Tree - Information Theory
This will be a series of post about Tree model and relevant ensemble method, including but not limited to Random Forest, AdaBoost, Gradient Boosting and xgboost.
So I will start with some basic of Information Theory, which is an importance piece in Tree Model. For relevant topic I highly recommend the tutorial slide from Andrew moore
What is information?
Andrew use communication system to explain information. If we want to transmit a series of 4 characters ( ABCDADCB... ) using binary code ( 0&1 ). How many bits do we need to encode the above character?
The take away here is the more bit you need, the more information it contains.
I think the first encoding coming to your mind will be following:
A = 00, B=01, C =10, D=11. So on average 2 bits needed for each character.
Can we use less bit on average?
Yes! As long as these 4 characters are not uniformally distributed.
Really? Let's formulate the problem using expectation.
\[ E( N ) = \sum_{k \in {A,B,C,D}}{n_k * p(x=k)} \]
where P( x=k ) is the probability of character k in the whole series, and n_k is the number of bits needed to encode k. For example: P( x=A ) = 1/2, P( x=B ) = 1/4, P( x=c ) = 1/8, P( x=D ) = 1/8, can be encoded in following way: A=0, B=01, C=110, D=111.
Basically we can take advantage of the probability and assign shorter encoding to higher probability variable. And now our average bit is 1.75 < 2 !
Do you find any other pattern here?
the number of bits needed for each character is related to itsprobability : bits = -log( p )
Here log has 2 as base, due to binary encoding
We can understand this from 2 angles:
- How many value can n bits represent? \(2^n\), where each value has probability \(1/2^n\), leading to n = log(1/p).
- Transmiting 2 characters independently: P( x1=A, x2 =B ) = P( x1=A ) * P( x2=B ), N( x1, x2 ) = N( x1 ) + N( x2 ), where N(x) is the number of bits. So we can see that probability and information is linked via log.
In summary, let's use H( X ) to represent information of X, which is also known as Entropy
when X is discrete, \(H(X) = -\sum_i{p_i \cdot log_2{p_i}}\)
when X is continuous, \(H(X) = -\int_x{p(x) \cdot log_2{p(x)}} dx\)
Deeper Dive into Entropy
1. Intuition of Entropy
I like the way Bishop describe Entropy in the book Pattern Recognition and Machine Learning. Entropy is 'How big the surprise is'. In the following post- tree model, people prefer to use 'impurity'.
Therefore if X is a random variable, then the more spread out X is, the higher Entropy X has. See following:
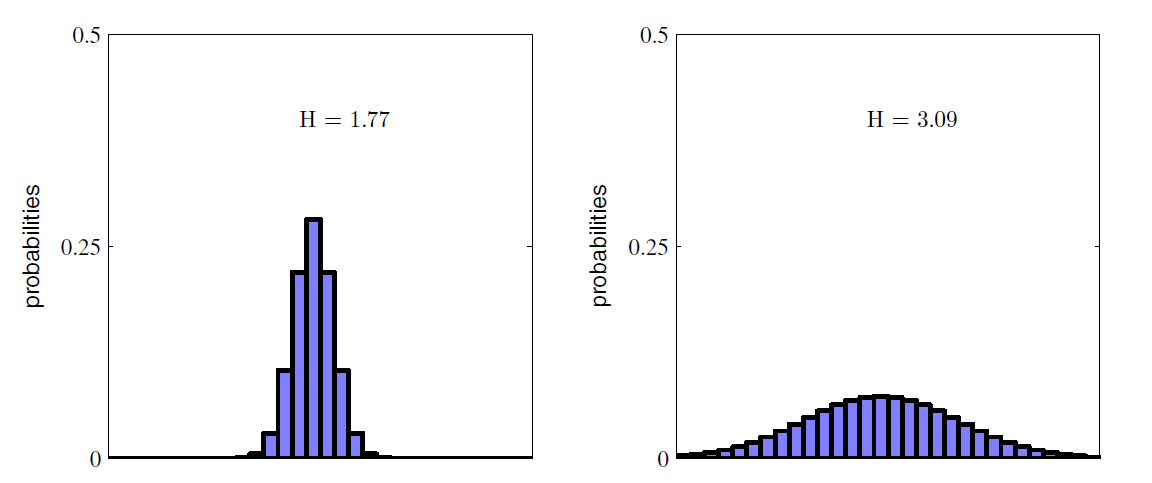
2. Conditional Entropy
Like the way we learn probability, after learning how to calculate probability and joint probability, we come to conditional probability. Let's discuss conditional Entropy.
H( Y | X ) is given X, how surprising Y is now? If X and Y are independent then H( Y | X ) = H( Y ) (no reduce in surprising). From the relationship between probability and Entropy, we can get following:
\[P(X,Y) = P(Y|X) * P(X)\]
\[H(X,Y) = H(Y|X) + H(X)\]
Above equation can also be proved by entropy. Give it a try! Here let's go through an example from Andrew's tutorial to see what is conditional entropy exactly.
X = college Major, Y = Like 'Gladiator'
| X | Y |
|---|---|
| Math | YES |
| History | NO |
| CS | YES |
| Math | NO |
| Math | NO |
| CS | YES |
| History | NO |
| Math | YES |
Let's compute Entropy using above formula:
H( Y ) = -0.5 * log(0.5) - 0.5 * log(0.5) = 1
H( X ) = -0.5 * log(0.5) - 0.25 * log(0.25) - 0.25 * log(0.25) = 1.5
H( Y | X=Math ) = 1
H( Y | X=CS ) = 0
H( Y | X=History ) = 0
H( Y | X ) = H( Y | X=Math ) * P( X=Math ) + H( Y | X=History ) * P( X=History ) + H( Y | X =CS ) * P( X=CS ) = 0.5
Here we see H( Y | X ) < H( Y ), meaning knowing X helps us know more about Y.
When X is continuous, conditional entropy can be deducted in following way:
we draw ( x , y ) from joint distribution P( x , y ). Given x, the additional information on y becomes -log( P( y | x ) ). Then using entropy formula we get:
\[H(Y|X) = \int_y\int_x{ - p(y,x)\log{p(y|x)} dx dy} =\int_x{H(Y|x)p(x) dx} \]
In summary
When X is discrete, \(H(Y|X) = \sum_j{ H(Y|x=v_j) p(x=v_j)}\)
When X is continuous, \(H(Y|X) = \int_x{ H(Y|x)p(x) dx}\)
3. Information Gain
If we follow above logic, then information Gain is the reduction of surpise in Y given X. So can you guess how IG is defined now?
IG = H( Y ) - H( Y | X )
In our above example IG = 0.5. And Information Gain will be frequently used in the following topic - Tree Model. Because each tree splitting aims at lowering the 'surprising' in Y, where the ideal case is that in each leaf Y is constant. Therefore split with higher information is preferred
So far most of the stuff needed for the Tree Model is covered. If you are still with me, let's talk a about a few other interesting topics related to information theory.
Other Interesting topics
Maximum Entropy
It is easy to know that when Y is constant, we have the smallest entropy, where H( Y ) = 0. No surprise at all!
Then how can we achieve biggest entropy. When Y is discrete, the best guess will be uniform distribution. Knowing nothing about Y brings the biggest surprise. Can we prove this ?
All we need to do is solving a optimization with Lagrange multiplier as following:
\[ H(x) = -\sum_i{p_i \cdot \log_2{p_i}} + \lambda(\sum_i{p_i}-1)\]
Where we can solve hat p are equal for each value, leading to a uniform distribution.
What about Y is continuous? It is still an optimization problem like following:
\[
\begin{align}
&\int { p(x) } =1 \\
&\int { p(x) x} = \mu \\
&\int { p(x) (x-\mu)^2} = \sigma^2
\end{align}
\]
\[ -\int_x{p(x) \cdot \log_2{p(x)}dx} +\lambda_1(\int { p(x) dx} - 1) +\lambda_2(\int { p(x) x dx} - \mu) + \lambda_3(\int { p(x) (x-\mu)^2 dx} - \sigma^2)
\]
We will get Gaussian distribution! You want to give it a try?!
Relative Entropy
Do you still recall our character transmitting example at the very beginning? That we can take advantage of the distribution to use less bit to transmit same amount of information. What if the distribution we use is not exactly the real distribution? Then extra bits will be needed to send same amount of character.
If the real distribution is p(x) and the distribution we use for encoding character is q(x), how many additional bits will be needed? Using what we learned before, we will get following
\[ - \int{p(x)\log q(x) dx } + \int{p(x)\log p(x)dx} \]
Does this looks familiar to you? This is also know as Kullback-Leibler divergence, which is used to measure the difference between 2 distribution.
\[
\begin{align}
KL(p||q) &= \int{ -p(x)logq(x) dx } + \int{p(x)logp(x)dx}\\
& = -\int{ p(x) log(\frac{ q(x) }{ p(x) } })dx
\end{align}
\]
And a few features can be easily understood in terms of information theory:
- KL( p || q ) >= 0, unless p = q, additional bits are always needed.
- KL( p || q) != KL( q || p ), because data originally follows 2 different distribution.
To be continued.
reference
- Andrew Moore Tutorial http://www.cs.cmu.edu/~./awm/tutorials/dtree.html
- Bishop, Pattern Recognition and Machine Learning 2006
- T. Hastie, R. Tibshirani and J. Friedman. “Elements of Statistical Learning”, Springer, 2009.
Tree - Information Theory的更多相关文章
- CCJ PRML Study Note - Chapter 1.6 : Information Theory
Chapter 1.6 : Information Theory Chapter 1.6 : Information Theory Christopher M. Bishop, PRML, C ...
- 信息熵 Information Theory
信息论(Information Theory)是概率论与数理统计的一个分枝.用于信息处理.信息熵.通信系统.数据传输.率失真理论.密码学.信噪比.数据压缩和相关课题.本文主要罗列一些基于熵的概念及其意 ...
- information entropy as a measure of the uncertainty in a message while essentially inventing the field of information theory
https://en.wikipedia.org/wiki/Claude_Shannon In 1948, the promised memorandum appeared as "A Ma ...
- Better intuition for information theory
Better intuition for information theory 2019-12-01 21:21:33 Source: https://www.blackhc.net/blog/201 ...
- 信息论 | information theory | 信息度量 | information measures | R代码(一)
这个时代已经是多学科相互渗透的时代,纯粹的传统学科在没落,新兴的交叉学科在不断兴起. life science neurosciences statistics computer science in ...
- 【PRML读书笔记-Chapter1-Introduction】1.6 Information Theory
熵 给定一个离散变量,我们观察它的每一个取值所包含的信息量的大小,因此,我们用来表示信息量的大小,概率分布为.当p(x)=1时,说明这个事件一定会发生,因此,它带给我的信息为0.(因为一定会发生,毫无 ...
- 决策论 | 信息论 | decision theory | information theory
参考: 模式识别与机器学习(一):概率论.决策论.信息论 Decision Theory - Principles and Approaches 英文图书 What are the best begi ...
- The basic concept of information theory.
Deep Learning中会接触到的关于Info Theory的一些基本概念.
- [Basic Information Theory] Writen Notes
随机推荐
- 20145203盖泽双 《Java程序设计》第6周学习总结
20145203盖泽双 <Java程序设计>第6周学习总结 教材学习内容总结 1.如果要将数据从来源中取出,可以使用输入串流,若将数据写入目地, 可以使用输出串流.在java中,输入串流代 ...
- 谷歌浏览器安装POSTMAN
1.下载postman插件,可以自己到网上下载,也可以点击http://download.csdn.net/detail/u010246789/9528471 2.解压文件,在解压后的文件夹中找到.c ...
- regex_replace
Regex_iterator方法需要输入一个正则表达式,以及一个用于替换匹配的字符串的格式化字符串:这个格式化的字符串可以通过表的转义序列引用匹配子字符串的部分内容: 转义序列 $n 替换第n个捕获的 ...
- 文件操作示例脚本 tcl
linux 下,经常会对用到文件操作,下面是一个用 tcl 写的文件操作示例脚本: 其中 set f01 [open "fix.tcl" w] 命令表示 打开或者新建一个文件“fi ...
- tornado 路由、模板语言、session
一:tornado路由系统: 1.面向资源编程: 场景:当我们给别人提供api的时候,往往提供url.比如:电影票api: http://movie.jd.com/book_ticket:预订电影票. ...
- 记录一下iOS Leak的使用方法。
观测过程中不需要使用xcode.只需观察Leak工具即可 1:选中Xcode,点击左上角的Xcode.找到tool 然后找到instrument.如下图 2:打开instrument 找到Leak ...
- mysql获取随机题目、排序
mysql排序问题(对字符串类型数据进行排序)对普通数字字符串字段排序:select * from qq ORDER BY score*1 DESC,time*1 ASC 一.在mysql操作中我们经 ...
- 数据分析-pandas基础入门(一)
最近在学习python,所以了解了一下Pandas,Pandas是基于NumPy的一个开源Python库,它被广泛用于快速分析数据,以及数据清洗和准备等工作. 首先是安装numpy以及pandas, ...
- C语言学习记录_2019.02.12
"学计算机一定要有一个非常强大的心理状态,计算机不是黑魔法,都是人想出来的,别人能够想的出来,那么,总有一天,我也能够想的出来." 指针类型的变量就是保存地址的变量. int* p ...
- 基于Verilog的CRC-CCITT校验
由于笔者在自己设计CRC模块时遇到很多问题,在网上并未找到一篇具有实际指导意义的文章,在经过多次仿真修改再仿真之后得到了正确的结果,故愿意在本文中为大家提供整个设计流程供大家快速完成设计.本文章主要针 ...