MySQL多数据源笔记4-Mycat中间件实战
Mycat 是数据库中间件,就是介于数据库与应用之间,进行数据处理与交互的中间服 务。由于前面讲的对数据进行分片处理之后,从原有的一个库,被切分为多个分片数据库,所有的分片数据库集 群构成了整个完整的数据库存储。
如下图:
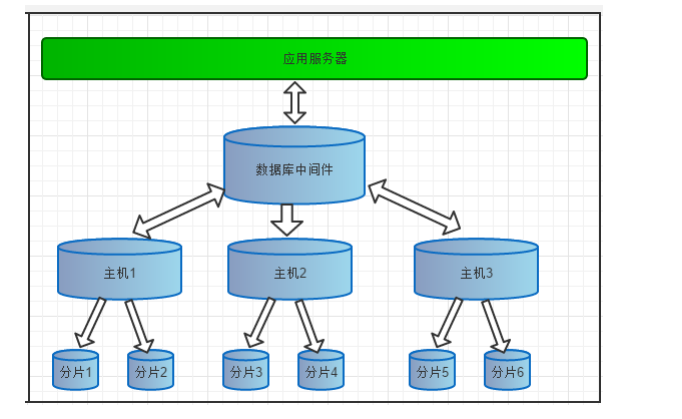
如上图所表示,数据被分到多个分片数据库后,应用如果需要读取数据,就要需要处理多个数据源的数据。
如果没有数据库中间件,那么应用将直接面对分片集群,数据源切换、事务处理、数据聚合都需要应用直接处 理,原本该是专注于业务的应用,将会花大量的工作来处理分片后的问题,最重要的是每个应用处理将是完全的 重复造轮子。
所以有了数据库中间件,应用只需要集中与业务处理,大量的通用的数据聚合,事务,数据源切换都由中间 件来处理,中间件的性能与处理能力将直接决定应用的读写性能,所以一款好的数据库中间件至关重要。
第一部MyCat的环境搭建。
首先去官网下载MyCat,官网地址为:dl.mycat.io
注意必须下载发行版,也就是说带有RELEASE字眼的就是发行版,BETA是测试版。选择windows版本来学习即可。
我们主要关注的是MyCat的conf目录如下图:
我们打开schema.xml文件中看一下里面的配置都是些什么意思:配置文件如下:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="">
<!-- auto sharding by id (long) -->
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" /> <!-- global table is auto cloned to all defined data nodes ,so can join
with any table whose sharding node is in the same data node -->
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
<table name="goods" primaryKey="ID" type="global" dataNode="dn1,dn2" />
<!-- random sharding using mod sharind rule -->
<table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3"
rule="mod-long" />
<!-- <table name="dual" primaryKey="ID" dataNode="dnx,dnoracle2" type="global"
needAddLimit="false"/> <table name="worker" primaryKey="ID" dataNode="jdbc_dn1,jdbc_dn2,jdbc_dn3"
rule="mod-long" /> -->
<table name="employee" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile" />
<table name="customer" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id"
parentKey="id">
<childTable name="order_items" joinKey="order_id"
parentKey="id" />
</childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id"
parentKey="id" />
</table>
<!-- <table name="oc_call" primaryKey="ID" dataNode="dn1$0-743" rule="latest-month-calldate"
/> -->
</schema>
<!-- <dataNode name="dn1$0-743" dataHost="localhost1" database="db$0-743"
/> -->
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<!--<dataNode name="dn4" dataHost="sequoiadb1" database="SAMPLE" />
<dataNode name="jdbc_dn1" dataHost="jdbchost" database="db1" />
<dataNode name="jdbc_dn2" dataHost="jdbchost" database="db2" />
<dataNode name="jdbc_dn3" dataHost="jdbchost" database="db3" /> -->
<dataHost name="localhost1" maxCon="" minCon="" balance=""
writeType="" dbType="mysql" dbDriver="native" switchType="" slaveThreshold="">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root"
password="">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="192.168.1.200:3306" user="root" password="xxx" />
</writeHost>
<writeHost host="hostS1" url="localhost:3316" user="root"
password="" />
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password=""/> -->
</dataHost>
<!--
<dataHost name="sequoiadb1" maxCon="" minCon="" balance="" dbType="sequoiadb" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="sequoiadb://1426587161.dbaas.sequoialab.net:11920/SAMPLE" user="jifeng" password="jifeng"></writeHost>
</dataHost> <dataHost name="oracle1" maxCon="" minCon="" balance="" writeType="" dbType="oracle" dbDriver="jdbc"> <heartbeat>select from dual</heartbeat>
<connectionInitSql>alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'</connectionInitSql>
<writeHost host="hostM1" url="jdbc:oracle:thin:@127.0.0.1:1521:nange" user="base" password="" > </writeHost> </dataHost> <dataHost name="jdbchost" maxCon="" minCon="" balance="" writeType="" dbType="mongodb" dbDriver="jdbc">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM" url="mongodb://192.168.0.99/test" user="admin" password="" ></writeHost> </dataHost> <dataHost name="sparksql" maxCon="" minCon="" balance="" dbType="spark" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="jdbc:hive2://feng01:10000" user="jifeng" password="jifeng"></writeHost> </dataHost> --> <!-- <dataHost name="jdbchost" maxCon="" minCon="" balance="" dbType="mysql"
dbDriver="jdbc"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1"
url="jdbc:mysql://localhost:3306" user="root" password=""> </writeHost>
</dataHost> -->
</mycat:schema>
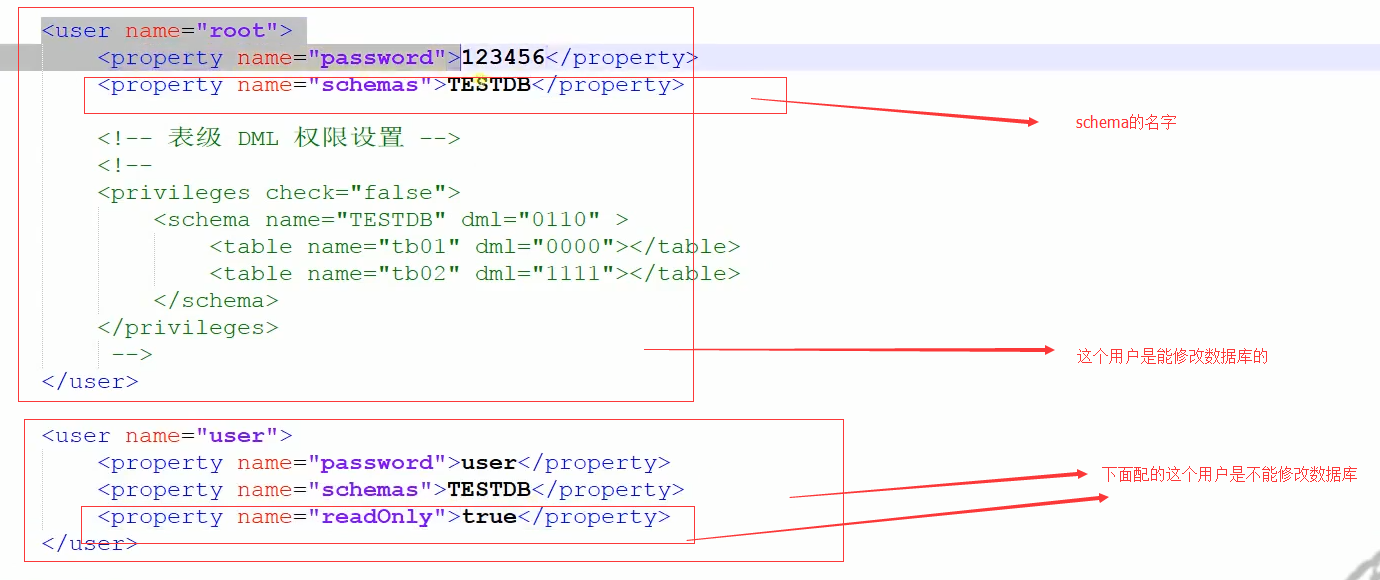
schema 标签用于定义 MyCat 实例中的逻辑库,MyCat 可以有多个逻辑库,每个逻辑库都有自己的相关配 置。可以使用 schema 标签来划分这些不同的逻辑库。 如果不配置 schema 标签,所有的表配置,会属于同一个默认的逻辑库。
对于我们开发人员来说,我们知道连接到mycat的逻辑库,后面拖着多少个MySQL我们不管的,我们只需要连接到MyCat这个逻辑库,对于后面的分库分表,MyCat给我们屏蔽了分库分表的复杂性。
table 标签定义了 MyCat 中的逻辑表,所有需要拆分的表都需要在这个标签中定义。
table标签里面的子标签childTabel表示这个表跟父table分在一起,不会被拆散,也就是前面所说的分库分表之前,要考虑好表的关联,不然否则就面临跨库Join连接问题。
如下代码:
<table name="customer" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id"
parentKey="id">
<childTable name="order_items" joinKey="order_id"
parentKey="id" />
</childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id"
parentKey="id" />
</table>
table中的type属性的global表示该表为全局表。即前面所提到每一个节点可以读到这个表,这对是否在分库分表中的join查询很关键。而且这属性表示不会进行分片,即全局表使用,每个节点都有。代码如下:
<table name="goods" primaryKey="ID" type="global" dataNode="dn1,dn2" />
table中的dataNode属性表示你要分片,要分到那几个节点上去,rule代表着分库分表的规则。他的分片分表规则在rule.xml文件中,你可以在Table标签的rule属性设置复合
自己的分片分表规则,都在rule.xml中对应着如下图:


<dataNode>标签,标签中的name属性表示节点的名字。dataHost属性表示对应MySQL的数据库连接,database属性表示Mysql数据库名,代码如下:
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataHost>标签节点表示对应MySQL的数据库连接对应配置,什么最大连接数,最小连接数之类的属性。
<dataHost>标签中的子标签<hearbeat>表示存活检测,
<dataHost>标签中的子标签<writeHost>和<readHost>表示MySQL中的读写分离,而<writeHost>子标签中还有<readHost>子标签,表示写操作的数据库还要承担一部分读库的压力。
代码如下:
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root"
password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="192.168.1.200:3306" user="root" password="xxx" />
</writeHost>
<writeHost host="hostS1" url="localhost:3316" user="root"
password="123456" />
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
下面进行读写分离的演示:
第一步先注释schma里面的配置如下图:

接着在修改<dataNode>,<dataHost>节点信息,详细信息在图中说明。如下图:

接着再还要修改mycat中server.xml文件,我这里没有使用zookeeper所以要把zookeeper协调切换关闭。因为我们只是在本地玩,如下图:

接着在继续修改server.xml文件。如下图:
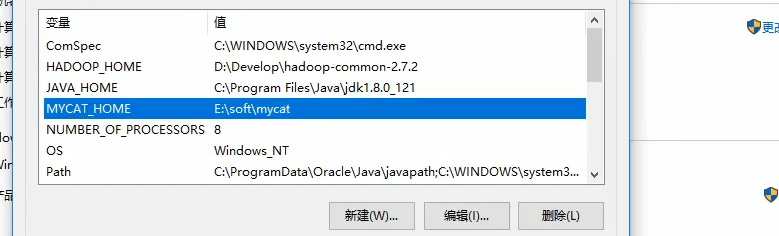
接着就是启动了,启动之前要进行环境变量设置如下:
接着就是设置一起启动参数了,在startup_newrap.bat文件中修改如下图:
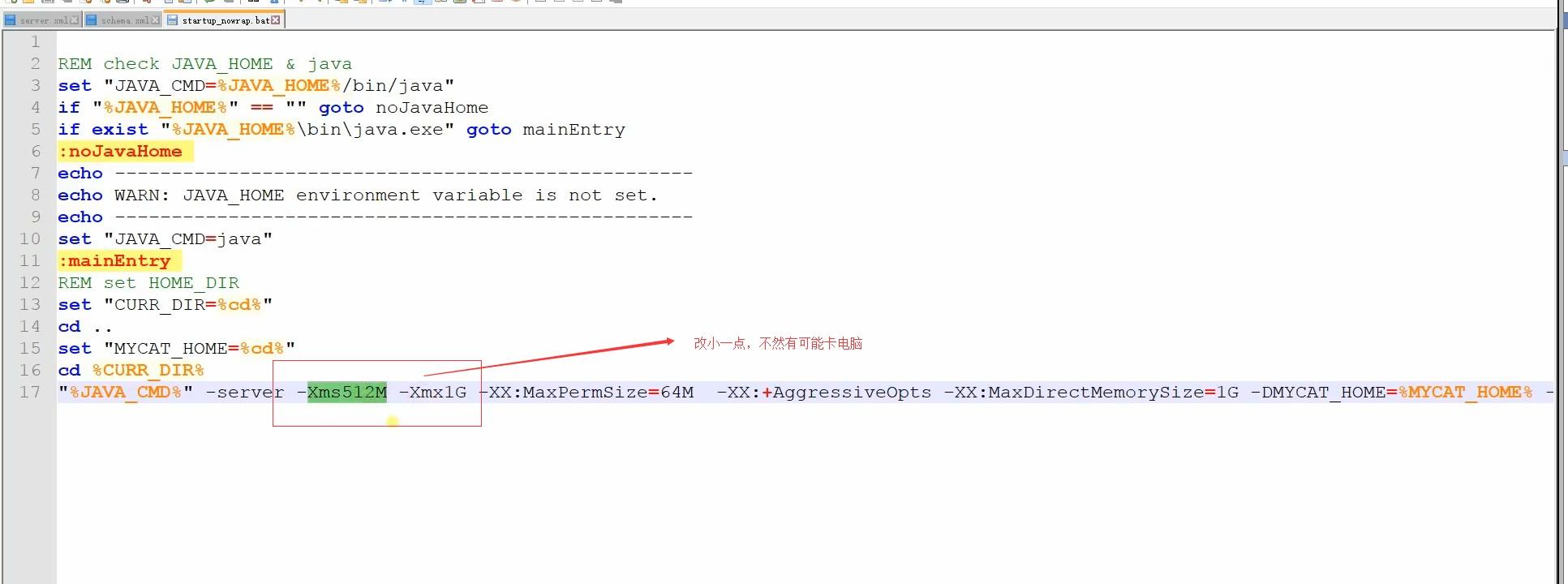
接着就是启动了,如下:
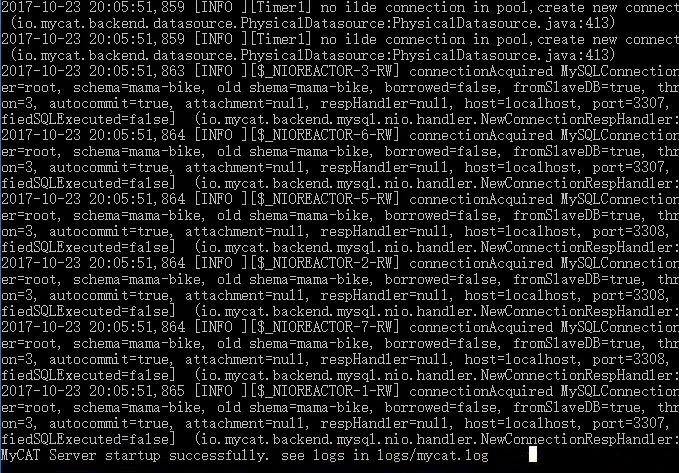
接着就是用图形化工具连接MyCat了。如下图:
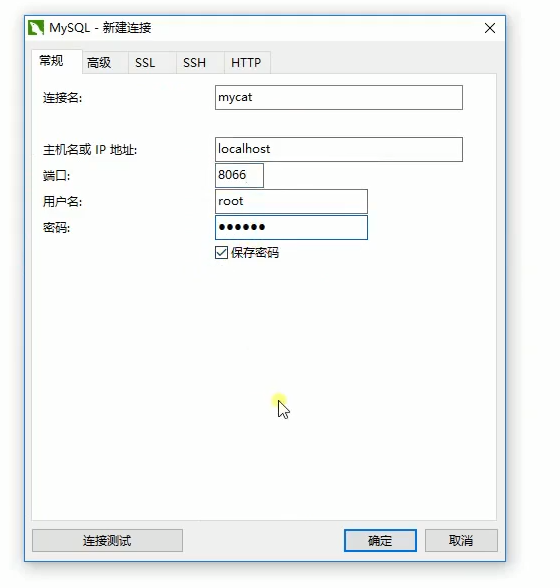
接着自己在图形化界面中修改数据库,这里就不演示了。如下:
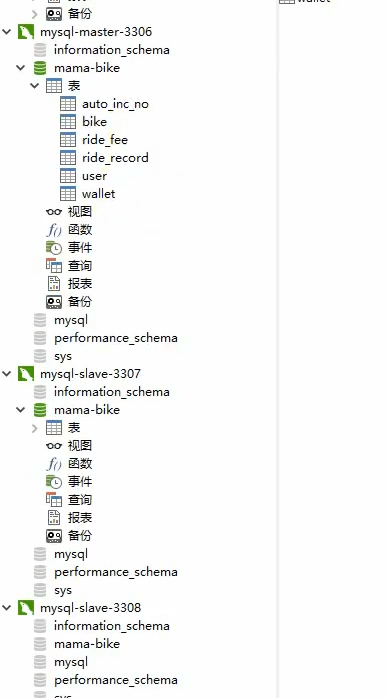
接着mycat进行分库分表演示:
注意一定要在每一个mysql中建立好tabel标签对应的travelrecord表,而表中必须要有id这属性,
如下图:
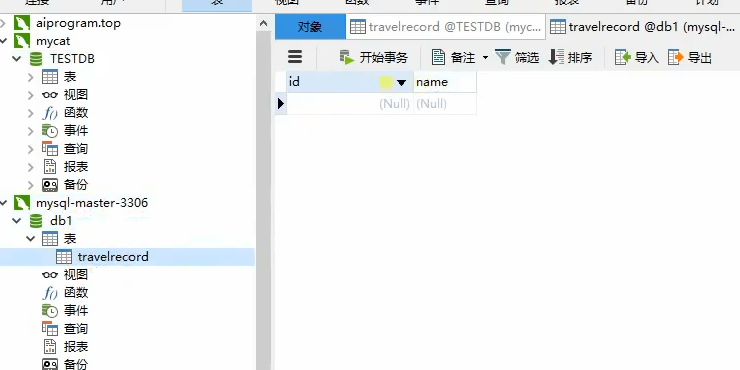

注意一定要在每一个mysql中建立好tabel标签对应的travelrecord表,而表中必须要有id这属性,因为上面的分库分表策略是根据id分的,在rule.xml中找到分表策略如下:
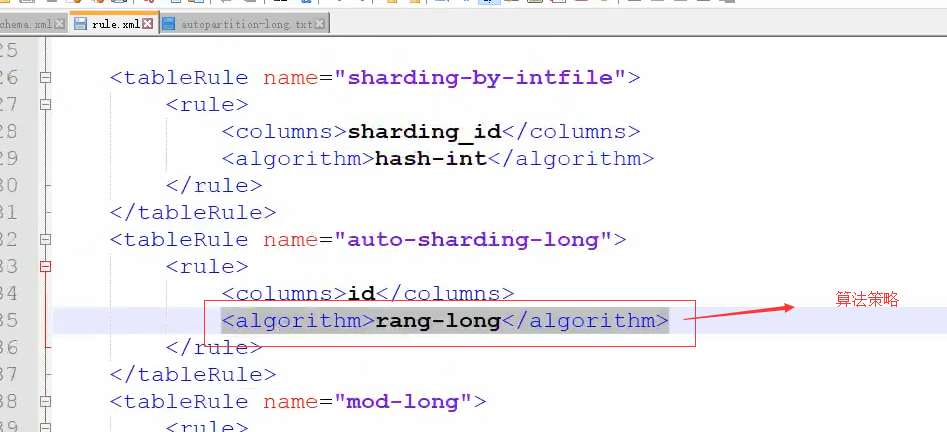
在根据rang-long在rule.xml找到对应的function,如下图:

在找到autoparitition-long.txt文件,看到如下分库分表了,如下图:

然后在分别对应修改dataNode和dataHost标签,如下图:

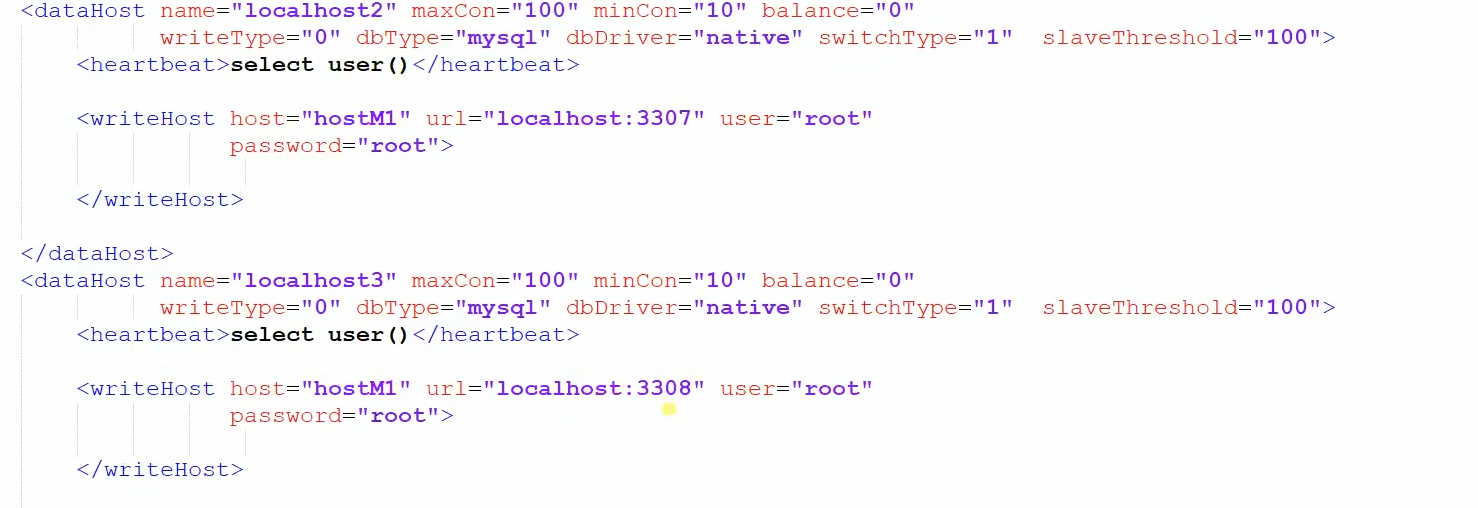
最后进行分库分表测试
比如490M=4900000分到第0个节点,在mycat总设置,如下图:

接着去查看第0个节点会有一条数据分到这里,其他节点没有。
如果使用上面的分库分表策略不能超过范autoparitition-long.txt里面配置的范围的。
其他的分配策略,还可以用CRC32slot策略类似于redis集群中的Slot,如下:

还可以用rang-mod求模来分,如下:


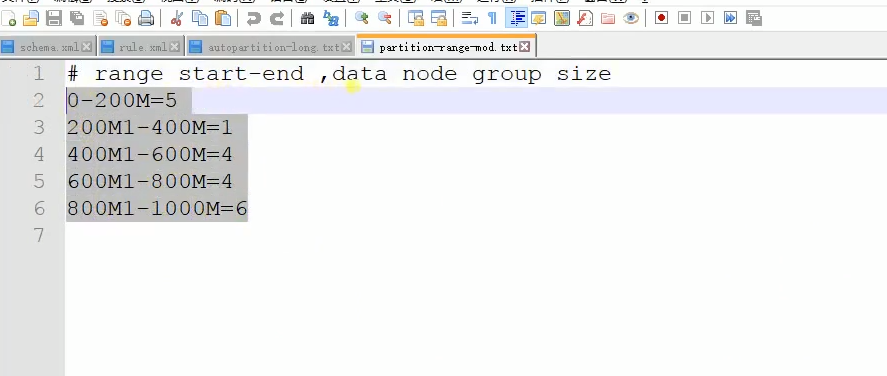
然后找partition-range-mod.txt,可以具体,如下:
其他就不演示了。
MySQL多数据源笔记4-Mycat中间件实战的更多相关文章
- MySQL多数据源笔记3-分库分表理论和各种中间件
一.使用中间件的好处 使用中间件对于主读写分离新增一个从数据库节点来说,可以不用修改代码,达到新增节点数据库而不影响到代码的修改.因为如果不用中间件,那么在代码中自己是先读写分离,如果新增节点, 你进 ...
- MySQL多数据源笔记5-ShardingJDBC实战
Sharding-JDBC集分库分表.读写分离.分布式主键.柔性事务和数据治理与一身,提供一站式的解决分布式关系型数据库的解决方案. 从2.x版本开始,Sharding-JDBC正式将包名.Maven ...
- MySQL多数据源笔记2-Spring多数据源一主多从读写分离(手写)
一.为什么要进行读写分离呢? 因为数据库的"写操作"操作是比较耗时的(写上万条条数据到Mysql可能要1分钟分钟).但是数据库的"读操作"却比"写操作 ...
- MySQL多数据源笔记1-MySQL主从复制
1.为什么要做主从复制? 1.在业务复杂的系统中,有这么一个情景,有一句sql语句需要锁表,导致暂时不能使用读的服务,那么就很影响运行中的业务,使用主从复制,让主库负责写,从库负责读,这样,即使主库出 ...
- 高可用Mysql架构_Mysql主从复制、Mysql双主热备、Mysql双主双从、Mysql读写分离(Mycat中间件)、Mysql分库分表架构(Mycat中间件)的演变
[Mysql主从复制]解决的问题数据分布:比如一共150台机器,分别往电信.网通.移动各放50台,这样无论在哪个网络访问都很快.其次按照地域,比如国内国外,北方南方,这样地域性访问解决了.负载均衡:M ...
- Mycat 中间件配置初探与入门操作
Mycat中间件配置初探与入门操作 By:授客 QQ:1033553122 实践环境 Mycat-server-1.5.1-RELEASE-20161130213509-win.tar.gz 下载地址 ...
- Mycat中间件
数据库中间件Mycat自我介绍 一.mycat概述 1.功能介绍 mycat一个开源的分布式数据库系统,是一个实现了mysql协议的server前端用户可以把它看成一个数据库代理,用mysql客户端工 ...
- MySQL分布式集群之MyCAT(一)简介【转】
隔了好久,才想起来更新博客,最近倒腾的数据库从Oracle换成了MySQL,研究了一段时间,感觉社区版的MySQL在各个方面都逊色于Oracle,Oracle真的好方便!好了,不废话,这次准备记录一些 ...
- MyCat中间件:读写分离(转)
利用MyCat中间件实现读写分离 需要两步: 1.搭建MySQL主从复制环境 2.配置MyCat读写分离策略 一.搭建MySQL主从环境 参考上一篇博文:MySQL系列之七:主从复制 二.配置MyCa ...
随机推荐
- 使用FFMPeg对视频进行处理
FFMPeg处理视频的核心操作方式是命令,无论是在Windows上还是Linux上.那么下边就简单介绍下,常见的处理命令. 示例1:截取一张352×240尺寸大小的,格式为jpg的图片: ffmpeg ...
- 1.10 tuple 元组
元组(tuple)属于不可变序列 tuple特性: 特性一:可包含任意对象的有序集合 特性二:通过下标索引访问元素 特性三:固定长度,异质,可任意嵌套 特性四:不支持原位改变 特性五:存储机制:对象引 ...
- PendingIntent
PendingIntent表示一种即将发生的意图,和Intent的区别在于:PendingIntent是在将来的某个不确定的时刻发生,而Intent是立刻发生 典型使用场景是给RemoteViews添 ...
- NJU 1010 Air
思路:把那张图打表(吐血...),然后就按照规则输出就行. AC代码 #include <cstdio> #include <cmath> #include <cctyp ...
- Redux:从action到saga
前端应用消失的部分 一个现代的.使用了redux的前端应用架构可以这样描述: 一个存储了应用不可变状态(state)的store 状态(state)可以被绘制在组件里(html或者其他的东西).这个绘 ...
- Markdown语法你都会了吗?
关于Markdown,它可以说是程序员公认最好的文档语言了,没有之一!我相信经常写文章或者开发文档的大佬们都对其能生成简洁.大方.雅观的文档都深有体会,它的强大是毋庸置疑的.它编写的文档不但能生成ht ...
- C# 枚举特性 FlagAttribute 的应用
写在前面 枚举Enum 全称(Enumeration),即一种由一组称为枚举数列表的命名常量组成的独特类型.可以看出枚举的出现时为了使我们可以在程序中方便的使用一些特定值的常量,一般的使用大家都比较熟 ...
- 如何构造一个简单的USB过滤驱动程序
本文分三部分来介绍如何构造一个简单的USB过滤驱动程序,包括"基本原理"."程序的实现"."使用INF安装".此文的目的在于希望读者了解基本 ...
- VxWorks启动流程
镜像种类不同,VxWorks的启动过程会有所不同. 我们项目中使用的是加载型VxWorks镜像 函数 函数功能 所在文件 bootTask() (a) 通过createBootLineFromF ...
- HighCharts之2D柱状图、折线图的组合双轴图
HighCharts之2D柱状图.折线图的组合双轴图 1.实例源码 DoubleAxis.html: <!DOCTYPE html> <html> <head> & ...