mysql真的不能做搜索引擎吗?
大家都对电商的商品查询并不陌生,比如我们想根据商品名称查询所有商品信息。

有些技术的童鞋第一念头是搜索引擎;有些技术的童鞋第一念头是模糊查询,如like?(如果商品信息存放到mysql里,我们一般使用like查询)
我们都知道,不同的场景决定了不同技术的使用场景也不同,那我们该如何选择呢?
那我们先做个实验吧(实验对象是mysql 8.0 community 版,windows10)
1.安装mysql 8.0 community 版本 https://dev.mysql.com/downloads/windows/installer/8.0.html
我使用的web版本 step by step
2.安装客户端SQLyog MySQ https://www.cr173.com/soft/22147.html
3 连接mysql 报错:
SQLyog连接报错 Error No.2058 Plugin caching_sha2_password could not be loaded
解决方法:windows 下cmd 登录 mysql -u root -p 登录你的 mysql 数据库,然后 执行这条SQL:
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password';
#password 是你自己设置的root密码
4.插入数据
依赖包:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.13</version>
</dependency>
程序

public void mysqlOneByOneInsert() {
// JDBC 驱动名及数据库 URL
String JDBC_DRIVER = "com.mysql.cj.jdbc.Driver";
String DB_URL = "jdbc:mysql://localhost:3306/www?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false";//链接的mysql
// 数据库的用户名与密码,需要根据自己的设置
String USER = "root";
String PASS = "wangwei456";
try {
long start=System.currentTimeMillis();
Class.forName(JDBC_DRIVER);
Connection connection = DriverManager.getConnection(DB_URL, USER, PASS);
PreparedStatement stmt = connection.prepareStatement("INSERT INTO PERSON(ID,NAME,AGE,ADDRESS,SALARY) values(?,?,?,?,?);");
for(int i=0;i<1000000;i++) {
stmt.setInt(1, i+1);
stmt.setString(2, "mkyong"+i);
stmt.setInt(3, i%100);
stmt.setString(4, "address"+i);
stmt.setFloat(5, 25000.00f);
stmt.executeUpdate();
}
stmt.close();
connection.close();
System.out.println("耗时:"+(System.currentTimeMillis()-start)+" 毫秒");
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
中间报错:
java.sql.SQLException: The server time zone value '???ú±ê×??±??' is unrecognized or represents more
解决方法:
在jdbc连接的url后面加上serverTimezone=GMT即可解决问题,如果需要使用gmt+8时区,需要写成GMT%2B8
感受:mysql输入插入速度(单条)简直是龟速呀 耗时:4390167 毫秒=4390秒=73分钟
1.精确查询 无索引
SELECT * FROM PERSON WHERE NAME='mkyong99999'
耗时:0.747秒
2.模糊查询 无索引
SELECT * FROM PERSON WHERE NAME LIKE 'mkyong99999%'
查询耗时:0.732秒
3.精确查询 有索引
SELECT * FROM PERSON WHERE NAME='mkyong99999'
耗时:0.01秒
4.模糊查询 有索引
FLUSH TABLES;
SELECT * FROM PERSON WHERE NAME LIKE 'mkyong99999%'
耗时:0.02秒
是不是很惊诧?看看执行计划

走的是索引。和很多人的常识是相反的。
5.无索引
SELECT * FROM PERSON WHERE ADDRESS='杭州大街100号99999'
耗时 0.911秒
6.无索引
FLUSH TABLES;
SELECT * FROM PERSON WHERE ADDRESS LIKE '杭州大街100号99999'
耗时0.775秒
7.有索引
FLUSH TABLES;
SELECT * FROM PERSON WHERE ADDRESS='杭州大街100号99999' SELECT * FROM PERSON WHERE ADDRESS LIKE '杭州大街100号99999'
都是0.01秒
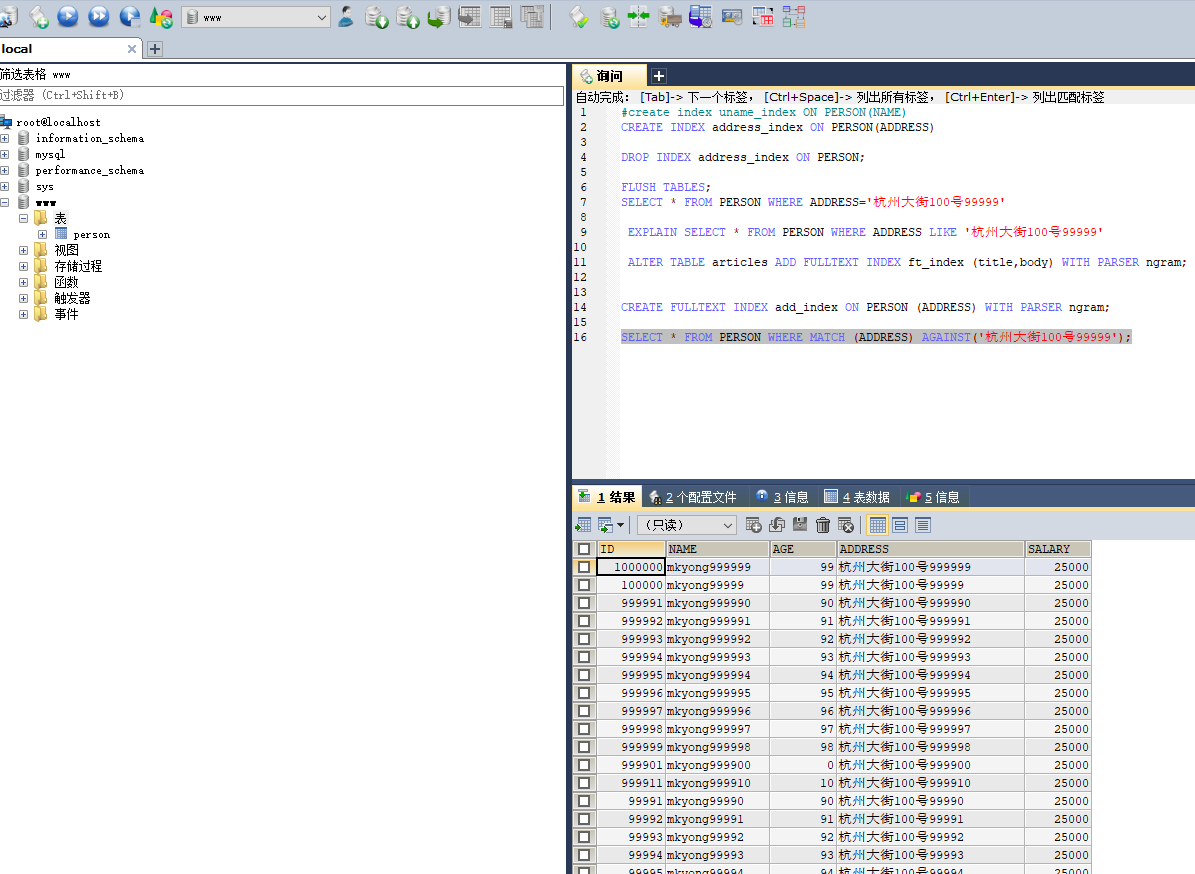
8.针对有些字段比较长,使用模糊查询会慢的问题,mysql 从5.6后提供了全文检索功能,以5.8为例 <https://dev.mysql.com/doc/refman/8.0/en/fulltext-search.html>
ngram Full-Text Parser提供了分词的功能
创建全文索引
CREATE FULLTEXT INDEX add_index ON PERSON (ADDRESS) WITH PARSER ngram;
查询
SELECT * FROM PERSON WHERE MATCH (ADDRESS) AGAINST('杭州大街100号99999');
耗时:23秒
小结:
1.like查询不一定不走索引,以实验验证为准
2.商品量或者数据量比较小的情况下(通常100w以下),like查询并不慢。
3.搜索引擎在千万,亿级别或者以上起到的作用才会比较明显,下篇会继续分析。
4.mysql提供的全文索引的使用还是在掌握的情况下再使用,否则反而会影响系统性能
参考文献:
【1】https://blog.csdn.net/jared456/article/details/80380853
【2】https://blog.csdn.net/weixin_37577564/article/details/80329775
mysql真的不能做搜索引擎吗?的更多相关文章
- centos6.5环境通过shell脚本备份php的web及mysql数据库并做远程备份容灾
centos6.5环境通过shell脚本备份php的web及mysql数据库并做远程备份容灾 系统:centos6.5 1.创建脚本目录 mkdir -p /usr/local/sh/ 创建备份web ...
- MySQL基于域名做高可用切换(Consul初试)
一,Consul功能介绍 服务发现 - Consul的客户端可用提供一个服务,比如 api 或者mysql ,另外一些客户端可用使用Consul去发现一个指定服务的提供者.通过DNS或者HTTP应用程 ...
- Groonga开源搜索引擎——列存储做聚合,没有内建分布式,分片和副本是随mysql或者postgreSQL作为存储引擎由MySQL自身来做分片和副本的
1. Characteristics of Groonga ppt:http://mroonga.org/publication/presentation/groonga-mysqluc2011.pd ...
- coreseek (sphinx)+ Mysql + Thinkphp搭建中文搜索引擎详解
一, 前言 1,研究coreseek的动机 我有一个自己的笔记博客,经常在上面做一些技术文章分析.在查询一些文章的时候,以前只能将要查询的内容去mysql中用like模糊匹配.在文章多了的情 ...
- http+mysql结合keepalived做热备
preface 公司要求http+mysql+redis+二次开发的ldap要求做高可用,所以此处写写keepalived在这种 环境下的高可用.keepalived这个软件我就不啰嗦了,众所周知,基 ...
- 通过读取excel数据和mysql数据库数据做对比(二)-代码编写测试
通过上一步,环境已搭建好了. 下面开始实战, 首先,编写链接mysql的函数conn_sql.py import pymysql def sql_conn(u,pwd,h,db): conn=pymy ...
- mysql系列七、mysql索引优化、搜索引擎选择
一.建立适当的索引 说起提高数据库性能,索引是最物美价廉的东西了.不用加内存,不用改程序,不用调sql,只要执行个正确的'create index',查询速度就可能提高百倍千倍,这可真有诱惑力.可是天 ...
- Java 使用 DBCP mysql 连接池 做数据库操作
需要的jar包有 commons-dbutils , commons-dbcp , commons-pool , mysql-connector-java 本地database.propertties ...
- mysql优化不可不做的事情
写在前面的话:总是在灾难发生后,才想起容灾的重要性:总是在吃过亏后,才记得有人提醒过 设计原则 1.不在数据库做运算:cpu计算务必移至业务层 2.控制单表数据量:单表记录控制在1000w 3.控制列 ...
随机推荐
- 杨其菊201771010134《面向对象程序设计(java)》第四周学习总结
<面向对象程序设计(java)> 第四周学习总结 第一部分:理论知识 1.类与对象 a.类(class)是构造对象的模板或蓝图.由类构造对象的过程称为创建类的实例: java中类声明的格式 ...
- linux学习第十二天 (Linux就该这么学)找到一本不错的Linux电子书,附《Linux就该这么学》章节目录
本书是由全国多名红帽架构师(RHCA)基于最新Linux系统共同编写的高质量Linux技术自学教程,极其适合用于Linux技术入门教程或讲课辅助教材,目前是国内最值得去读的Linux教材,也是最有价值 ...
- 状态机学习(六)解析JSON2
来自 从零开始的 JSON 库教程 从零开始教授如何写一个符合标准的 C 语言 JSON 库 作者 Milo Yip https://zhuanlan.zhihu.com/json-tutorial ...
- ABP框架系列之十五:(Caching-缓存)
Introduction ASP.NET Boilerplate provides an abstraction for caching. It internally uses this cache ...
- 什么是servlet?
一.servlet是什么? 是用java编写的应用在服务端的程序,具有独立于平台和协议的特性,主要功能在于交互式地浏览和修改数据,生成动态Web内容,例如页面等等.从实现上讲,Servlet可以响应任 ...
- two sum --无脑法
public class Solution { /* * @param numbers: An array of Integer * @param target: target = numbers[i ...
- SDWebImage之SDImageCache
SDImageCache和SDWebImageDownloader是SDWebImage库的最重要的两个部件,它们一起为SDWebImageManager提供服务,来完成图片的加载.SDImageCa ...
- 解决C#中调用WCF方法报错:远程服务器返回错误 (404) 未找到
IIS配置问题,解决方法: 1. 首先添加MIME类型 扩展名“.svc”,MIME类型 “application/octet-stream” 2.处理程序映射--添加托管处理程序 请求路径 “.sv ...
- Flask 中的路由系统
基本用法 Django的路由系统url集中在一起,而Flask的路由系统以装饰器的形式装饰在视图上如: @app.route("/",methods=["GET" ...
- this练习题
1 function fn2(){ console.log(this.n) var n='n' this.n=10 console.log(n) } var obj={fn2:fn2, n:1} fn ...