openstack系列文章(四)
学习 openstack 的系列文章 - Nova
- Nova 基本概念
- Nova 架构
- openstack Log
- Nova 组件介绍
- Nova 操作介绍
1. Nova 基本概念
Nova 是 openstack 最核心的服务,负责管理和维护云环境的计算资源,虚拟机的生命周期管理就是通过 Nova 来实现的 。
2. Nova 架构
2.1 Nova 基本组件

如上图所示,Nova 由多个组件构成,这些组件以子服务的形式运行 。
举例,通过 systemctl status openstack-nova-compute.service 判断 nova - compute 服务是否运行:

systemctl 命令见这篇文章 。
Nova 主要组件:
- nova - api: 接收和响应客户的 API 调用;
- nova - scheduler:虚机调度服务,负责决定在哪个计算节点上运行虚机;
- nova - compute: 管理虚机的核心服务,通过调用 Hypervisor API 实现虚机生命周期管理;
- hypervisor: 计算节点上的虚拟化管理程序,虚机管理最底层的程序,常用的 hypervisor 有 KVM 、 VMware 等;
- nova - conductor: nova - compute 并不会直接访问数据库,访问数据库的工作通过 nova - conductor 完成,这样做的好处是使得系统具有更好的伸缩性和更高的安全性;
2.2 nova 服务部署
nova - compute 服务一般部署在计算节点上,其它子服务一般部署在控制节点上。
命令 nova service-list 显示 nova 服务运行在哪个节点上:

登陆 controller 查看 nova-scheduler 服务是否运行:

2.3 虚机创建步骤
这篇文章写的非常好: https://ilearnstack.com/2013/04/26/request-flow-for-provisioning-instance-in-openstack/ ,强烈推荐,这里不做赘述 。
3. openstack Log
openstack nova 的 Log 存放路径为 /var/log/nova/ 。
日志格式为 <时间戳><日志等级><代码模块><Request ID><日志内容><源代码位置>, 分别进行介绍:
- 时间戳: 日志记录的时间;
- 日志等级,有 INFO、 WARNING 、 ERROR 、DEBUG 等,默认为 INFO,要查看详细信息,可以将 /etc/nova/nova.conf 中的 debug 选项设为 true, 具体操作细节见 openstack 官网介绍;
- 代码模块,当前运行的代码,举例,如下图所示:

代码模块为 nova.compute.manager, 找到该模块:
- find / -name compute 查找代码所在的 compute 目录;
- cd 到该目录,在该目录下有个 manager.py 的代码,即为运行的代码;
- 搜索 VM 关键字,在 1052 行找到打印这条 Log 的代码:

- Request ID: 日志会记录连续不同的操作,为了便于区分和增加可读性,每个操作都被分配唯一的Request ID,便于查找;
- 日志内容: 记录当前正在执行的操作和结果等重要信息;
- 源代码位置: 日志代码的位置,包括方法名称,源代码文件的目录位置和行号,不是所有日志都有;
4. Nova 组件介绍
4.1 nova - api
nova - api 是 Nova 组件的门户,所有对 Nova 的请求首先会由 nova - api 进行处理。
关于虚机生命周期相关的操作,nova - api 都可以处理, openstack dashboard 中 Instances 栏的下拉菜单中记录着 nova -api 可执行的操作。
4.2 nova - scheduler
nova - scheduler 根据用户的资源需求进行调用,资源需求包括 VCPU, RAM, DISK 和 Metadata , 这些资源需求定义在 flavor 中。
如何根据 flavor 进行调用?
nova - scheduler 的默认调度器是 Filter scheduler , 当Filter scheduler 执行调度操作时,会让 filter 选择满足 flavor 的计算节点,当选出满足条件的计算节点之后计算各计算节点的权重以选择最优的计算节点,在该计算节点上创建 instance。
/etc/nova/nova.conf 中指明了默认的 filter:

RetryFilter: 刷掉已经调度过的节点。
AvailabilityZoneFilter: 将不属于指定 Availability Zone 的计算节点过滤掉,关于 Availability Zone 的介绍和设置可见这篇博文。
ComputeFilter: 保证只有 nova - compute 服务正常工作的计算阶段才能够被 nova - scheduler 调度。
ServerGroupAntiAffinityFilter: 尽量将 Instance 分散部署到不同的节点上,前提是将 Instance 要加入到 Group 中,如果没有指定 server group, Filter 将不做任何过滤。
4.3 nova - compute
nova - compute 在计算节点上运行,负责管理节点上的 instance。
openstack 对 instance 的操作,最后都是交给 nova-compute 来完成的,nova-compute 与 Hypervisor 一起实现 OpenStack 对 instance 生命周期的管理。
nova-compute 的功能可以分为两类:
- 定时向 openstack 报告计算节点的状态;
- 实现 instance 生命周期的管理,包括为 instance 准备资源,创建 instance 的镜像文件,创建 instance 的 XML 文件,创建虚拟网络并启动虚机。
Hypervisor 最清楚计算节点的信息,可以通过 virsh nodeinfo 和 virsh dominfo 命令查看计算节点和instance的信息:
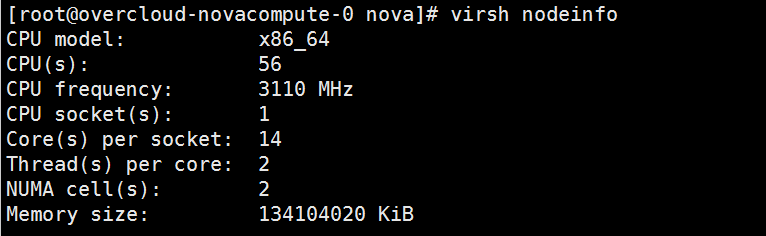

注意要查看计算节点上运行的 instance 信息,需要切换到 root 用户,否则什么都显示不出来。
通过这些命令,也可以计算出这个 instance 还能够容纳多大 flavor 的 instance 。
5. Nova 操作介绍
5.1 Create Instance

通过 log 来分析这一创建过程,Debug 选项没开。
步骤如下:
1. 用户向 nova - api 发送请求: "create instance"

2. nova - scheduler 完成 调度,选择 compute-0 作为 instance 部署的节点

3. nova - compute 首先根据 flavor 为 instance 分配内存,磁盘空间和 vCPU

flavor 所需的资源分配好了之后再分配网络资源给 instance:

为 instance 创建 image :

要注意的是 nova - compute 会检查该 image 在 compute node 上是否存在,如果存在则直接使用,如果不存在,则 ssh 到 glance 通过 scp 下载 image 到本地:

将上传的 image 下载到 /var/lib/nova/instances/_base/ 目录下,下载下来的 image uuid 为 cce3aa2cd0a67c02306843a3523a997f632ee284, 通过 qemu-img info 命令查看该 image 的格式为:

instance 的镜像为 qcow2 格式,因此还需将 raw 格式的 image 转换为 qcow2 的 image 给 instance 用,转换后的 image 在 /var/lib/nova/instances 目录下,uuid 为 17edd30c-bf61-4592-8784-8774e8156469,该uuid 即为 instance 的 uuid 。

同理,通过 qemu-img info 查看该 image 是否为 qcow2 格式:

4. instance 创建成功

5.2 Rescue / Unrescue
Rescue: 故障恢复机制,由于误操作或者突然断电等操作使得操作系统起不来了,为了最大限度挽救数据,使用一张系统盘将系统引导起来,然后在尝试恢复。 问题如果不太严重,可以通过这种方式让系统重新正常工作。
5.3 Soft / Hard Reboot
Soft Reboot: 重启操作系统,整个过程中,instance 依然处于运行状态,相当于在 linux 中执行 reboot 命令。
Hard Reboot: 重启 instance,相当于关机之后再开机 。
5.4 Migrate
Migrate: 将 instance 从当前的计算节点迁移到其他节点上,不要求源和目标节点必须共享存储,Migrate 前必须满足一个条件:计算节点间需要配置 nova 用户无密码访问。
5.5 Live Migrate
Live Migrate: 在线迁移,instance 不会停机,分为共享存储迁移和非共享存储迁移。
关于共享存储 NFS 的内容可见这篇博文。
5.6 Resize
Resize: 调整 instance 的 vCPU、内存和磁盘资源,Migrate 是特殊的 Resize,因为迁移过程中flavor未改变。
参考文章:
https://www.cnblogs.com/CloudMan6/p/5548294.html
https://www.cnblogs.com/liuyisai/p/5992511.html
openstack系列文章(四)的更多相关文章
- openstack系列文章(1)devstack安装测试Queens
1.在OpenStack 圈子中,有这么一句名言:”不要让朋友在生产环境中运行DevStack.但是初学者在没有掌握OpenStack CLI的情况下用devstack安装测试环境还是不错的.本系列文 ...
- openstack系列文章(一)
学习openstack的系列文章-虚拟化 虚拟化 KVM CPU 虚拟化 KVM 内存虚拟化 全虚拟化 I/O 设备 半虚拟化 I/O 设备 I/O PCI PCIe 设备直接分配 SR-IOV 在 ...
- JVM系列文章(四):类载入机制
作为一个程序猿,只知道怎么用是远远不够的. 起码,你须要知道为什么能够这么用.即我们所谓底层的东西. 那究竟什么是底层呢?我认为这不能一概而论.以我如今的知识水平而言:对于Web开发人员,TCP/IP ...
- openstack系列文章(二)
学习openstack的系列文章-keystone openstack 架构 Keystone 基本概念 Keystone 工作流程 Keystone Troubleshooting 1. open ...
- openstack系列文章(三)
学习openstack的系列文章-glance glance 基本概念 glance 架构 openstack CLI Troubleshooting 1. glance 基本概念 在 opensta ...
- openstack系列文章(2)dashboard
玩转dashboard之前,考虑一些事情:(1)安全问题:网络访问策略(2)镜像的密码管理:windows或者linux,root或者administrator密码怎么管理(3)怎样创建自己的镜像:w ...
- Android异步处理系列文章四篇之四 AsyncTask的实现原理
Android异步处理一:使用Thread+Handler实现非UI线程更新UI界面Android异步处理二:使用AsyncTask异步更新UI界面Android异步处理三:Handler+Loope ...
- Android异步处理系列文章四篇之三
Android异步处理一:使用Thread+Handler实现非UI线程更新UI界面Android异步处理二:使用AsyncTask异步更新UI界面Android异步处理三:Handler+Loope ...
- Android异步处理系列文章四篇之二 使用AsyncTask异步更新UI界面
Android异步处理一:使用Thread+Handler实现非UI线程更新UI界面Android异步处理二:使用AsyncTask异步更新UI界面Android异步处理三:Handler+Loope ...
随机推荐
- 【[HNOI2016]序列】
莫队好题啊 莫队来做这个题的难点就是考虑如何在\(O(1)\)时间内由\([l,r]\)转移到\([l,r+1]\) 显然加入\(r+1\)这个数之后会和之前所有的位置都产生一个区间,就是要去快速求出 ...
- Python之Tornadoweb框架使用
本文主要讲解Tornadoweb框架的安装和介绍及其简单使用. 一. 安装介绍 Tornado是一个Python Web框架和异步网络库,最初是在FriendFeed上开发的.通过使用非阻塞网络I / ...
- 集合之HashMap
HashMap也是我们使用非常多的Collection,它是基于哈希表的 Map 接口的实现,以key-value的形式存在.在HashMap中,key-value总是会当做一个整体来处理,系统会根据 ...
- python list 使用技巧
格式:list[start:stop:step] 示例:a =list(range(0,10))print(a[1:8:2]) #[1, 3, 5, 7]print(a[:8:2]) #[0, 2, ...
- MepReduce-开启大数据计算之门
Hadoop MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算.早期的MapReduce(MR)框架简单明了,JobTracker作为MR框架的集中处理点,随着分布式系统集群 ...
- day91 DjangoRestFramework学习三之认证组件、权限组件、频率组件、url注册器、响应器、分页组件
DjangoRestFramework学习三之认证组件.权限组件.频率组件.url注册器.响应器.分页组件 本节目录 一 认证组件 二 权限组件 三 频率组件 四 URL注册器 五 响应器 六 分 ...
- SQL用法总全
https://www.yiibai.com/sql 比较全面 事务就是对数据库执行的工作单元.事务是完成逻辑顺序的工作,无论是在手动方式由用户或者自动地通过某种数据库程序的序列的单元. 事务是一个或 ...
- ADI高速信号采集芯片与JESD204B接口简介
ADI高速信号采集芯片与JESD204B接口简介 JESD204B接口 介绍: JEDEC Standard No. 204B (JESD204B)—A standardized serial int ...
- 关于DFS与BFS
DFS(深度优先搜索) 为无向图 DFS的过程类似于树的先序遍历. 请看图: DFS此图的过程为: 1.首先任意找一个未被便利过的顶点,例如从V1开始,由于率先访问了它,所以需要标记V1即已经访问 ...
- 25-[jQuery]-ajax
1.什么是AJAX AJAX = 异步的javascript和XML(Asynchronous Javascript and XML) 简言之,在不重载整个网页的情况下,AJAX通过后台加载数据,并在 ...