★Pandas 零碎知识
1 修改属性
1.1 修改1列的类型属性:
df['总金额'] = pd.to_numeric(df['总金额']) #转变dataframe的1列为数值型
1.2 多列设为数值型:(使用DataFrame.apply处理每一列)
df[['col2','col3']] = df[['col2','col3']].apply(pd.to_numeric)
多列格式指定为字符串型式:
df[['首封', '终封']] = df[['首封', '终封']].astype(str)
打开文件时,指定某列为字符型:
df = pd.DataFrame(pd.read_excel('短线宝.xls',converters={'代码':str}))
指定多列为字符型:
df = pd.DataFrame(pd.read_excel('短线宝.xls',converters={'代码':str,'上市天数':str}))
将所有数据转换为字符串:
dataframe=dataframe.astype(str)
将多列分别指定类型:
data = data.astype({'outcome':'float','age':'int'})
1.3 整个DataFrame设为数值型:
df.apply(pd.to_numeric, errors='ignore') #可以转换为数字类型的列将被转换,而不能(例如,它们包含非数字字符串或日期)的列将被单独保留。
2 修改某列数值:
df['流通市值'] = round(df['流通市值']/100000000,2)
3 dataframe数据筛选后求和:
df1 = df[(df['age']>10) & (df['age']<30)]['profit'].sum()
4 直接指定各列名称:
df.columns = ['股票简称','涨幅%','股票代码','现价'...]
5 改变列顺序:
order = ['股票代码','股票简称',....'] df = df[order]
6 删除指定多列:
x = [4,7,10,11,12,13,15] #列的序号,从0开始 df.drop(df.columns[x], axis=1, inplace=True)
7 总行数、总列数:
Rows = df.shape[0] #行数Cols = df.shape[1] #列数
8 求某列最大值:
df_max = max(df['连板'])
9 去除1列中的空格:
df['流通市值'] = df['流通市值'].str.strip(); #去除1列中的空格
10 将list类型转换为string类型:
text= ' '.join(map(str,list))
11 数值修改及替换
Python中使用replace函数实现数据替换。
数据表中city字段上海存在两种写法,分别为shanghai和SH。
我们使用replace函数对SH进行替换。
df['city'].replace('SH', 'shanghai')
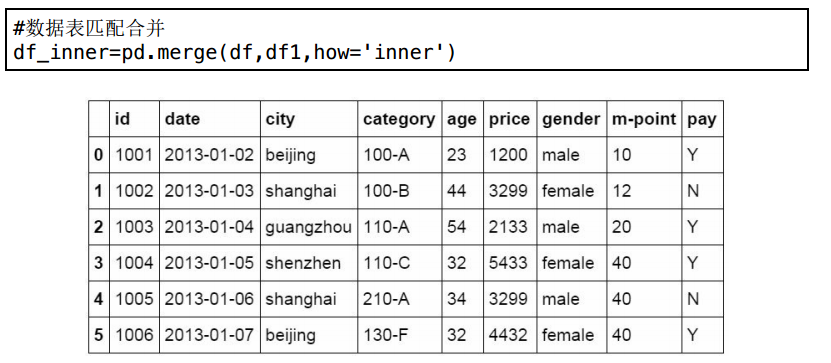
12 数据表合并
首先是对不同的数据表进行合并,我们这里创建一个新的数据表df1,并将df和df1两个数据表进行合并。
在Python中可以通过merge函数一次性实现。
下面建立df1数据表,用于和df数据表进行合并。

使用merge函数对两个数据表进行合并,合并的方式为inner,将两个数据表中共有的数据匹配到一起生成新的数据表。并命名为df_inner。
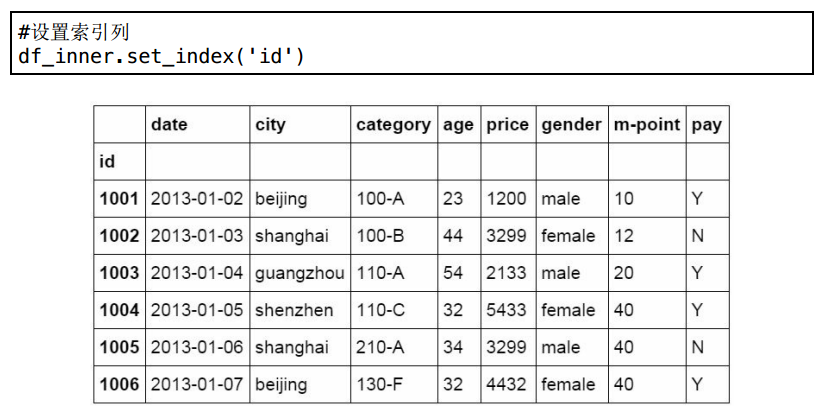
13 设置索引列
完成数据表的合并后,我们对df_inner数据表设置索引列,索引列的功能很多,可以进行数据提取,汇总,也可以进行数据筛选等。
设置索引的函数为set_index.
14 删除某列包含特定字符的行
(为防止该列某行为空值而报错,应先填充,再一并删除)
#先填充空值行,为方便一并删除,填上'STST'
df['名称'].isnull().value_counts() #先查找
df['名称'] = df['名称'].fillna('STST') #再填充
#再去除STdf_ST = df[df['名称'].str.contains("ST")] #含有特定字符的行
df = df[-df['名称'].str.contains("ST")] #去除特定字符的行以后的新数据
删除某列的特定字符串:
df['短线主题'] = df['短线主题'].str.replace('概念','')
15 向DataFrame添加数据
df = df.append(df1) #添加
16 统计一共有多少种
con_num = len(set(df['概念板块'])) #统计“概念板块”这1列一共有多少种概念。
17 设备索引字段
df = df.set_index('member_id')
18 两列合并,且添加分隔符
df['概念'] = df['概念板块'].str.cat(df['所属概念'],sep=';')
多列合并:
df['address'] = df['country']+df['province']+df['city']
如果某一列是非str类型的数据,那么我们需要用到map(str)将那一列数据类型做转换:
df["newColumn"] = df["age"].map(str) + df["phone"] + df["address”]
19 从一个Dataframe中减去一部分
df3 = df1.drop(labels=df2.axes[0]) #df2是df1的子集
20 指定列去重
df = df.drop_duplicates(['板块'])
21 一列合并为一个文本
text= ("".join(i for i in df['所属概念']))
22 去掉列首、尾数字
#去掉首位数字——只去掉1位
df['涨停原因'] = df['涨停原因'].str.replace('^[0-9]','')
#去掉末位数字
df['涨停原因'] = df['涨停原因'].str.replace('[0-9]$','')
★Pandas 零碎知识的更多相关文章
- 【Python】 零碎知识积累 II
[Python] 零碎知识积累 II ■ 函数的参数默认值在函数定义时确定并保存在内存中,调用函数时不会在内存中新开辟一块空间然后用参数默认值重新赋值,而是单纯地引用这个参数原来的地址.这就带来了一个 ...
- 【Python】 零碎知识积累 I
大概也是出于初高中时学化学,积累各种反应和物质的习惯,还有大学学各种外语时一看见不认识的词就马上记下来的习惯,形成了一种能记一点是一点的零碎知识记录的癖好.这篇文章就是专门拿来记录这些零碎知识的,没事 ...
- Python数据分析与挖掘所需的Pandas常用知识
Python数据分析与挖掘所需的Pandas常用知识 前言Pandas基于两种数据类型:series与dataframe.一个series是一个一维的数据类型,其中每一个元素都有一个标签.series ...
- php获取服务器信息常用方法(零碎知识记忆)
突然整理下零碎小知识.......加深下印象: $info = array( '操作系统'=>PHP_OS, '运行环境'=>$_SERVER["SERVER_SOFTWARE& ...
- Pandas基础知识图谱
所有内容整理自<利用Python进行数据分析>,使用MindMaster Pro 7.3制作,emmx格式,源文件已经上传Github,需要的同学转左上角自行下载或者右击保存图片.该图谱只 ...
- Spring零碎知识复习
自学了Spring也有一段时间了,多多少少掌握了一些Spring的知识,现在手上也没有很多的项目练手,就将就着把这些学到的东西先收集起来,方便日后用到的时候没地方找. 1.spring的国际化 主要是 ...
- 有关Spring注解@xxx的零碎知识
在Java的Spring开发中经常使用一些注解,例如 @XXX 等等,在网上看到收集整理碎片知识,便于懒人计划^=^... 过去,Spring使用的Java Bean对象必须在配置文件[一般为a ...
- 第二节 pandas 基础知识
pandas 两种数据结构 Series和DataFrame 一 Series 一种类似与一维数组的对象 values:一组数据(ndarray类型) index:相关的数据索引标签 1.1 se ...
- Pandas基础知识(二)
Pandas的索引对象 index的对象是不可以修改的如执行index[1] = 'f',会报错"Index does not support mutable operations" ...
随机推荐
- 【Zookeeper系列】ZooKeeper一致性原理(转)
原文链接:https://www.cnblogs.com/sunddenly/p/4138580.html 一.ZooKeeper 的实现 1.1 ZooKeeper处理单点故障 我们知道可以通过Zo ...
- TensorFlow环境 人脸识别 FaceNet 应用(一)验证测试集
TensorFlow环境 人脸识别 FaceNet 应用(一)验证测试集 前提是TensorFlow环境以及相关的依赖环境已经安装,可以正常运行. 一.下载FaceNet源代码工程 git clone ...
- meat标签
1.文档兼容模式的定义 Edge 模式告诉 IE 以最高级模式渲染文档,也就是任何 IE 版本都以当前版本所支持的最高级标准模式渲染,避免版本升级造成的影响.简单的说,就是什么版本 IE 就用什么版本 ...
- linux命令sync,shutdown
1.数据同步写入磁盘: sync 输入sync,那举在内存中尚未被更新的数据,就会被写入硬盘中 hling@hling:~$ sync 2.惯用的关机指令:shutdown 实例:
- css的小知识
---恢复内容开始--- 1.当你发现在制作页面时出现滚动条就需要一个去除滚动条的属性 overflow:hidden: overflow-x:hidden:水平超出隐藏 2. ...
- python语法_字符类型
str(string): 字符串 str(被转换的数据) int(interger):整数 int(被转换的数据)
- 转载http协议
转载自:https://blog.csdn.net/weixin_38051694/article/details/77777010 1.说一下什么是Http协议 对器客户端和 服务器端之间数据传输的 ...
- SpringMVC访问静态资源的三种方式
如何你的DispatcherServlet拦截 *.do这样的URL,就不存在访问不到静态资源的问题.如果你的DispatcherServlet拦截“/”,拦截了所有的请求,同时对*.js,*.jpg ...
- 使用docker容器运行MySQL数据库并持久化数据文件
1.下载mysql镜像 # docker pull mysql 2.启动mysql容器 # docker run -itd -v /data:/var/lib/mysql -p 33060:3306 ...
- 【ArcGIS for Server】制作并发布GP服务--缓冲分析为例
https://www.cnblogs.com/d2ee/p/3641279.html https://www.jianshu.com/p/5331fa708fe5 https://www.cnblo ...