Scrapy-简单介绍
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
编写一个Scrapy项目需要以下几个简单的流程:
创建一个Scrapy项目
scrapy startproject projectName
cd projectName
scrapy genspider baidu baidu.com
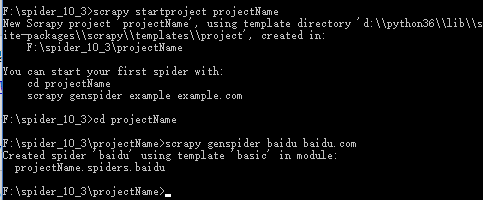
然后就会在你的集成化工具上出现创建的项目:
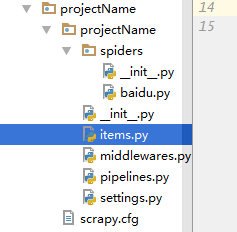
定义提取的Item(你需要爬取的数据的容器)
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
import scrapy
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['baidu.com']
start_urls = ['http://baidu.com/']
def parse(self, response):
#主要爬取代码编写区
pass
编写 Item Pipeline 来存储提取到的Item(即数据)
class ProjectnamePipeline(object):
def process_item(self, item, spider):
#对爬取到的数据进行处理
return item
运行项目
方法一:cmd命令行输入运行 Scrapy 项目
scrapy crawl baidu #这里的baidu是spider的名字不是项目名,是唯一的
方法二:.py文件运行 Scrapy 项目
创建 runBaidu.py 文件
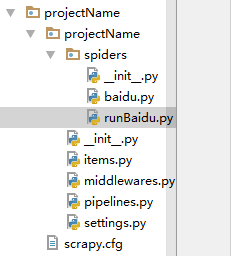
from scrapy import cmdline
cmdline.execute("scrapy crawl baidu".split())
Scrapy-简单介绍的更多相关文章
- Learning Scrapy笔记(一)- Scrapy简单介绍
Scrapy简述 Scrapy十一个健壮的,用来从互联网上抓取数据的web框架,Scrapy只需要一个配置文件就能组合各种组件和配置选项,并且Scrapy是基于事件(event-based)的架构,使 ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy -->CrawlSpider 介绍
scrapy -->CrawlSpider 介绍 1.首先,通过crawl 模板新建爬虫: scrapy genspider -t crawl lagou www.lagou.com 创建出来的 ...
- Python常用的库简单介绍一下
Python常用的库简单介绍一下fuzzywuzzy ,字符串模糊匹配. esmre ,正则表达式的加速器. colorama 主要用来给文本添加各种颜色,并且非常简单易用. Prettytable ...
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- [原创]关于mybatis中一级缓存和二级缓存的简单介绍
关于mybatis中一级缓存和二级缓存的简单介绍 mybatis的一级缓存: MyBatis会在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 利用Python进行数据分析(4) NumPy基础: ndarray简单介绍
一.NumPy 是什么 NumPy 是 Python 科学计算的基础包,它专为进行严格的数字处理而产生.在之前的随笔里已有更加详细的介绍,这里不再赘述. 利用 Python 进行数据分析(一)简单介绍 ...
- yii2的权限管理系统RBAC简单介绍
这里有几个概念 权限: 指用户是否可以执行哪些操作,如:编辑.发布.查看回帖 角色 比如:VIP用户组, 高级会员组,中级会员组,初级会员组 VIP用户组:发帖.回帖.删帖.浏览权限 高级会员组:发帖 ...
随机推荐
- dede的pagelist标签的listsize数字属性详解
转载▼http://blog.sina.com.cn/s/blog_a4f3bd4e01012c8n.html dede的pagelist标签的listsize数字属性详解.见远seo经常用织梦搭建各 ...
- 【开发技术】java异常的捕获与抛出原则
在可能会出现exception的地方,要使用try-catch或者throws或者两者都要.我的判断依据是:如果对可能出现的exception不想被外部(方法的调用者)知道,就在方法内部try-cat ...
- 2018/1/28 每日一学 单源最短路的SPFA算法以及其他三大最短路算法比较总结
刚刚AC的pj普及组第四题就是一种单源最短路. 我们知道当一个图存在负权边时像Dijkstra等算法便无法实现: 而Bellman-Ford算法的复杂度又过高O(V*E),SPFA算法便派上用场了. ...
- php foreach用法和实例
原文地址:http://www.cnblogs.com/DaBing0806/p/4717718.html foreach()有两种用法:1: foreach(array_name as $value ...
- linux_系统调优
linux如何调优? 1. 关闭SELLinux功能,美国国家安全局对于强制访问控制实现,生产场景也是关闭 cat /etc/selinux/config | grep '^SELINUX=' # 查 ...
- 重温MFC
1. Button控件 2. 旋转和高级编辑控件 3. 标签控件和属性页 4. 列表控件 5. 树控件 6. 进度条控件和滑动条控件 7. 滚动条 8.工具栏和状态栏
- Git: 本地创建版本库用于多处同步
问题背景 目前有一个 Android 和 一个 iOS 项目,两个项目底层使用相同的 C++ 代码.由于在开发迭代中代码时常更新,而且往往是今天 Android 部分修改一小部分,明天 iOS 部分修 ...
- HotSpot 虚拟机的算法实现
- win10 store 无法连接网络
当你试过所有的解决攻略 都无效时,那么使用这个教程 关闭以下的蓝色框里的
- 基于tomcat+springMVC搭建基本的前后台交互系统
一.摘要 1.所需软件列表: 1) tomcat : apache-tomcat-7.0.54 服务端容器 2) Intellij: Intellij IDEA 14.0.3 开发 ...