Java8学习(4)-Stream流
Stream和Collection的区别是什么
流和集合的区别是什么?
粗略地说, 集合和流之间的差异就在于什么时候进行计算。集合是一个内存中的数据结构,它包含数据结构中目前所有的值--集合中的每个元素都得先计算出来才能添加到内存里。(你可以往集合里加东西或者删东西,但是不管什么时候,集合中的每个元素都是放在内存里的,元素都得计算出来才能成为集合的一部分。)
相比之下,流则是在概念上固定的数据结构(你不能添加或者删除元素),其元素则是按需计算的。这对编程有很大的好处。用户仅仅从流中提取需要的值,而这些值--在用户看不见的地方--只会按需生成。这是一种生产者 - 消费者的关系。从另一个角度来说,流就像一个延迟创建的集合:只有在消费者要求的时候才会计算值。
Stream是内部迭代
一个明显的区别是迭代方式不同。Collection需要手动for-each或者使用Iterator在外部迭代。而Stream则开启后可以直接对单个元素进行操作,内部帮你做好了迭代工作。
内部迭代的好处是可一个更好的并行。自己手写迭代需要处理好每次迭代的内容。为了提高执行效率,也许会把多个处理逻辑写到同一个遍历里。比如,有同事看到从scala转过来的同事的代码,说他写的代码经常重复好多次。scala是函数式语言,和流天然集成。而我们惯性的做法,还是把一堆操作逻辑写到同一个循环体中,来满足自己对所谓的性能要求的洁癖。这常常会使得可读性变差。很厌烦阅读超过100行的代码,尤其代码还有首尾同步处理的逻辑(for, try-catch),很容易出错。多写一次循环来做这些事情,心理又过不去。
Stream开启流之后,系统内部会分析对元素的操作是否可以并行,然后合并执行。也就是说,看起来,自己filter-map-filter-map-group很多次,但真实执行的时候并不是遍历了很多次。至于到底遍历了多少次。这是一个好问题,后面会说明这个问题。
使用流Stream的注意事项
流只能消费一次。比如,foreach只能遍历一次stream。再次则会抛异常。
流操作
针对流的操作方式两种:
中间操作
可以连接起来的流操作叫做中间操作。诸如filter或map等中间操作会返回另一个流。这让多个操作可以连接起来形成一个查询。但是,除非调用一个终端操作,比如collect,foreach, 否则中间操作不会执行----它们很懒。这是因为中间操作一般可以合并起来,在终端操作时一次性全部处理。
终端操作
关闭流的操作叫做终端操作。终端操作会从流的流水线生成结果。
使用流
本文demo源码: https://github.com/Ryan-Miao/someTest/tree/master/src/main/java/com/test/java8/streams
新建一个Entity作为基本元素。
package com.test.java8.streams.entity;
/**
* Created by Ryan Miao on 12/11/17.
*/
public class Dish {
private final String name;
private final boolean vegetarian;
private final int calories;
private final Type type;
public Dish(String name, boolean vegetarian, int calories, Type type) {
this.name = name;
this.vegetarian = vegetarian;
this.calories = calories;
this.type = type;
}
public String getName() {
return name;
}
public boolean isVegetarian() {
return vegetarian;
}
public int getCalories() {
return calories;
}
public Type getType() {
return type;
}
public enum Type{
MEAT, FISH, OTHER
}
}
最常用,最简单的用法
Stream API支持许多操作,这些操作能让你快速完成复杂的数据查询,比如筛选、切片、映射、查找、匹配和归约。
package com.test.java8.streams;
import com.google.common.collect.Lists;
import com.test.java8.streams.entity.Dish;
import org.junit.Before;
import org.junit.Test;
import java.util.List;
import static java.util.stream.Collectors.toList;
/**
* Created by Ryan Miao on 12/11/17.
*/
public class StreamExample {
private List<Dish> menu;
@Before
public void setUp(){
menu = Lists.newArrayList(
new Dish("pork", false, 800, Dish.Type.MEAT),
new Dish("beef", false, 700, Dish.Type.MEAT),
new Dish("chicken", false, 400, Dish.Type.MEAT),
new Dish("french fries", true, 530, Dish.Type.OTHER),
new Dish("rice", true, 350, Dish.Type.OTHER),
new Dish("season fruit", true, 120, Dish.Type.OTHER),
new Dish("pizza", true, 550, Dish.Type.OTHER),
new Dish("prawns", false, 300, Dish.Type.FISH),
new Dish("salmon", false, 450, Dish.Type.FISH)
);
}
@Test
public void demo(){
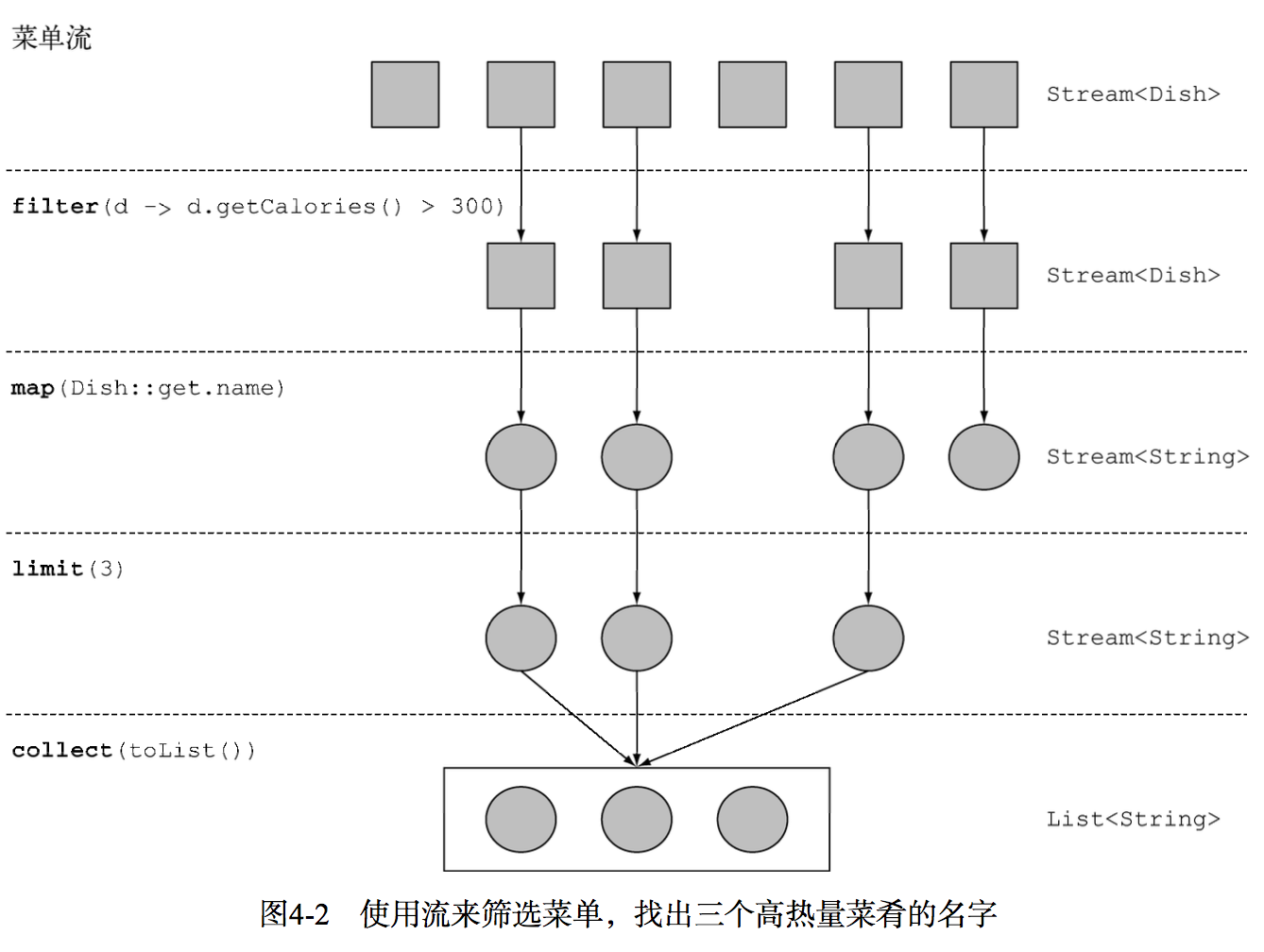
List<String> threeHighCaloricDishNames = menu.stream()
.filter(dish -> dish.getCalories() > 300)
.map(Dish::getName)
.limit(3)
.collect(toList());
System.out.println(threeHighCaloricDishNames);
}
}
stream()将一个集合转换成一个流,流和list一样,都是单元素的集合体。filter()接受一个布尔值lambda,即一个谓词。当表达式的value是true的时候,该元素通过筛选。map()接受一个转换lambda,将一个元素class映射成另一个class。collect收集器,汇总结果,触发流,终端操作。
谓词筛选filter
谓词是一个返回boolean的函数,也就是条件,通过这个条件进行筛选。
@Test
public void testFilterMapLimit(){
List<Entity> entities = Lists.newArrayList(new Entity(100), new Entity(12), new Entity(33), new Entity(41));
List<Integer> collect = entities.stream()
.filter(entity -> entity.getId() < 100)
.map(Entity::getId)
.collect(Collectors.toList());
System.out.println(collect);
}
这里,filter的参数就是一个谓词,配合filter,可以筛选结果,只有返回值是true的item会通过。
去重复distinct
distinct()
截短流limit
limit(n)
跳过元素skip
skip(n)。 通过limit(n)形成互补关系。
映射map
map, stream的核心操作。接收一个参数,用来把一个对象转换为另一个。demo同上。下面看具体需求。
/**
* Returns a stream consisting of the results of applying the given
* function to the elements of this stream.
*
* <p>This is an <a href="package-summary.html#StreamOps">intermediate
* operation</a>.
*
* @param <R> The element type of the new stream
* @param mapper a <a href="package-summary.html#NonInterference">non-interfering</a>,
* <a href="package-summary.html#Statelessness">stateless</a>
* function to apply to each element
* @return the new stream
*/
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
接收一个Function函数,然后返回Stream. 而Function在前面已经介绍过了。我们看核心的方法。
/**
* Represents a function that accepts one argument and produces a result.
*
* <p>This is a <a href="package-summary.html">functional interface</a>
* whose functional method is {@link #apply(Object)}.
*
* @param <T> the type of the input to the function
* @param <R> the type of the result of the function
*
* @since 1.8
*/
@FunctionalInterface
public interface Function<T, R> {
/**
* Applies this function to the given argument.
*
* @param t the function argument
* @return the function result
*/
R apply(T t);
}
Function函数的功能就是把参数转换成另一个类型的对象,返回。也就是a -> {return b;}。
瞥一眼Peek
上面map的需求特别多,但有时候我并不想返回另一个对象,我只是想要把原来的对象加工一个下,还是返回原来的对象。用map也是可以的,只要返回同一个对象就行。但IDEA会推荐用peek()。
比如,我想把list的user全部取出来,把updateDate更新为当前时间。
@Test
public void testPeek(){
final List<Integer> list = Lists.newArrayList(1,2,3,4);
List<Entity> collect = list.stream()
.map(Entity::new)
.peek(e -> e.setUpdateTime(new Date()))
.collect(Collectors.toList());
System.out.println(collect);
}
源码里是这样写的
/**
* Returns a stream consisting of the elements of this stream, additionally
* performing the provided action on each element as elements are consumed
* from the resulting stream.
*
* <p>This is an <a href="package-summary.html#StreamOps">intermediate
* operation</a>.
*
* <p>For parallel stream pipelines, the action may be called at
* whatever time and in whatever thread the element is made available by the
* upstream operation. If the action modifies shared state,
* it is responsible for providing the required synchronization.
*
* @apiNote This method exists mainly to support debugging, where you want
* to see the elements as they flow past a certain point in a pipeline:
* <pre>{@code
* Stream.of("one", "two", "three", "four")
* .filter(e -> e.length() > 3)
* .peek(e -> System.out.println("Filtered value: " + e))
* .map(String::toUpperCase)
* .peek(e -> System.out.println("Mapped value: " + e))
* .collect(Collectors.toList());
* }</pre>
*
* @param action a <a href="package-summary.html#NonInterference">
* non-interfering</a> action to perform on the elements as
* they are consumed from the stream
* @return the new stream
*/
Stream<T> peek(Consumer<? super T> action);
而Consumer同样也在之前出现过
@FunctionalInterface
public interface Consumer<T> {
/**
* Performs this operation on the given argument.
*
* @param t the input argument
*/
void accept(T t);
}
也就是说,peek()的本意是将对象取出来,消一遍,并不是像我的说的那样返回原对象,因为参数并不是Function, 而是Consumer。我之所以这么说是因为Function也可以做到这个功能,只要将返回值变为当前对象即可。而peek里,我们可以修改当前对象的属性,也是会生效的。
流的扁平化faltMap
我们前面讲的函数都是处理一个序列,一个list,一个Stream里的数据。如果一个Stream的元素也是另一个stream呢?我还想把这个Stream的元素的stream打散,最终输出一个stream。比如下面这个例子。统计单词列表中出现的字母。
final List<String> words = Lists.newArrayList( "Hello", "worlds");
List<String[]> rs = words.stream()
.map(w -> w.split(""))
.distinct()
.collect(Collectors.toList());
rs.forEach(e -> {
for (String i : e) {
System.out.print(i + ",");
}
System.out.println();
});
打印的结果为:
H,e,l,l,o,
w,o,r,l,d,s,
显然,目标没达到。map之后的stream已经变成Stream<Stream<String>>。应该如何把里面的Stream打开,最后拼接起来呢。最直观的想法就是用一个新的list,将我们刚才foreach打印的步骤中的操作变成插入list。但这显然不是函数式编程。
flatMap可以接收一个参数,返回一个流,这个流可以拼接到最外层的流。说的太啰嗦,看具体用法。
@Test
public void flatMap() {
final List<String> words = Lists.newArrayList( "Hello", "worlds");
List<String> collect = words.stream()
.map(w -> w.split(""))
.flatMap(a -> Arrays.stream(a))
.distinct()
.collect(Collectors.toList());
System.out.println(collect);
}
- 第一步,用map将一个String对象映射成String[]数组。
- 第二步,将这个返回的对象映射成Stream,这里的数组转Stream即
Arrays::stream. - 第三步,用flatMap
以上可以合并为一步: .flatMap(w -> Arrays.stream(w.split("")))
最终打印结果:
[H, e, l, o, w, r, d, s]
查找和匹配
另一个常见的数据处理套路是看看数据集中的某些元素是否匹配一个给定的属性。Stream API通过allMatch, anyMatch,noneMatch,findFirst,findAny方法提供了这样的工具。
比如,找到任何一个匹配条件的。
@Test
public void anyMatchTest() {
final List<Entity> entities = Lists.newArrayList(new Entity(101),
new Entity(12), new Entity(33), new Entity(42));
boolean b = entities.stream().anyMatch(e -> {
System.out.println(e.getId());
return e.getId() % 2 == 0;
});
if (b) {
System.out.println("有偶数");
}
}
101
12
有偶数
上述只是确定下是不是存在,在很多情况下这就够了。至于FindAny和FindFirst则是找到后返回,目前还没遇到使用场景。
归约Reduce
Google搜索提出的Map Reduce模型,Hadoop提供了经典的开源实现。在Java中,我们也可以手动实现这个。

reduce的操作在函数式编程中很常见,作用是将一个历史值与当前值做处理。比如求和,求最大值。
求和的时候,我们会将每个元素累加给sum。用reduce即可实现:
/**
* 没有初始值,返回Optional
*/
@Test
public void demo(){
OptionalInt rs = IntStream.rangeClosed(1, 100)
.reduce((left, right) -> {
System.out.println(left + "\t" + right);
return left + right;
});
if (rs.isPresent()){
System.out.println("===========");
System.out.println(rs.getAsInt());
}
}
打印结果为:
1 2
3 3
6 4
...
...
4851 99
4950 100
===========
5050
给一个初始值
int rs = IntStream.rangeClosed(1, 100)
.reduce(10, (a, b) -> a + b);
同样,可以用来求最大值。
List<Integer> nums = Lists.newArrayList(3, 1, 4, 0, 8, 5);
Optional<Integer> max = nums.stream().reduce((a, b) -> b > a ? b : a);
这里的比较函数恰好是Integer的一个方法,为增强可读性,可以替换为:
nums.stream().reduce(Integer::max).ifPresent(System.out::println);
接下来,回归我们最初的目标,实现伟大的Map-Reduce模型。比如,想要知道有多少个菜(一个dish list)。
@Test
public void mapReduce() {
final ArrayList<Dish> dishes = Lists.newArrayList(
new Dish("pork", false, 800, Type.MEAT),
new Dish("beef", false, 700, Type.MEAT),
new Dish("chicken", false, 400, Type.MEAT),
new Dish("french fries", true, 530, Type.OTHER),
new Dish("rice", true, 350, Type.OTHER),
new Dish("season fruit", true, 120, Type.OTHER),
new Dish("pizza", true, 550, Type.OTHER),
new Dish("prawns", false, 300, Type.FISH),
new Dish("salmon", false, 450, Type.FISH)
);
Integer sum = dishes.stream()
.map(d -> 1)
.reduce(0, (a, b) -> a + b);
}
归约的优势和并行化
相比于用foreach逐步迭代求和,使用reduce的好处在于,这里的迭代被内部迭代抽象掉了,这让内部实现得以选择并行执行reduce操作。而迭代式求和例子要更新共享变量sum,这不是那么容易并行化的。如果你加入了同步,很可能会发现线程竞争抵消了并行本应带来的性能提升!这种计算的并行化需要另一种方法:将输入分块,分块求和,最后再合并起来。但这样的话代码看起来就完全不一样了。后面会用分支/合并框架来做这件事。但现在重要的是要认识到,可变的累加模式对于并行化来说是死路一条。你需要一种新的模式,这正是reduce所提供的。传递给reduce的lambda不能更改状态(如实例变量),而且操作必须满足结合律才可以按任意顺序执行。
流操作的状态:无状态和有状态
你已经看到了很多的流操作,乍一看流操作简直是灵丹妙药,而且只要在从集合生成流的时候把Stream换成parallelStream就可以实现并行。但这些操作的特性并不相同。他们需要操作的内部状态还是有些问题的。
诸如map和filter等操作会从输入流中获取每一个元素,并在输出流中得到0或1个结果。这些操作一般是无状态的:他们没有内部状态(假设用户提供的lambda或者方法引用没有内部可变状态)。
但诸如reduce、sum、max等操作需要内部状态来累积结果。在前面的情况下,内部状态很小。在我们的例子里就是一个int或者double。不管流中有多少元素要处理,内部状态都是有界的。
相反,诸如sort或distinct等操作一开始都和filter和map差不多--都是接受一个流,再生成一个流(中间操作), 但有一个关键的区别。从流中排序和删除重复项都需要知道先前的历史。例如,排序要求所有元素都放入缓冲区后才能给输出流加入一个项目,这一操作的存储要求是无界的。要是流比较大或是无限的,就可能会有问题(把质数流倒序会做什么呢?它应当返回最大的质数,但数学告诉我们他不存在)。我们把这些操作叫做有状态操作。
注
以上内容均来自《Java8 In Action》。
Java8学习(4)-Stream流的更多相关文章
- 【Java8新特性】面试官问我:Java8中创建Stream流有哪几种方式?
写在前面 先说点题外话:不少读者工作几年后,仍然在使用Java7之前版本的方法,对于Java8版本的新特性,甚至是Java7的新特性几乎没有接触过.真心想对这些读者说:你真的需要了解下Java8甚至以 ...
- Java8中的Stream流式操作 - 入门篇
作者:汤圆 个人博客:javalover.cc 前言 之前总是朋友朋友的叫,感觉有套近乎的嫌疑,所以后面还是给大家改个称呼吧 因为大家是来看东西的,所以暂且叫做官人吧(灵感来自于民间流传的四大名著之一 ...
- 这可能是史上最好的 Java8 新特性 Stream 流教程
本文翻译自 https://winterbe.com/posts/2014/07/31/java8-stream-tutorial-examples/ 作者: @Winterbe 欢迎关注个人微信公众 ...
- java8 新特性Stream流的应用
作为一个合格的程序员,如何让代码更简洁明了,提升编码速度尼. 今天跟着我一起来学习下java 8 stream 流的应用吧. 废话不多说,直入正题. 考虑以下业务场景,有四个人员信息,我们需要根据性 ...
- Java8新特性 Stream流式思想(二)
如何获取Stream流刚开始写博客,有一些不到位的地方,还请各位论坛大佬见谅,谢谢! package cn.com.zq.demo01.Stream.test01.Stream; import org ...
- Java8系列 (二) Stream流
概述 Stream流是Java8新引入的一个特性, 它允许你以声明性方式处理数据集合, 而不是像以前的指令式编程那样需要编写具体怎么实现. 比如炒菜, 用指令式编程需要编写具体的实现 配菜(); 热锅 ...
- java8学习之Stream实例剖析
继续操练Stream,直接上代码: 而咱们要返回ArrayList,显示可以用构造引用来传递到里面,因为它刚好符合Supplier函数式接口的特性:不接收参数返回一个值,所以: 接下来试着将Strea ...
- Java8新特性 Stream流式思想(一)
遍历及过滤集合中的元素使用传统方式遍历及过滤集合中的元素package cn.com.zq.demo01.Stream.test01.Stream; import java.util.ArrayLis ...
- Java8新特性 Stream流式思想(三)
Stream接口中的常用方法 forEach()方法package cn.com.cqucc.demo02.StreamMethods.Test02.StreamMethods; import jav ...
随机推荐
- 【BZOJ1911】【APIO2010】特别行动队(斜率优化,动态规划)
[BZOJ1911][APIO2010]特别行动队 题面 Description 你有一支由 n 名预备役士兵组成的部队,士兵从 1 到 n 编号, 要将他们拆分成若干特别行动队调入战场.出于默契的考 ...
- 【Luogu3768】简单的数学题(莫比乌斯反演,杜教筛)
[Luogu3768]简单的数学题(莫比乌斯反演,杜教筛) 题面 洛谷 \[求\sum_{i=1}^n\sum_{j=1}^nijgcd(i,j)\] $ n<=10^9$ 题解 很明显的把\( ...
- HNOI2008玩具装箱
斜率优化 # include <stdio.h> # include <stdlib.h> # include <iostream> # include <s ...
- eclipse 精确查询
---恢复内容开始--- ctrl+H(一般都是这个,如果无效看你的自定义快捷键) 输入\b 查询的字符串 \b 后面的正则表达式选框必须选
- MPTCP iperf 发包方式
之前用的发包方式是发送大文件,用NC监测. 今天改了另外一种发包方式iperf,简单记录下. iperf发包,具体方法: 1.在终端中运行拓扑脚本: 运行py脚本:sudo python topy.p ...
- 索信达携手8Manage,打造项目管理系统信息化体系
[导语]金融大数据已逐渐成为行业潮流,作为金融大数据应用提供商,深圳索信达企业为了实现业务和研发项目的多重管理需求,决定引入8Manage项目管理系统,提高项目管控能力和工作效率,从而提高企业的核心竞 ...
- C++通过COM接口操作PPT
一. 背景 在VS环境下,开发C++代码操作PPT,支持对PPT模板的修改.包括修改文本标签.图表.表格.满足大多数软件生成PPT报告的要求,先手工创建好PPT模板,在程序中修改模板数据. 二. 开发 ...
- office 2013补丁包更新
总是有客户发现使用office 2013 下的插件有问题,这个问题出现在低版本上,所以要给office 2013打上补丁,打上后,运行插件ok,出现的bug解决掉了.那么给office打补丁包就成了解 ...
- sdk安装
转自:https://www.cnblogs.com/smyhvae/p/4390905.html 安装sdk:(包解压到哪里就是sdk的安装目录 P.S.安装目录不能有空格,要是之前有空格换了目 ...
- 内嵌tomcat启动速度慢
项目上最近要把内置的jetty换成tomcat, 来更好的支持servlet 3.0 本来以为换个容器, 几十行代码就好了. 实际上换了tomcat后, 一开始启动tomcat, 非常的慢. jett ...