Spark程序本地运行
Spark程序本地运行
本次安装是在JDK安装完成的基础上进行的! SPARK版本和hadoop版本必须对应!!!
spark是基于hadoop运算的,两者有依赖关系,见下图:

前言:
1.环境变量配置:
1.1 打开“控制面板”选项

1.2.找到“系统”选项卡
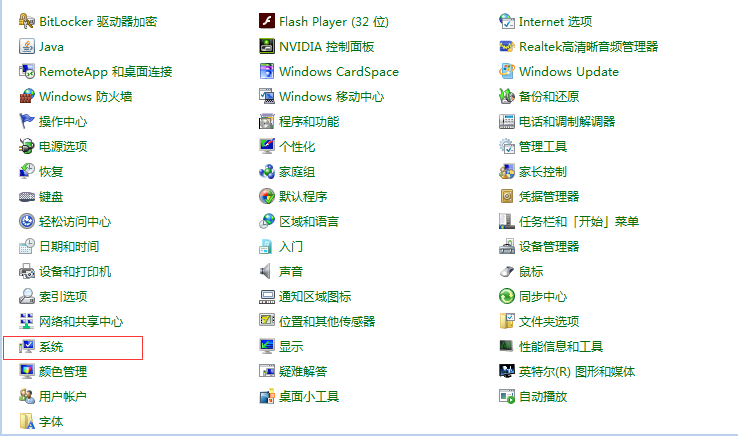
1.3.点击“高级系统设置”

1.4.点击“环境变量”
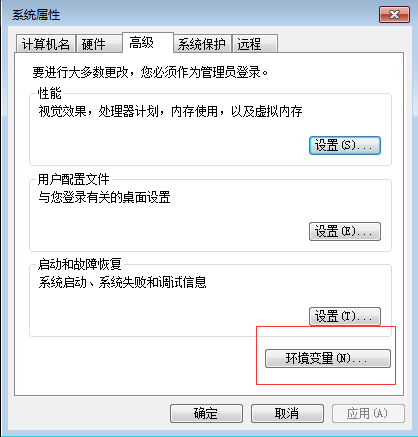
2.新建和编辑环境变量
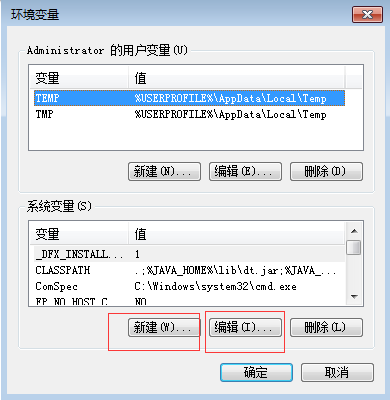
1.下载hadoop-2.6.0.tar.gz文件,并解压在本地
1.1 新建环境变量上配置
HADOOP_HOME
D:\JAVA\hadoop
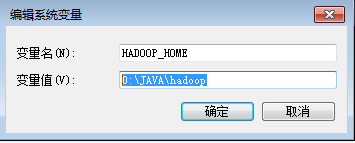
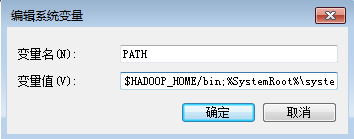
1.2 修改PATH路径
$HADOOP_HOME/bin;
2.下载scala-2.10.6.zip文件,并解压在本地
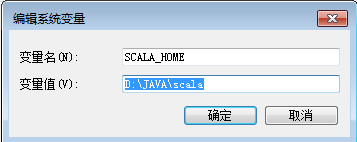
2.1 新建环境变量上配置
SCALA_HOME
D:\JAVA\scala
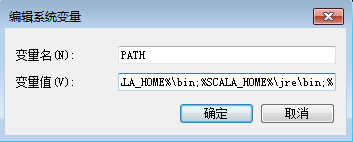
2.2 修改PATH路径
%SCALA_HOME%\bin;%SCALA_HOME%\jre\bin;
3.下载spark-1.6.2-bin-hadoop2.6.tgz文件,并解压在本地
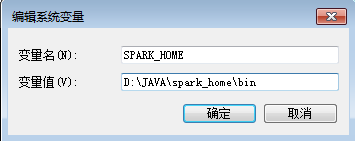
3.1 新建环境变量上配置
SPARK_HOME
D:\JAVA\spark_home\bin
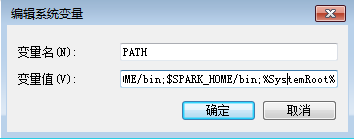
3.2 修改PATH路径
PATH $SPARK_HOME/bin;
4.下载scala-IDE.zip文件,并解压在本地
新建一个工程,修改library:
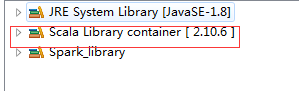
Scala library一定要是:2.10.X
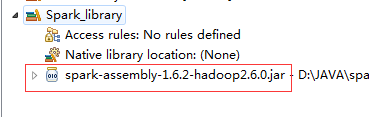
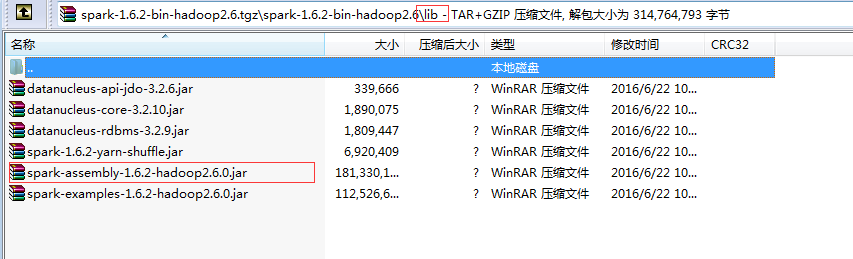
新建一个自己的library:添加一个Jar文件(${spark_home}/lib)
下跟Word Count代码

package com import org.apache.spark.SparkConf
import org.apache.spark.api.java.JavaSparkContext
import org.apache.spark.SparkContext /**
* 统计字符出现次数
*/
object WordCount {
def main(args: Array[String]): Unit = { System.setProperty("hadoop.home.dir", "D:\\JAVA\\hadoop");
val sc = new SparkContext("local", "My App")
val line = sc.textFile("/srv/1.txt") line.map((_, 1)).reduceByKey(_+_).collect().foreach(println) sc.stop()
println(111111)
}
}
hadoop下载点击这里
spark下载点击这里
scala安装包,scala IDE下载点击这里
Spark程序本地运行的更多相关文章
- spark 程序 windows 运行报错
1 java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries. at ...
- spark window本地运行wordcount错误
在运行本地运行spark或者hadoop代码时可能会遇到一下三种问题 1.Exception in thread "main" java.lang.UnsatisfiedLin ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- scala IDE for Eclipse开发Spark程序
1.开发环境准备 scala IDE for Eclipse:版本(4.6.1) 官网下载:http://scala-ide.org/download/sdk.html 百度云盘下载:链接:http: ...
- 初识Spark程序
执行第一个spark程序 普通模式提交任务: bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark ...
- [Spark]如何设置使得spark程序不输出 INFO级别的内容
Spark程序在运行的时候,总是输出很多INFO级别内容 查看了网上的一些文章,进行了试验. 发现在 /etc/spark/conf 目录下,有一个 log4j.properties.template ...
- spark之scala程序开发(本地运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- 如何在本地使用scala或python运行Spark程序
如何在本地使用scala或python运行Spark程序 包含两个部分: 本地scala语言编写程序,并编译打包成jar,在本地运行. 本地使用python语言编写程序,直接调用spark的接口, ...
- Spark认识&环境搭建&运行第一个Spark程序
摘要:Spark作为新一代大数据计算引擎,因为内存计算的特性,具有比hadoop更快的计算速度.这里总结下对Spark的认识.虚拟机Spark安装.Spark开发环境搭建及编写第一个scala程序.运 ...
随机推荐
- 测试一下你的T-SQL基础知识-count
下面count的返回值是多少? ) ); GO INSERT mytable ( myid, mychar ) VALUES ( , 'A' ), ( , 'B'), ( NULL, 'C' ), ( ...
- SVG系列教程:SVG简介与嵌入HTML页面的方式
地址:http://www.w3cplus.com/html5/svg-introduction-and-embedded-html-page.html 随着技术向前的推进,SVG相关的讨论也越渐频繁 ...
- EasyUi Grid以POST方式传送参数绑定
function LoadList() { $("#TableContainer").datagrid({ url: '/HM/ ...
- 隐式等待-----Selenium快速入门(九)
有时候,网页未加载完成,或加载失败,但是我们后续的代码就已经开始查找页面上的元素了,这通常将导致查找元素失败.在本系列Selenium窗口切换-----Selenium快速入门(六)中,我们就已经出现 ...
- 服务端JSON内容中有富文本时
问题背景 由于数据中存在复杂的富文本,包含各种引号和特殊字符,导致后端和前端通过JSON格式进行数据交互引发前端JSON解析出错. 解决方案 后端将富文本内容 ConvertToBase64Strin ...
- IdentityServer4中文文档
欢迎IdentityServer4 IdentityServer4是ASP.NET Core 2的OpenID Connect和OAuth 2.0框架. 它在您的应用程序中启用以下功能: 认证即服务 ...
- Pacemaker 介绍
1. 简介 Pacemaker是一个集群资源管理者.他用资源级别的监测和恢复来保证集群服务(aka.资源)的最大可用性.它可以用你所擅长的基础组件(Corosync或者是Heartbeat)来实现通信 ...
- Lunix git stash clear 或者 git stash drop后恢复的方法
首先输入 git fsck --lost-found 会看到 一条一条的记录 这里的"dangling commit ..."你可以理解为记录的是你stash的id(经测试,该id ...
- 【转】POJ分类很好很有层次感
OJ上的一些水题(可用来练手和增加自信) (poj3299,poj2159,poj2739,poj1083,poj2262,poj1503,poj3006,poj2255,poj3094) 初期: 一 ...
- JS弹出对话框函数alert(),confirm(),prompt()
1,警告消息框alert() alert 方法有一个参数,即希望对用户显示的文本字符串.该字符串不是 HTML 格式.该消息框提供了一个“确定”按钮让用户关闭该消息框,并且该消息框是模式对话框,也就是 ...