Scrapy-简单介绍
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
编写一个Scrapy项目需要以下几个简单的流程:
创建一个Scrapy项目
scrapy startproject projectName
cd projectName
scrapy genspider baidu baidu.com
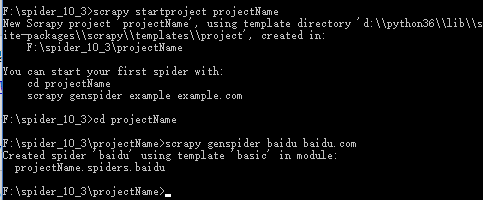
然后就会在你的集成化工具上出现创建的项目:
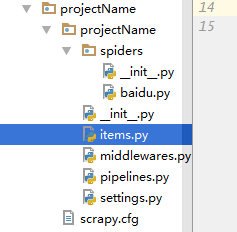
定义提取的Item(你需要爬取的数据的容器)
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
import scrapy
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['baidu.com']
start_urls = ['http://baidu.com/']
def parse(self, response):
#主要爬取代码编写区
pass
编写 Item Pipeline 来存储提取到的Item(即数据)
class ProjectnamePipeline(object):
def process_item(self, item, spider):
#对爬取到的数据进行处理
return item
运行项目
方法一:cmd命令行输入运行 Scrapy 项目
scrapy crawl baidu #这里的baidu是spider的名字不是项目名,是唯一的
方法二:.py文件运行 Scrapy 项目
创建 runBaidu.py 文件
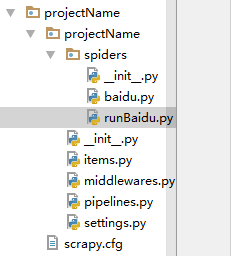
from scrapy import cmdline
cmdline.execute("scrapy crawl baidu".split())
Scrapy-简单介绍的更多相关文章
- Learning Scrapy笔记(一)- Scrapy简单介绍
Scrapy简述 Scrapy十一个健壮的,用来从互联网上抓取数据的web框架,Scrapy只需要一个配置文件就能组合各种组件和配置选项,并且Scrapy是基于事件(event-based)的架构,使 ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy -->CrawlSpider 介绍
scrapy -->CrawlSpider 介绍 1.首先,通过crawl 模板新建爬虫: scrapy genspider -t crawl lagou www.lagou.com 创建出来的 ...
- Python常用的库简单介绍一下
Python常用的库简单介绍一下fuzzywuzzy ,字符串模糊匹配. esmre ,正则表达式的加速器. colorama 主要用来给文本添加各种颜色,并且非常简单易用. Prettytable ...
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- [原创]关于mybatis中一级缓存和二级缓存的简单介绍
关于mybatis中一级缓存和二级缓存的简单介绍 mybatis的一级缓存: MyBatis会在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 利用Python进行数据分析(4) NumPy基础: ndarray简单介绍
一.NumPy 是什么 NumPy 是 Python 科学计算的基础包,它专为进行严格的数字处理而产生.在之前的随笔里已有更加详细的介绍,这里不再赘述. 利用 Python 进行数据分析(一)简单介绍 ...
- yii2的权限管理系统RBAC简单介绍
这里有几个概念 权限: 指用户是否可以执行哪些操作,如:编辑.发布.查看回帖 角色 比如:VIP用户组, 高级会员组,中级会员组,初级会员组 VIP用户组:发帖.回帖.删帖.浏览权限 高级会员组:发帖 ...
随机推荐
- 独立服务器 云主机、VPS以及虚拟主机三者之间的区别是什么?哪个更好?
https://www.zhihu.com/question/21442353#answer-2442764 云主机(如 EC2,[1] )和 VPS (如 Linode,[2])都是完整的操作系统( ...
- PHP网站常见安全漏洞,及相应防范措施总结
目前,基于PHP的网站开发已经成为目前网站开发的主流,本文笔者重点从PHP网站攻击与安全防范方面进行探究,旨在减少网站漏洞,希望对大家有所帮助! 一.常见PHP网站安全漏洞 对于PHP的漏洞,目前常见 ...
- 一简单的RPC实例(Java)
来至于阿里liangf:如有冒犯,请原谅 RPCFrameWork: package com.sunchao.demo; import java.io.IOException; import java ...
- css 好看的div文本框 渐变+ 背景 + 阴影 实际应用
效果图 css <style> .box{ padding: 3px 5px 3px 18px; margin: 3px 0 3px 5px; position: relative; li ...
- 微信小程序左右滑动切换图片酷炫效果(附效果)
开门见山,先上效果吧!感觉可以的用的上的再往下看. 心动吗?那就继续往下看! 先上页面结构吧,也就是wxml文件,其实可以理解成微信自己封装过的html,这个不多说了,不懂也没必要往下看了. < ...
- 2018年web前端学习路线图
前端的的技术一直在变化,更新和变革,现在基本是三驾马车(vue,angualr,react)主导整个前端框架,但是无论对于新人或者有经验的程序员,这些知识在必须掌握 前端必会技能 上图罗列了整个前端的 ...
- Mysql的主从配置
前言:这次学习分布式的思想要配置mysql的主从复制和读写分离,我在主从配置上踩到很多坑,在此演示一遍配置过程,并附上问题的说明和自己的一些见解 Mysql主从复制的原理 附上原理图: mysql的主 ...
- jsp页面取值
一般就用el表达式 ${recordList[4].baseRate8.split("/")[0] } <s:date name="recordList[#id]. ...
- html中的title和alt
alt是html标签的属性,而title既是html标签,又是html属性. title标签这个不用多说,网页的标题就是写在<title></title>这对标签之内的.tit ...
- web开发概述
1 Web概述 Web,在英语中表示网页的额意思,它用于表示Internet主机上供外界访问的资源. 2 Web的分类 按照服务器上的资源分类: 静态资源:指的是web页面中供人们浏览的数据是始终不变 ...