hadoop学习笔记(一):概念和组成
一、什么是hadoop
Apache Hadoop是一款支持数据密集型分布式应用并以Apache 2.0许可协议发布的开源软件框架。它支持在商品硬件构建的大型集群上运行的应用程序。Hadoop是根据Google公司发表的MapReduce和Google档案系统的论文自行实作而成。
Hadoop框架透明地为应用提供可靠性和数据移动。它实现了名为MapReduce的编程范式:应用程序被分割成许多小部分,而每个部分都能在集群中的任意节点上执行或重新执行。此外,Hadoop还提供了分布式文件系统,用以存储所有计算节点的数据,这为整个集群带来了非常高的带宽。MapReduce和分布式文件系统的设计,使得整个框架能够自动处理节点故障。它使应用程序与成千上万的独立计算的电脑和PB级的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
- 高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
- 高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- 高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
二、hadoop的历史背景
1. HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2. 2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
3. Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
三、hadoop组成
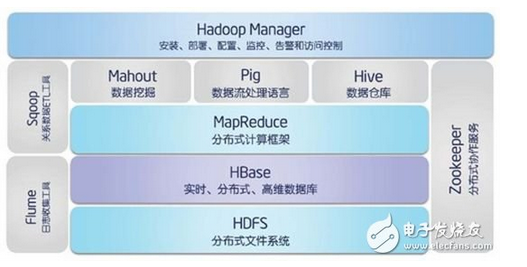
1、HDFS:Hadoop分布式文件系统(Distributed File System)-HDFS(Hadoop Distributed File System)。
2、HBase:是一种构建在HDFS之上的分布式、面向列的存储系统。在需要实时读写、随机访问超大规模数据集时,可以使用HBase。
3、MapReduce:并行计算框架,两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算。
4、Hive:构建于hadoop之上的数据仓库,通过一种类SQL语言HiveQL为用户提供数据的归纳、查询和分析等功能。Hive最初由Facebook贡献。
5、Pig:是指的一种数据处理工具,常用于配合Hadoop使用,用于处理大数据的分析与处理(数据批处理)。因为Pig有一套专属的语法(与MySQL类似),所以相比于MapReduce来说,更适合做一些复杂度不高的数据筛选处理工作,只需要简单几行命令就可以获得可能几百行MapReduce代码带来的收益。
6、Mahout:机器学习算法软件包。
7、Apache Sqoop:是一种旨在有效地在Apache Hadoop和诸如关系数据库等结构化数据存储之间传输大量数据的工具。
8、Flume:Flume是Cloudera提供的日志收集系统,具有分布式、高可靠、高可用性等特点,对海量日志采集、聚合和传输,Flume支持在日志系统中制定各类数据发送,同时,Flume提供对数据进行简单处理,并写到各种数接受方的能力。其设计的原理也是基于将数 据流,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中。
9、zookeeper:分布式协调服务基础组件
hadoop学习笔记(一):概念和组成的更多相关文章
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- hadoop学习笔记-目录
以下是hadoop学习笔记的顺序: hadoop学习笔记(一):概念和组成 hadoop学习笔记(二):centos7三节点安装hadoop2.7.0 hadoop学习笔记(三):hdfs体系结构和读 ...
- [转帖]hadoop学习笔记:hadoop文件系统浅析
hadoop学习笔记:hadoop文件系统浅析 https://www.cnblogs.com/sharpxiajun/archive/2013/06/15/3137765.html 1.什么是分布式 ...
- hadoop学习笔记(四):HDFS文件权限,安全模式,以及整体注意点总结
本文原创,转载注明作者和原文链接! 一:总结注意点: 到现在为止学习到的角色:三个NameNode.SecondaryNameNode.DataNode 1.存储的是每一个文件分割存储之后的元数据信息 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
- Hadoop学习笔记(3)——分布式环境搭建
Hadoop学习笔记(3) ——分布式环境搭建 前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下. 在这里, ...
- Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
随机推荐
- 在 WampServer 上手工安装 PHP 的多个版本
手工安装新版本的PHP,只需以下步骤: 下载要安装的PHP版本.既然是用WampServer,那当然是下载Window版本的ZIP包啦:http://windows.php.net.解压到 Wamp的 ...
- MS sql 无法进行事务日志备份
问题出在:恢复模型没有设置好我们之所以要备份数据库和事务日志都是为了以防万一,用来恢复.还原数据库的,因此恢复模型必须设置好,在sql server中默认的恢复模型为"简单".一般 ...
- MAC CURL : Error:35 SSL certificate problem: Couldn't understand the server certificate format
起因,使用极光推送最新的版本,里面curl使用https请求,而导致证书出错.一看就懵逼了,从来没遇到过这样的问题,二话不说直接百度,然后就更加懵逼了,搜出来的没有中文内容,对于我这种英文渣来说,简直 ...
- python 2 类与对象
1.类与对象的概念 类即类别.种类,是面向对象设计最重要的概念,从一小节我们得知对象是特征与技能的结合体,而类则是一系列对象相似的特征与技能的结合体. 那么问题来了,先有的一个个具体存在的对象(比如一 ...
- samtools软件的使用
1)samtools简介--------------------------------------------------------------------------背景:前面我们讲过sam/b ...
- git冲突解决方案 Intellij IDEA
一般在团队合作开发一个项目的过程中,经常出现两个人同时修改一个文件然后都向主master提交commit,这样就会产生冲突(conflict),那么这种情况如何解决? 1 新建分支 如果项目的主分支是 ...
- jQuery源码解读二(apply和call)
一.apply方法和call方法的用法: apply方法: 语法:apply(thisObj,[,argArray]) 定义:应用某一对象的一个方法,用另一个对象替换当前对象. 说明:如果argArr ...
- MySQL+Navicat for MySQL安装
一.安装MySQL 1.下载MySQL http://cdn.mysql.com//Downloads/MySQL-5.7/mysql-5.7.10-winx64.zip 2.安装 2.1解压安装包 ...
- Hibernate分页查询的两个方法
Hibernate中HQL查询语句有一个分页查询, session.setMaxResult(参数)和session.setFirstResult(参数) 如果只设置session.setMaxRes ...
- for循环计算阶乘
int x = 10; for(int y = x - 1; y >= 1; y--) { x = x * y; } System.out.println(x); 从10乘到1的阶乘写法. lo ...