Hadoop Hive概念学习系列之hive里的JDBC编程入门(二十二)
Hive与JDBC示例
在使用 JDBC 开发 Hive 程序时, 必须首先开启 Hive 的远程服务接口。在hive安装目录下的bin,使用下面命令进行开启:
hive -service hiveserver & //Hive低版本提供的服务是:Hiveserver
hive --service hiveserver2 & //Hive0.11.0以上版本提供了的服务是:Hiveserver2
我这里使用的Hive1.0版本,故我们使用Hiveserver2服务,下面我使用 Java 代码通过JDBC连接Hiveserver。

18.1 测试数据
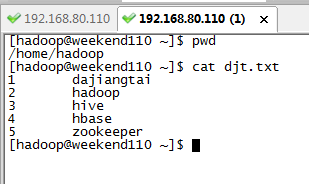
本地目录/home/hadoop/下的djt.txt文件内容(每行数据之间用tab键隔开)如下所示:
1 dajiangtai
2 hadoop
3 Hive
4 hbase
5 spark
18.2 程序代码
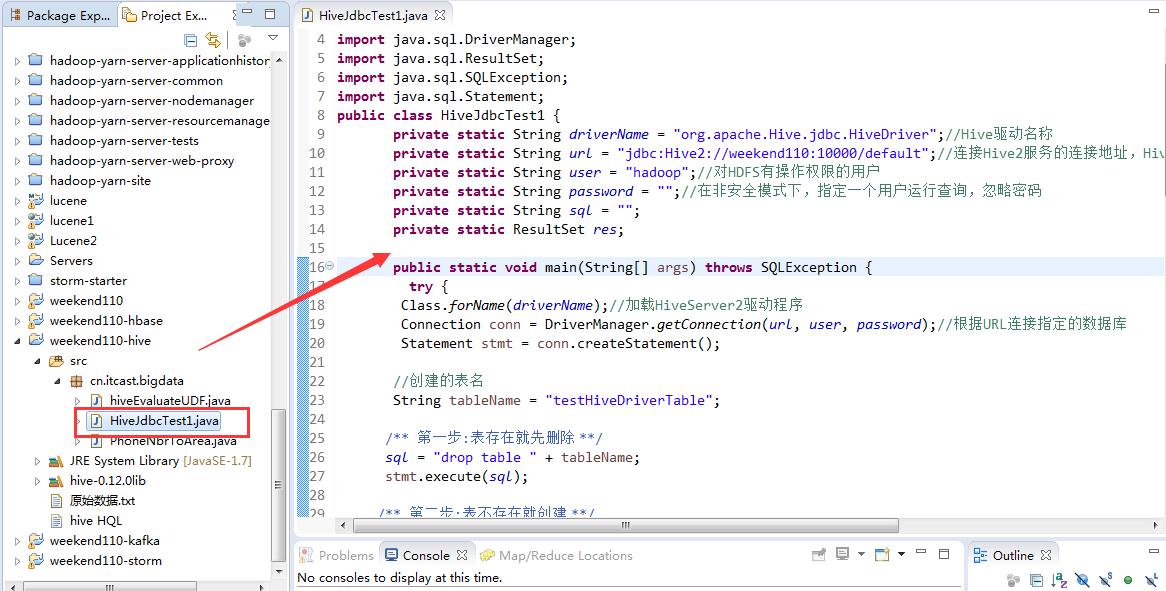
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class HiveJdbcTest1 {
private static String driverName = "org.apache.Hive.jdbc.HiveDriver";//Hive驱动名称
private static String url = "jdbc:Hive2://djt11:10000/default";//连接Hive2服务的连接地址,Hive0.11.0以上版本提供了一个全新的服务:HiveServer2
private static String user = "hadoop";//对HDFS有操作权限的用户
private static String password = "";//在非安全模式下,指定一个用户运行查询,忽略密码
private static String sql = "";
private static ResultSet res;
public static void main(String[] args) {
try {
Class.forName(driverName);//加载HiveServer2驱动程序
Connection conn = DriverManager.getConnection(url, user, password);//根据URL连接指定的数据库
Statement stmt = conn.createStatement();
//创建的表名
String tableName = "testHiveDriverTable";
/** 第一步:表存在就先删除 **/
sql = "drop table " + tableName;
stmt.execute(sql);
/** 第二步:表不存在就创建 **/
sql = "create table " + tableName + " (key int, value string) row format delimited fields terminated by '\t' STORED AS TEXTFILE";
stmt.execute(sql);
// 执行“show tables”操作
sql = "show tables '" + tableName + "'";
res = stmt.executeQuery(sql);
if (res.next()) {
System.out.println(res.getString(1));
}
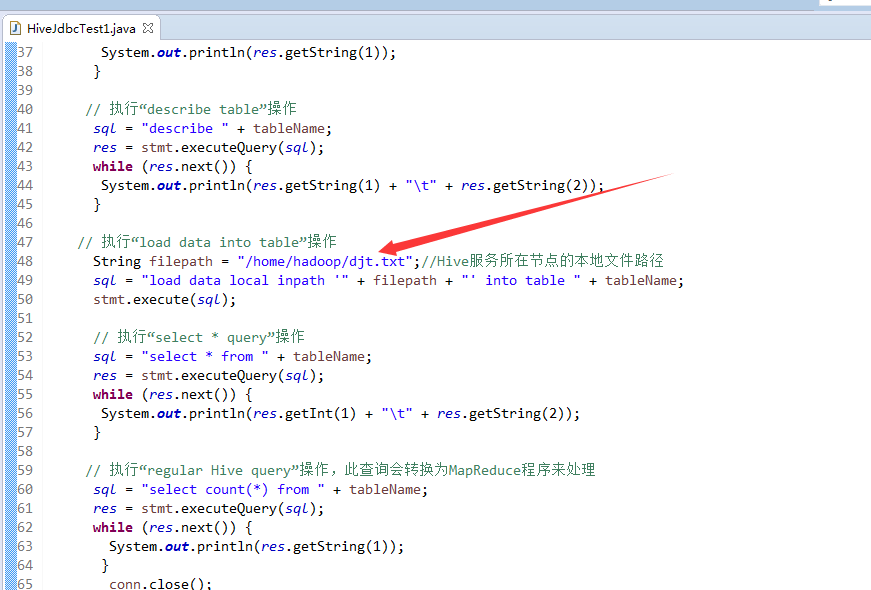
// 执行“describe table”操作
sql = "describe " + tableName;
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "\t" + res.getString(2));
}
// 执行“load data into table”操作
String filepath = "/home/hadoop/djt.txt";//Hive服务所在节点的本地文件路径
sql = "load data local inpath '" + filepath + "' into table " + tableName;
stmt.execute(sql);
// 执行“select * query”操作
sql = "select * from " + tableName;
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getInt(1) + "\t" + res.getString(2));
}
// 执行“regular Hive query”操作,此查询会转换为MapReduce程序来处理
sql = "select count(*) from " + tableName;
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1));
}
conn.close();
conn = null;
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.exit(1);
} catch (SQLException e) {
e.printStackTrace();
System.exit(1);
}
}
}
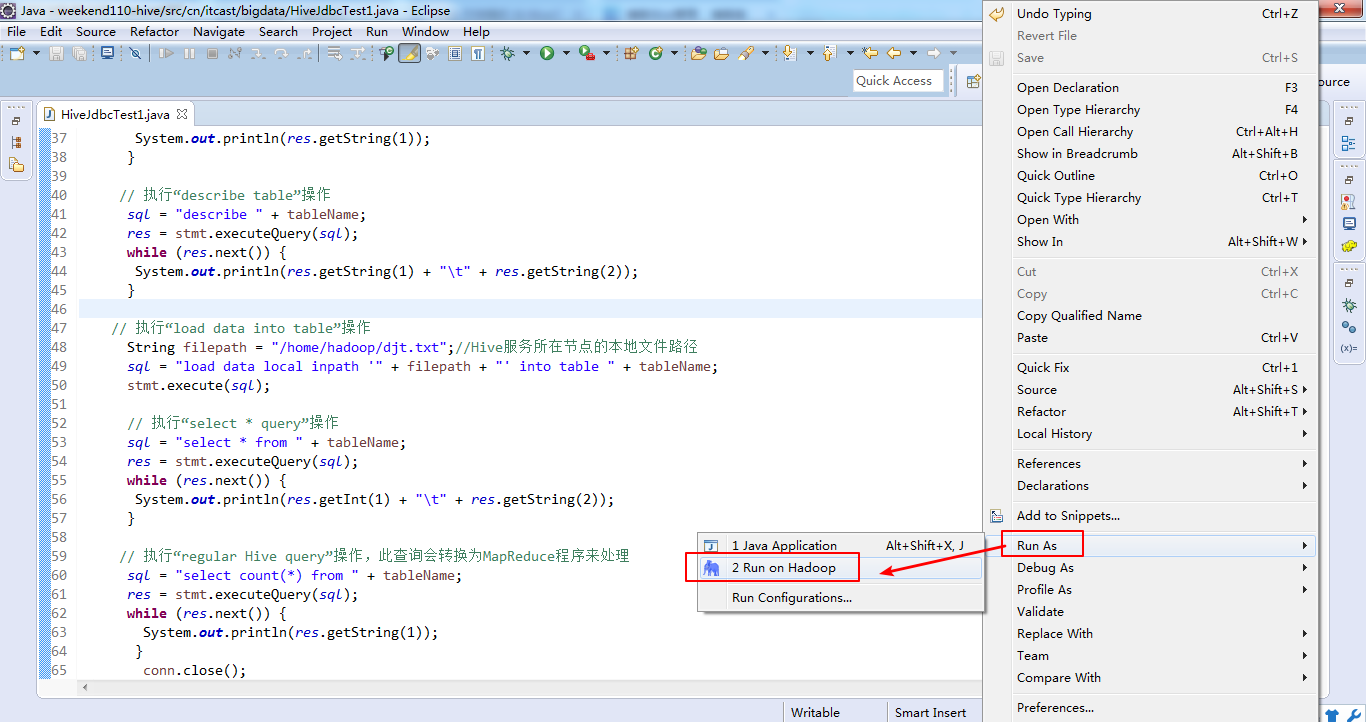
18.3 运行结果(右击-->Run as-->Run on Hadoop)
执行“show tables”运行结果:
testHivedrivertable
执行“describe table”运行结果:
key int
value string
执行“select * query”运行结果:
1 dajiangtai
2 hadoop
3 Hive
4 hbase
5 spark
执行“regular Hive query”运行结果:
5
hive jdbc使用
Hive项目开发环境搭建(Eclipse\MyEclipse + Maven)
Hadoop Hive概念学习系列之hive里的JDBC编程入门(二十二)的更多相关文章
- Hadoop HDFS概念学习系列之HDFS升级和回滚机制(十二)
不多说,直接上干货! HDFS升级和回滚机制 作为一个大型的分布式系统,Hadoop内部实现了一套升级机制,当在一个集群上升级Hadoop时,像其他的软件升级一样,可能会有新的bug或一些会影响现有应 ...
- Hadoop Hive概念学习系列之hive里的索引(十三)
Hive支持索引,但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键. Hive索引可以建立在表中的某些列上,以提升一些操作的效率,例如减少MapReduce任务中需要 ...
- Hadoop Hive概念学习系列之hive里的扩展接口(CLI、Beeline、JDBC)(十六)
<Spark最佳实战 陈欢>写的这本书,关于此知识点,非常好,在94页. hive里的扩展接口,主要包括CLI(控制命令行接口).Beeline和JDBC等方式访问Hive. CLI和B ...
- Hadoop Hive概念学习系列之hive里如何显示当前数据库及传参(十九)
这个小知识点,看似简单,用处极大. $ hive --hiveconf hive.cli.print.current.db=true $ hive --hiveconf hive.cli.print. ...
- Hadoop Hive概念学习系列之hive三种方式区别和搭建、HiveServer2环境搭建、HWI环境搭建和beeline环境搭建(五)
说在前面的话 以下三种情况,最好是在3台集群里做,比如,master.slave1.slave2的master和slave1都安装了hive,将master作为服务端,将slave1作为服务端. 以 ...
- Hadoop Hive概念学习系列之hive里的优化和高级功能(十四)
在一些特定的业务场景下,使用hive默认的配置对数据进行分析,虽然默认的配置能够实现业务需求,但是分析效率可能会很低. Hive有针对性地对不同的查询进行了优化.在Hive里可以通过修改配置的方式进行 ...
- Hadoop Hive概念学习系列之hive里的分区(九)
为了对表进行合理的管理以及提高查询效率,Hive可以将表组织成“分区”. 分区是表的部分列的集合,可以为频繁使用的数据建立分区,这样查找分区中的数据时就不需要扫描全表,这对于提高查找效率很有帮助. 分 ...
- Hadoop Hive概念学习系列之hive里的用户定义函数UDF(十七)
Hive可以通过实现用户定义函数(User-Defined Functions,UDF)进行扩展(事实上,大多数Hive功能都是通过扩展UDF实现的).想要开发UDF程序,需要继承org.apache ...
- Hadoop Hive概念学习系列之hive里的视图(十二)
不多说,直接上干货! 可以先,从MySQL里的视图概念理解入手 视图是由从数据库的基本表中选取出来的数据组成的逻辑窗口,与基本表不同,它是一个虚表.在数据库中,存放的只是视图的定义,而不存放视图包含的 ...
随机推荐
- springboot 以jar方式在linux后台运行
linux命令如下: nohup java -jar 自己的springboot项目.jar >日志文件名.log 2>&1 & 命令解释: nohup:不挂断地运行命令, ...
- windows设置代理.bat 脚本
按照下列脚本复制到记事本中,保存,重命名后缀为.bat,使用时双击即可. 设置代理.bat,修改下列脚本中的代理地址和端口号 @echo off echo 开始设置IE代理上网 reg add &qu ...
- sql 恢复数据库
RESTORE DATABASE RoadFlowWebForm --数据库名称 FROM DISK = 'E:\WEBFORM2.5.1.bak' --bak文件路径 with replace, M ...
- Xor Sum(HDU4825 + 字典树)
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=4825 题目: 题意: 先给你n个数,再进行q次查询,每次查询数s与原来给的n个数异或和最大的数. 思 ...
- 20165329 Java实验二:面向对象编程
实验内容: 面向对象程序设计-1 实验要求: 提交最后三个JUnit测试用例(正常情况,错误情况,边界情况)都通过的截图 实验步骤: 1.按照老师博客的要求新建一个MyUtil项目 在src内新建ja ...
- 【codeforces】【比赛题解】#920 Educational CF Round 37
[A]浇花 题意: 一个线段上每个整点都有花,有的点有自动浇花的喷水器,有问几秒能浇完所有的花. 题解: 大模拟 #include<cstdio> #include<cstring& ...
- 60、二叉搜索树的第k个结点
一.题目 给定一颗二叉搜索树,请找出其中的第k大的结点.例如, 5 / \ 3 7 /\ /\ 2 4 6 8 中,按结点数值大小顺序第三个结点的值为4. 二.解法 package algorithm ...
- imperva 网管替换
事情是这样的 某某银行的imperva DAM审计设备出现蜂鸣的响声.经检查电源没有问题,怀疑是硬盘坏了 . 然后我就去底层查看 运行命令 :impctl platform storage raid ...
- 解决 Windows 环境 Git Bash 无法识别 Composer 命令的问题
思路 模拟 Linux,复制一个 composer 文件到 Git Bash 的 /usr 的子目录,并赋予执行权限. 解决 首先,请确定你的 composer.phar 文件路径.我的是: /d/w ...
- ansible批量修改linux服务器密码的playbook
从网上找到批量修改Linux服务器root密码的playbook. 使用方法: 1.输入要修改的inventory组 2.按需要,在playbook中输入要修改的IP.新密码,如下: - hosts: ...