后迅速的重启,恢复初始状态. 用户态程序和内核交互,用户态程序的各种状态,错误等可以由内核来 ...
- 自己搭建的一个react脚手架
包括了: react.react router(v4), webpack(v4),echarts, google的组件库material ui, 后期会加上redux但是这些做中小型系统已经够了,de ...
- MyBatis中if,where,set标签
<if>标签 <select id="findActiveBlogWithTitleLike" resultType="Blog"> S ...
- 小学四则运算APP 第二阶段冲刺-第三天
团队成员:陈淑筠.杨家安.陈曦 团队选题:小学四则运算APP 第二次冲刺阶段时间:11.29~12.09 本次发布的是判断题的部分代码 panduanset.java import com.examp ...
- 自己实现数据结构系列二---LinkedList
一.先上代码: 1.方式一: public class LinkedList<E> { //节点,用来存放数据:数据+下一个元素的引用 private class Node{ privat ...
- [自学]Docker system 命令 查看docker镜像磁盘占用情况 Docker volume 相关
内容From https://docs.docker.com/engine/reference/commandline/system_df/ docker的image和docker的container ...
- Qt__CMakeLists.txt
cmake_minimum_required(VERSION 3.1.0) project (Project) if(CMAKE_COMPILER_IS_GNUCC) set(CMAKE_CXX_FL ...
- PP模块的主要功能及标准业务流程
主要功能:1.SOP (Sales and operations Planning).2.资源分配计划划 (Distribution Resource Planning)3.生产计划编制 (Produ ...