大数据 Spark 架构
一.Spark的产生背景起源
1.spark特点
1.1轻量级快速处理
Saprk允许传统的hadoop集群中的应用程序在内存中已100倍的速度运行即使在磁盘上也比传统的hadoop快10倍,Spark通过减少对磁盘的io达到性能上的提升,他将中间处理的数据放到内存中,spark使用了rdd(resilient distributed datasets)数据抽象
这允许他在内存中存储数据,所以减少了运行时间
1.2 易于使用
spark支持多种语言。Spark允许java,scala python 及R语言,允许shell进行交互式查询
1.3 支持复杂的查询
除了简单的map和reduce操作之外,Spark还支持filter、foreach、reduceByKey、aggregate以及SQL查询、流式查询等复杂查询。Spark更为强大之处是用户可以在同一个工作流中无缝的搭配这些功能,例如Spark可以通过Spark Streaming(1.2.2小节对Spark Streaming有详细介绍)获取流数据,然后对数据进行实时SQL查询或使用MLlib库进行系统推荐,而且这些复杂业务的集成并不复杂,因为它们都基于RDD这一抽象数据集在不同业务过程中进行转换,转换代价小,体现了统一引擎解决不同类型工作场景的特点。
1.4 实时的流处理
对比maprduce只能处理离线数据。Spark还能支持实时的流计算,spark streaming 主要用来对数据进行实时的处理,yarn的nodemanger统一调度管理很厉害,在yarn产生后hadoop也可以整合资源进行实时的处理
2.时事产物
2.1 mapreduce产生时磁盘廉价,因此许多设计收回考虑到内存的使用,而spark产生时内存相对廉价,对计算速度有所要求,因此spark的产生是基于内存计算的框架结构mapreduce需要写复杂的程序进行计算,
二.Spark架构
1.spark的体系结构
Spark的体系结构不同于Hadoop的mapreduce 和HDFS ,Spark主要包括spark core和在spark core的基础上建立的应用框架sparkSql spark Streaming MLlib GraphX;
Core库主要包括上下文(spark Context)抽象的数据集(RDD),调度器(Scheduler),洗牌(shuffle) 和序列化器(Seralizer)等。Spark系统中的计算,IO,调度和shuffle等系统的基本功能都在其中
在Core库之上就根据业务需求分为用于交互式查询的SQL、实时流处理Streaming、机器学习Mllib和图计算GraphX四大框架hdfs迄今是不可替代的
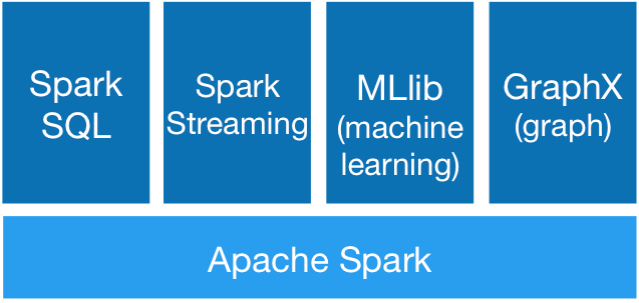
Spark架构组成图

一.Hive和spark对sql支持的对比
Hive创建数据库 创建表 true
|
验证策略 |
脚本 |
Hive |
Spark-sql |
|
创建库 删除库 |
Create database lvhou_hive Create database lvhou_spark Dorp database lvhou_hive Dorp database lvhou_spark |
True |
True |
|
创建表 删除表 |
Use lvhou_hive Create table hive_test(a string,b string) Use lvhou_spark Create table spark_test(a string,b string) Drop table hive_test Drop table spark_test |
True |
True |
|
CTAS |
Create table lvhou_test as selec * from lvhou_test1; |
true |
false |
|
Insert |
Insert into lvhou_hive values(‘hhah’,’heheh’) |
true |
false |
|
insert |
Insert into lvhou_spark value(‘12’.’32’),(‘asd’,’asdf’) |
True |
false |
|
Select |
Select * from lvhou_hive Select * from lvhou_spark |
True |
True |
|
Select in |
|||
|
Select子查询 in 两条数据 not in 两条数据 |
select * from test1 where a,b in (select a,b from test2 where a = 'aa'); select * from test1 where a,b not in (select a,b from test2 where a = 'aa'); |
falese |
false |
|
Select union查询 union all |
select * from test union all select * from test0;(合一) select * from test union select * from test0;(去重) |
true |
false |
|
Select union 3查询 union all |
select * from (select * from test union select * from test0) a; select a from (select * from test union all select * from test0) a; |
false |
False |
|
Select exit not exit |
select * from test t where exists(select * from test0 t0 where t0.a = t.a); select * from lv_test where exists(select * tfrom test t where lv_test.a = t.a); |
True |
False |
|
update |
update test1 set b = 'abc' where a = 'aa'; update test1 set a = 'abc'; Update test1 set b = 'abc'; |
True |
False |
|
delete |
delete from test1 where a = 'aa'; delete from test1; |
True |
False |
|
TRUNCATE TABLE |
Truncate table test; |
True |
False |
|
Alter |
alter table test1 add columns (d string); alter table test drop a; alter table test rename a to a1; |
True |
False |
|
索引 |
create index index_a on table test(a) as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild; |
True |
False |
|
INTERSECT 交集 |
select a from test INTERSECT select a from test0; |
False |
False |
|
EXCEPT |
select a from test EXCPEPT select a from test0; |
False |
False |
|
Minus 返回第一个结果中不同的 |
select a from test minus select a from test0; |
False |
False |
|
order by 排序 |
select a from test order by a desc; |
True |
False |
|
sort by 排序 |
select a,b from test sort by b desc; |
True |
False |
|
distribute by |
select a,b from test distribute by a; |
True |
False |
|
distribute by + sort by |
select a,b from test distribute by a sort by b asc; |
True |
False |
|
cluster by |
select a,b from test cluster by a; |
True |
False |
|
trim(string a) 去空格 |
select trim(' aaa ') from test00; |
True |
True |
|
substr(string A,int start,int len) 截取字符串 |
select substr('abcdefg',3,2) from test; select substr('abcdefg',-3,2) from test; |
True |
True |
|
like |
select * from test where a like '%a%'; |
True |
False |
|
Count |
select count(*) from test00; select count(distinct *) from test00; |
True |
False |
|
Sum |
select sum(c) from test00; select sum(distinct c) from test00; |
True |
False |
|
Avg |
select avg(c) from test00 select avg(distinct c) from test00 |
True |
False |
|
Min |
select min(distinct c) from test00; |
True |
False |
|
Max |
select max(distinct c) from test00; |
True |
False |
|
group by |
select a from test00 group by a ; select a,sum(c) from test00 group by a; select a,avg(c) from test00 group by a; |
True |
False |
|
Hiving |
select a,avg(c) as ac from test00 group by a having ac=1; |
True |
False |
|
load |
load data local inpath '/tmp/qichangjian/test01.txt' overwrite into table test_load; |
True |
False |
大数据 Spark 架构的更多相关文章
- 量化派基于Hadoop、Spark、Storm的大数据风控架构--转
原文地址:http://www.csdn.net/article/2015-10-06/2825849 量化派是一家金融大数据公司,为金融机构提供数据服务和技术支持,也通过旗下产品“信用钱包”帮助个人 ...
- 王家林 大数据Spark超经典视频链接全集[转]
压缩过的大数据Spark蘑菇云行动前置课程视频百度云分享链接 链接:http://pan.baidu.com/s/1cFqjQu SCALA专辑 Scala深入浅出经典视频 链接:http://pan ...
- 《大数据Spark企业级实战 》
基本信息 作者: Spark亚太研究院 王家林 丛书名:决胜大数据时代Spark全系列书籍 出版社:电子工业出版社 ISBN:9787121247446 上架时间:2015-1-6 出版日期:20 ...
- Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈与熟练的掌握Scala语言【大数据Spark实战高手之路】
Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈 大数据的概念与应用,正随着智能手机.平板电脑的快速流行而日渐普及,大数据中图的并行化处理一直是一个非常热门的话题.图计算正在被广泛地应用于社交 ...
- 知名大厂如何搭建大数据平台&架构
今天我们来看一下淘宝.美团和滴滴的大数据平台,一方面进一步学习大厂大数据平台的架构,另一方面也学习大厂的工程师如何画架构图.通过大厂的这些架构图,你就会发现,不但这些知名大厂的大数据平台设计方案大同小 ...
- 大数据Spark超经典视频链接全集
论坛贴吧等信息发布参考模板 Scala.Spark史上最全面.最详细.最彻底的一整套视频全集(特别是机器学习.Spark Core解密.Spark性能优化.Spark面试宝典.Spark项目案例等). ...
- 【Todo】【读书笔记】大数据Spark企业级实战版 & Scala学习
下了这本<大数据Spark企业级实战版>, 另外还有一本<Spark大数据处理:技术.应用与性能优化(全)> 先看前一篇. 根据书里的前言里面,对于阅读顺序的建议.先看最后的S ...
- hadoop大数据技术架构详解
大数据的时代已经来了,信息的爆炸式增长使得越来越多的行业面临这大量数据需要存储和分析的挑战.Hadoop作为一个开源的分布式并行处理平台,以其高拓展.高效率.高可靠等优点越来越受到欢迎.这同时也带动了 ...
- Google大数据技术架构探秘
原文地址:https://blog.csdn.net/bingdata123/article/details/79927507 Google是大数据时代的奠基者,其大数据技术架构一直是互联网公司争相学 ...
随机推荐
- 《算法导论》——重复元素的随机化快排Optimization For RandomizedQuickSort
昨天讨论的随机化快排对有重复元素的数组会陷入无限循环.今天带来对其的优化,使其支持重复元素. 只需修改partition函数即可: int partition(int *numArray,int he ...
- java数据类型关系及关系
java中有常见的基本数据类型和引用数据类型,基本数据类型为四类八种如下 整数型(byte,short,int,long) 浮点型(float,double) 字符型(char) 布尔型(boolea ...
- 2017-11-04 Sa OCT codecombat
def hasEnemy(): e = hero.findNearestEnemy() if e: return True else: return False def enemyTooClose() ...
- request设置cookies
mycookie = { "PHPSESSID":"56v9clgo1kdfo3q5q8ck0aaaaa" } request.get(url,cookies ...
- ligbox 插件介绍
浏览器支持情况:一般情况都支持.最好是jQuery v1.x + lightbox.js,这样的组合IE6,IE7,IE8也支持! 1 light插件的下载地址:https://pan.baidu.c ...
- Redis在linux上的配置
一.安装gcc 1.Redis在linux上的安装首先必须先安装gcc,这个是用来编译redis的源文件的.首先需要先切换的到root用户 2.然后开始安装gcc: yum install gcc- ...
- [转]jquery.form.js的ajaxSubmit和ajaxForm使用
参考 http://www.cnblogs.com/popzhou/p/4338040.html 依赖的脚本文件 <script src="../Javascript/jquery-1 ...
- EL表达式与标签库
https://blog.csdn.net/panhaigang123/article/details/78428567
- 【Django】关于数据过滤
学到关于数据库过滤方面的内容总结部分注意点: views.py def TestFilter(request): # 多条件过滤 # list=BookInfo.book_manager.filter ...
- 使用Pyquery+selenium抓取淘宝商品信息
配置文件,配置好数据库名称,表名称,要搜索的产品类目,要爬取的页数 MONGO_URL = 'localhost' MONGO_DB = 'taobao' MONGO_TABLE = 'phone' ...