python之文件处理
第一:文件基本处理流程
f=open('text')
one_line=f.readline()
print('one_line:',one_line) #读取一行
print('分割线'.center(50,'-')) #读取一行分割
end_line=f.read() #读取剩余的内容
print(end_line)
f.close() #关闭文件
第三:文件打开方式
文件句柄 = open('文件路径', '打开模式')
文件的打开模式有:
f = file(name[, mode[, buffering]])
入口参数: name 文件名
mode 选项,字符串
buffering 是否缓冲 (0=不缓冲,1=缓冲, >1的int数=缓冲区大小)
返回值 : 文件对象
mode 选项:
"r" 以读方式打开,只能读文件 , 如果文件不存在,会发生异常
"w" 以写方式打开,只能写文件, 如果文件不存在,创建该文件;如果文件已存在,先清空,再打开文件
"a" 追加模式,是可读的;如果不存在则创建;存在则只追加内容
"rb" 以二进制读方式打开,只能读文件 , 如果文件不存在,会发生异常
"wb" 以二进制写方式打开,只能写文件, 如果文件不存在,创建该文件;如果文件已存在,先清空,再打开文件
"ab" 以二进制追加方式打开,可读的,如果文件不存在,创建该文件,如果文件存在,只追加新的内容
补充:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
"r+" 可以读、写文件 , 如果文件不存在,会发生异常
"w+" 可以读、写文件, 如果文件不存在,创建该文件;如果文件已存在,先清空,再打开文件
"a+" 可读可写,如果文件不存在,则创建
总结:
r、w、a为打开文件的基本模式,对应着只读、只写、追加模式;
b、t、+、U这四个字符,与以上的文件打开模式组合使用,二进制模式,文本模式,读写模式、通用换行符,根据实际情况组合使用
第三:文件的字符编码
先看下文件存储的编码方式

文件以UTF-8存储,已utf-8的编码方式可以打开
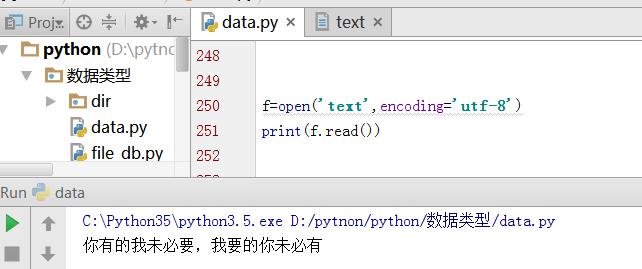
错误示例:使用gbk方式打开

第四:文件中光标内置函数:
read & readline & readlines:
# 打开文件
f = open("text", "r+") print(f.read(2)) #读取字节到字符串中,有可选参数size,默认是-1,如果为-1或复数则文件将会被读取到文件末尾。
#输出结果为: 12 print(f.readline(2)) #读取文件的一行,包括行结束符。同read()也有个可选参数size。
#输出结果: 34 print(f.readline()) #读取一行中剩余内容
#输出结果:567890 print(f.readlines())#读取所有(剩余的)然后将它们作为字符串列表返回,它有个可选参数sizhint代表返回的最大字大小
#输出结果:['abcde\n', 'ABCDE']
seek:seek(offset,where)
seek(offset,where): where=0从起始位置移动,1从当前位置移动,2从结束位置移动。当有换行时,会被换行截断。seek()无返回值,故值为None
示例:
f.seek(1,0) #从开始位置即文件首行首个字符开始移动一个字符
print(f.tell()) #此时tell()为1
print(f.readline()) #读取当前行的内容,即文件的第一行,从第二个字符开始读
#读取结果为:2345
tell:
文件的当前位置,即tell是获得文件指针位置,受seek、readline、read、readlines影响,不受truncate影响
示例:
f=open('text','w+') #文件以w+方式打开,则源文件被清空
print(f.tell()) #源文件被清空,故此时输出为0
f.write("") #在文件中写入12345,故站用5个字符
print(f.tell()) #此时tell()=5
truncate:
示例一:
# 打开文件
f = open("text", "r+")
line = f.readline()
print(line) #输出结果:12345 # 截断剩下的字符串
f.truncate() # 尝试再次读取数据
line = f.readline()
print(line)
#输出结果为空 # 关闭文件
f.close() 示例二:
# 打开文件
f = open("text", "r+") # 截取3个字节
f.truncate(3) msg = f.read()
print(msg) 输出结果:123
# 关闭文件
f.close()
第四:文件内置函数flush
flush()方法的理解:
1.文件的读取,是通过软件将文件从硬盘中读取到内存中
2.文件的写入,是通过软件将文件写入内存缓存区buffer中,然后刷到硬盘中。
现在如果写入内存的数据过大,并且内存速度比硬盘的速度要快,文件的数据都从内存刷到硬盘,内存与硬盘的速度延迟会被无限的放大,效率变低,所以要刷到硬盘的数据我们统一往内存的一小块空间即buffer中放,一段时间后操作系统会将buffer中数据一次性刷到硬盘
3.flush:用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区,不需要是被动的等待输出缓冲区写入。
#!/usr/bin/python
# -*- coding: UTF-8 -*- # 打开文件
f = open("file.txt", "wb")
print(f) # 刷新缓冲区
f.flush() # 关闭文件
f.close()
第五:文件的open函数详解
open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True)
以上全部都是open的参数,有很多,但是常用的是file,mode,encoding file:文件路径,这个要加上引号
mode:打开模式,详细见上面的第二:文件打开方式
buffering:的可取值有0,1,>1三个,0代表buffer关闭(只适用于二进制模式)(不缓冲),1代表line buffer(只适用于文本模式)(缓冲),>1表示初始化的buffer大小(缓冲区大小);
encoding:指定编码方式,一般是utf-8或者gbk
errors:一般取值为strict,ignore,当取strict的时候,字符编码出现问题的时候,会报错,当取ignore的时候,编码出现问题,程序会忽略而过,继续执行下面的程序。
newline:一般取值有None, \n, \r, ”, ‘\r\n',用于区分换行符,但是这个参数只对文本模式有效;
closefd:是与传入的文件参数有关,默认情况下为True,传入的file参数为文件的文件名,取值为False的时候,file只能是文件描述符,什么是文件描述符,就是一个非负整数,在Unix内核的系统中,打开一个文件,便会返回一个文件描述符。
file与open对比:(python2中同时含有file与open两方法,python3中只有open方法)
两者都能够打开文件,对文件进行操作,也具有相似的用法和参数,但是,这两种文件打开方式有本质的区别:
file为文件类,用file()来打开文件,相当于这是在构造文件类,
open()打开文件,是用python的内建函数来操作。
建议不论python2还是python3都使用open来操作
python之文件处理的更多相关文章
- Python读写文件
Python读写文件1.open使用open打开文件后一定要记得调用文件对象的close()方法.比如可以用try/finally语句来确保最后能关闭文件. file_object = open('t ...
- python计算文件的md5值
前言 最近要开发一个基于python的合并文件夹/目录的程序,本来的想法是基于修改时间的比较,即判断文件有没有改变,比较两个文件的修改时间即可.这个想法在windows的pc端下测试没有问题. 但是当 ...
- python操作文件案例二则
前言 python 对于文件及文件夹的操作. 涉及到 遍历文件夹下所有文件 ,文件的读写和操作 等等. 代码一 作用:查找文件夹下(包括子文件夹)下所有文件的名字,找出 名字中含有中文或者空格的文件 ...
- Python :open文件操作,配合read()使用!
python:open/文件操作 open/文件操作f=open('/tmp/hello','w') #open(路径+文件名,读写模式) 如何打开文件 handle=open(file_name,a ...
- python学习 文件操作
一.python打开文件 #=====================python 文件打开方式 open()===================== # open(fileName,type) t ...
- Python之文件读写
本节内容: I/O操作概述 文件读写实现原理与操作步骤 文件打开模式 Python文件操作步骤示例 Python文件读取相关方法 文件读写与字符编码 一.I/O操作概述 I/O在计算机中是指Input ...
- python 遍历文件夹 文件
python 遍历文件夹 文件 import os import os.path rootdir = "d:\data" # 指明被遍历的文件夹 for parent,dirn ...
- python检测文件的MD5值
python检测文件的MD5值MD5(单向散列算法)的全称是Message-Digest Algorithm 5(信息-摘要算法),经MD2.MD3和MD4发展而来.MD5算法的使用不需要支付任何版权 ...
- Python编码/文件读取/多线程
Python编码/文件读取/多线程 个人笔记~~记录才有成长 编码/文件读取/多线程 编码 常用的一般是gbk.utf-8,而在python中字符串一般是用Unicode来操作,这样才能按照单个字 ...
- python 读写文件和设置文件的字符编码
一. python打开文件代码如下: f = open("d:\test.txt", "w") 说明:第一个参数是文件名称,包括路径:第二个参数是打开的模式mo ...
随机推荐
- linux inotify 文件变化检测
用webstorm开发angular项目的时候,改写文件后发现热更新有时候会失效,从而不得不重新运行下项目,然而这浪费了好多时间,google一番后,解决办法如下 echo fs.inotify.ma ...
- The connection string 'MysqlEF' in the application's configuration file does not contain the require异常
在学习EF core first 对接mysql时,出现了这个异常. 原因是:连接字符串中缺少providerName="MySql.Data.MySqlClient" <a ...
- Fib数列2 费马小定理+矩阵乘法
题解: 费马小定理 a^(p-1)=1(mod p) 这里推广到矩阵也是成立的 所以我们可以对(2^n)%(p-1) 然后矩阵乘法维护就好了 模数较大使用快速乘
- [转]CR, LF, CR/LF区别与关系
http://weizhifeng.net/talking-about-cr-lf.html 前言 在文本处理中,CR(Carriage Return),LF(Line Feed),CR/LF是不同操 ...
- 【Android】修改Android 模拟器IMSI
修改Android 模拟器IMEI 在.....\android_sdk\tools文件下找到emulator-arm.exe,使用UltraEdit文本编辑器打开,搜索CIMI关键字,把310260 ...
- FTP(虚拟用户,并且每个虚拟用户可以具有独立的属性配置)
VSFTP是一个基于GPL发布的类Unix系统上使用的FTP服务器软件,它的全称是Very Secure FTP 首先安装 主配置文件:/etc/vsftpd/vsftpd. ...
- day4 字符串的操作
今天是第四天,一如既往的每天都有不会做的内容,然后还是那种你使劲的绞尽脑汁都想不出来的问题,而且还得是别人提示着,讲着,演示着才能明白的,过后自己还得使劲捉摸才能慢慢吃透.一开始还挺顺利的,还以为自己 ...
- Python编程基础(一)
1.Python中的变量赋值不需要类型声明 2.等号(=)用来给变量赋值 3.字符串拼接用 “+” 号 temp=‘123’ print('temp的值是%s'%temp) #整数和字符创的转换, ...
- CSS规范 - 分类方法
CSS文件的分类和引用顺序 通常,一个项目我们只引用一个CSS,但是对于较大的项目,我们需要把CSS文件进行分类. 我们按照CSS的性质和用途,将CSS文件分成“公共型样式”.“特殊型样式”.“皮肤型 ...
- VS2017动态链接库(.dll)的生成与使用
转 https://blog.csdn.net/m0_37170593/article/details/76445972 这里以VS2017为例子,讲解一下动态链接库(.dll)的生成与使用. 一.动 ...