MySQL 复制 - 性能与扩展性的基石 2:部署及其配置

正所谓理论造航母,现实小帆船。单有理论,不动手实践,学到的知识犹如空中楼阁。接下来,我们一起来看下如何一步步进行 MySQL Replication 的配置。
为 MySQL 服务器配置复制非常简单。但由于场景不同,基本的步骤还是有所差异。最基本的场景是新安装主库和备库,总得来说分为以下几步:
- 在每台服务器上创建复制账号。
- 配置主库和备库。
- 通知备库连接到主库并从主库复制数据。
此外,由于主备部署需要多台服务器,但是这种要求对大多数人来说并不怎么友好,毕竟没有必要为了学习部署主备结构,多买个云服务器。因此,为了测试方便,我们通过 docker 容器技术在同台机器上部署多个容器,从而实现在一台机器上部署主备结构。
这里我们先假定大部分配置采用默认值,在主库和备库都是全新安装并且拥有同样的数据。接下来,我们将展示如何通过 docker 技术一步步进行复制配置。
此外,我们将推荐一些“安全配置”,以便在不清楚如何配置时,确保数据的安全。
1 部署 docker 环境
1) 部署 docker
什么?docker 还没部署?赶紧参考这里配一个,docker 都没玩,怎么和面试官吹水呀!
2) 拉取 MySQL 镜像
docker pull mysql:5.7
3) 使用 mysql 镜像启动容器
docker run -p 3339:3306 --name mysql-master -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7 # 启动 master 容器
docker run -p 3340:3306 --name mysql-slave -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7 # 启动 slave 容器
master 对外的端口是 3339,slave 对外的端口是 3340,我们在使用客户端连接要使用对应的端口连接对应 mysql。
4) 使用命令查看正在运行的容器
docker ps

5) 使用客户端连接工具测试丽连接 mysql
2 配置 Master 和 Slave
1) 配置 master
通过以下命令进入容器内部
docker exec -it mysql-master /bin/bash
a) 更新 apt-get 源
apt-get update
b) 安装 vim
apt-get install vim
c) 配置 my.cnf
vim /etc/mysql/my.cnf
// 在my.cnf 中添加如下配置
[mysqld]
server-id=110 # 服务器 id,同一局域网内唯一
log-bin=/var/lib/mysql/mysql-bin # 二进制日志路径
d) 重启 mysql 服务使配置生效
service mysql restart
e) 启动容器
重启 mysql 服务时会使得 docker 容器停止,需要重启容器。
docker start mysql-master
f) 创建数据同步用户并授权
CREATE USER 'slave'@'%' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO 'slave'@'%';
2) 配置 slave
通过以下命令进入容器内部
docker exec -it mysql-slave /bin/bash
a) 配置 my.cnf
vim /etc/mysql/my.cnf
// 在my.cnf 中添加如下配置
[mysqld]
server-id=120 # 服务器 id,同一局域网内唯一
log-bin=/var/lib/mysql/mysql-bin # 二进制日志路径
relay_log=/path/to/logs/relay-bin # 中继日志路径
3) 关联 master 和 slave
配置完 master 和 slave,接下来就要让 master 和 slave 相关联。
回到我们的服务器,先找出 master 和 slave 容器的 IP,执行:
docker inspect --format='{{.NetworkSettings.IPAddress}}' mysql-master

因此,我们知道了 mysql-master 容器的 IP 是:172.17.0.3。同样的方法,mysq-slave 容器的 IP 是:172.17.0.4。记住这两个值,后面的配置需要用到。
我们首先配置 master。在 master 容器内通过 mysql -u root -p 进入 MySQL 命令行,执行 show master status;

上图中,File 和 Position 字段对应的值要记录下来,后续在 slave 配置时需要用到这两个值。要注意的是,记录完这两个值后,就不能在 master 库上做任何操作,否则会出现数据不同步的情况。
接下来配置 slave,同样的,在 slave 上进入 MySQL 命令行。然后执行下面语句:
change master to master_host='172.17.0.3', master_user='slave', master_password='123456', master_port=3306, master_log_file='mysql-bin.000001', master_log_pos=42852, master_connect_retry=30;
change master to 是 slave 配置 master 的命令,相关参数含义如下:
- master_host:master 的IP,就是我们上面获取的 IP 地址
- master_port:master 的端口号,也就是我们 master mysql 的端口号
- master_user:进行数据同步的用户
- master_password:同步用户的密码
- master_log_file:指定 slave 从 master 的哪个日志文件开始复制数据,也就是我们上面提到的 File 字段的值
- master_log_pos:从 master 日志文件的那个位置开始读,上面提到的 Position 字段的值
- master_connect_retry:重试时间间隔。单位是秒,默认 60
3 启动复制
配置完 slave 后,可以通过 show slave status\G; 查看 slave 的状态。
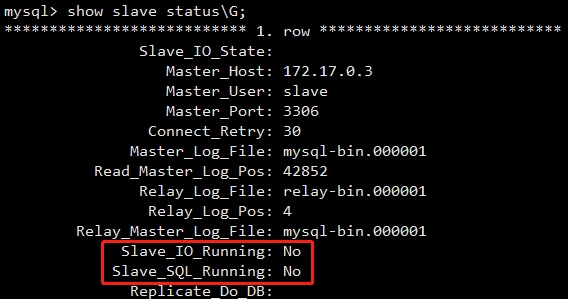
正常情况下,刚配置完 slave 的 Slave_IO_Running 和 Slave_SQL_Runing 都是 NO,因为我们还没开启主从复制。使用 start slave 开启主从复制,然后再查下 slave 状态。
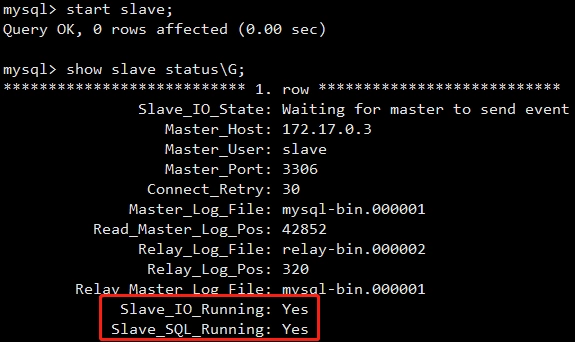
slave 的 Slave_IO_Running 和 Slave_SQL_Runing 都是 YES,说明主从复制已成功启动。此时,可以通过客户端能否成功复制数据。
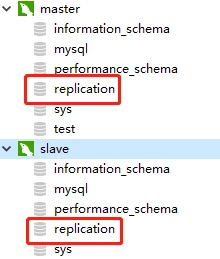
我们在 master 新建 replication 库,然后观察 slave 库是否创建了 replication 库,如下图,表示复制成功。
另外,开启主从复制后,如果出现以下情况:
Slave_IO_Running: CONNECTING
Slave_SQL_RUNNING: Yes
表示开启主从复制后, slave 的 IO 进程连接 master 出现问题,一直在重试连接。我们可以根据 Last_IO_Error 的提示进行解决:
- 网络不通。检查 IP、port。
- 密码错误。检查配置的同步用户和密码是否正确。
- pos 错误。检查 slave 配置的 Position 的值 与 master 是否一致。
4 从另一个服务器开始复制
前面的设置都是假定主备库均为刚刚安装好且都是默认的数据,也就是说两台服务器上数据相同,并且知道当前主库的二进制日志。但在实际环境中,大多数情况下是有一个一级运行了一段时间的主库,然后用一台新安装的备库与之同步,此时这台备库还没有数据。
有几种方法来初始化备库或者从其他服务器克隆数据到备库。包括从主库复制数据、从另外一台备库克隆数据,以及使用最近的一次备份来启动备库等。而这些方法都需要有三个条件来让主库与备库保持同步:
- 在某个时间点的主库的数据快照。
- 主库当前的二进制日志文件,和获得数据快照时在该二进制日志文件中的偏移量。我们把这两个值称为日志文件坐标(log file coordinates)。通过这两个值可以确定二进制日志的位置。可以通过 SHOW MASTER STATUS 命令来获取这些值。
- 从快照时间到现在的二进制日志。
下面是一些从别的服务器克隆备库的方法:
- 使用冷备份。最基本的方法是关闭主库,把数据复制到备库。重启主库后,会使用一个新的二进制日志文件,我们在备库通过执行 CHANGE MASTER TO 指向这个文件的起始处。不过这个方法的缺点很明显:在复制数据时需要关闭主库。
- 使用热备份。如果仅使用了 MyISAM 表,可以在主库运行时使用 mysqlhotcopy 或 rsync 来复制数据。
- 使用 mysqldump。如果只包含 InnoDB 表,可以使用以下命令来转储主库数据并将其加载到备库,然后设置相应的二进制日志坐标:mysqldump --single-transaction --all-databases --master-data=1 --host=server1 | mysql --host=server2。选项 --single-transaction 使得转储的数据为事务开始前的数据。如果使用的是非事务型表,可以使用 --lock-all-tables 选项来获得所有表的一致性转储。
- 使用快照或备份。只要知道对应的二进制日志坐标,就可以使用主库的快照或者备份来初始化备库。(如果使用备份,需要确保从备份的时间点开始的主库二进制日志都要存在)。只需要把备份或快照恢复到备库,然后使用 CHANGE MASTER TO 指定二进制日志的坐标。
- 使用 Percona Xtrabackup。Percona 的 Xtrabackup 是一款开源的热备份工具。它能够在备份时不阻塞服务器的操作,因此可以在不影响主库的情况下设置备库。可以通过克隆主库或另一个已存在的备库的方式来建立备库。
- 使用另外的备库。可以使用任何一种克隆或拷贝技术从任意一台备库上将数据克隆到另外一台服务器。但是如果使用的是 mysqldump,--master-data 选项就会不起作用。此外,不能使用 SHOW MASTER STATUS 来获得主库的二进制日志坐标,而是在获取快照时使用 SHOW SLAVE STATUS 来获取备库在主库上的执行位置。使用另外的备库进行数据克隆最大的缺点是,如果这台备库的数据已经和主库不同步,克隆得到的就是脏数据。
5 推荐的复制配置
我们知道,MySQL 的复制有许多参数可以控制,其中一些会对数据安全和性能产生影响。这里,我们介绍一种“安全配置”,可以最小化问题发生的概率。
在主库上二进制日志最重要的选项是 sync_binlog:
sync_binlog=1
如果开启该选项,MySQL 每次在提交事务前会将二进制日志同步到磁盘上,保证在服务器崩溃时不会丢失时间。如果禁止该选项,服务器会少做一些工作,但二进制日志文件可能在服务器崩溃时损坏或丢失信息。在一个不需要作为主库的备库上 ,该选项会带来不必要的开销。要注意的是,它只适用于二进制日志,而非中继日志。
如果无法接受服务器崩溃导致表损坏,推荐使用 InnoDB。MyISAM 表在备库服务器崩溃重启后,可能已经处于不一致状态。
如果使用 InnoDB,推荐设置如下选项:
innodb_flush_logs_at_trx_commit=1 # 每次事务提交时,将 log buffer 写入到日志文件并刷新到磁盘。默认值为 1
innodb_safe_binlog
明确指定二进制日志文件的名称。当服务器间转移文件、克隆新的备库、转储备份或者其他场景下,如果以服务器名来命名二进制日志可能会导致很多问题。因此,我们需要给 log_bin 选项指定一个参数。
log_bin=/var/lib/mysql/mysql-bin
在备库上,同样开启如下培训,为中继日志指定绝对路径:
relay_log=/path/to/logs/relay-bin
skip_slave_start
read_only
通过设置 relay_log 可以避免中继日志文件基于机器名来命名,防止之前提到的可能在主库上发生的问题。而 skip_slave_start 选项能够阻止备库在崩溃后自动启动复制,以留出时间修复可能发生的问题。read_only 选项可以阻止大部分用户更改非临时表。
6 小结
- 复制初始化配置三部曲:创建账号、配置主备库、备库连接到主库开始复制;
- 从已有服务器复制时,可用热备份或 mysqldump 命令进行备份;
- 在不确定相关配置时,选择最安全的配置准没错;
MySQL 复制 - 性能与扩展性的基石 2:部署及其配置的更多相关文章
- MySQL 复制 - 性能与扩展性的基石:概述及其原理
原文:MySQL 复制 - 性能与扩展性的基石:概述及其原理 1. 复制概述 MySQL 内置的复制功能是构建基于 MySQL 的大规模.高性能应用的基础,复制解决的基本问题是让一台服务器的数据与其他 ...
- MySQL 复制 - 性能与扩展性的基石 1:概述及其原理
1. 复制概述 MySQL 内置的复制功能是构建基于 MySQL 的大规模.高性能应用的基础,复制解决的基本问题是让一台服务器的数据与其他服务器保持同步. 接下来,我们将从复制概述及原理.复制的配置. ...
- MySQL 复制 - 性能与扩展性的基石 3:常见问题及解决方案
主备复制过程中有很大可能会出现各种问题,接下来我们就讨论一些比较普遍的问题,以及当遇到这些问题时,如何解决或者预防问题发生. 1 数据损坏或丢失 问题描述:服务器崩溃.断电.磁盘损坏.内存或网络错误等 ...
- MySQL 复制 - 性能与扩展性的基石 4:主备切换
一旦使用 MySQL 的复制功能,就很大可能会碰到主备切换的情况.也许是为了迭代升级服务器,或者是主库出现问题时,将一台备库转换成主库,或者只是希望重新分配容量.不过出于什么原因,都需要将新主库的信息 ...
- Java并发编程:性能、扩展性和响应
1.介绍 本文讨论的重点在于多线程应用程序的性能问题.我们会先给性能和扩展性下一个定义,然后再仔细学习一下Amdahl法则.下面的内容我们会考察一下如何用不同的技术方法来减少锁竞争,以及如何用代码来实 ...
- Zend server最大化应用程序的性能、扩展性和可用性
如果我有8个小时去砍到一棵树,我会花6个小时磨斧子”——林肯(美国总统) 你可以知道? 世界页面访问量的峰值超过7000万每分钟. CloudFare公司服务器问题,导致785000站点崩溃一小时. ...
- 深入NGINX:我们如何设计它的性能和扩展性
为了更好地理解设计,你需要了解NGINX是如何工作的.NGINX之所以能在性能上如此优越,是由于其背后的设计.许多web服务器和应用服务器使用简单的线程的(threaded).或基于流程的 (proc ...
- idou老师教你学Istio 04:Istio性能及扩展性介绍
Istio的性能问题一直是国内外相关厂商关注的重点,Istio对于数据面应用请求时延的影响更是备受关注,而以现在Istio官方与相关厂商的性能测试结果来看,四位数的qps显然远远不能满足应用于生产的要 ...
- MySQL - 扩展性 1 概述:人多未必力量大
我们应该接触过或者听说过数据库的性能瓶颈问题.对于一个单机应用而言,提升数据库性能的最快路径就是氪金 - 买更高性能的数据库服务器,只要钱到位,性能不是问题. 但是当系统性能增加到一定地步时,你会发现 ...
随机推荐
- GNSS相关网站汇总
转载: https://blog.csdn.net/zzh_my/article/details/78449972 一.bernese 数据表文件下载 ftp://nfs.kasi.re.kr rin ...
- DDGScreenShot—图片擦除功能
写在前面 图片擦除功能,也是运用图片的绘制功能, 将图片绘制后,拿到相应的图片.当然,有一涨底图更明显 实现代码如下 /** ** 用手势擦除图片 - imageView --传图片 - bgView ...
- 分布式任务调度平台XXL-JOB
<分布式任务调度平台XXL-JOB> 一.简介 1.1 概述 XXL-JOB是一个轻量级分布式任务调度框架,其核心设计目标是开发迅速.学习简单.轻量级.易扩展.现已开放源代码并 ...
- lambda隐藏函数的嵌套
# 隐藏函数嵌套 f = (lambda a,b :a if a>b else b)(1000, 2000008) print((lambda a,g:a if a > g else g) ...
- OC和Swift中的UITabBar和UINaviGationBar的适配 [UITabbar在IPad中的适配]
作者 sundays http://www.cnblogs.com/sundaysgarden/ OC中UITabbar的适配[iphoneX和Ipad适配] 自定可以UITabar 自定义UITab ...
- mysql的SQL_NO_CACHE(在查询时不使用缓存)和sql_cache用法
转自:http://www.169it.com/article/5994930453423417575.html 为了测试sql语句的效率,有时候要不用缓存来查询. 使用 SELECT SQL_NO_ ...
- namespace------------https://www.cnblogs.com/linhaifeng/p/6657119.html
PHP支持两种抽象的访问当前命名空间内部元素的方法,__NAMESPACE__ 魔术常量和namespace关键字. 常量__NAMESPACE__的值是包含当前命名空间名称的字符串.在全局的,不包括 ...
- springboot数据库连接池使用策略
springboot官方文档介绍数据库连接池的使用策略如下: Production database connections can also be auto-configured using a p ...
- java thread yield 的设计目的是什么?
如题,java thread yield 的设计目的是什么?有什么实际应用场景吗? Ps:它的作用是理解的,和 join 等的区别也理解.就是个人感觉这个设计有点鸡肋(可能是个人读书太少...) It ...
- 使用单进程、strace、gdb调试PHP错误
使用单进程.strace.gdb调试PHP错误 PHP一般是在FPM的呵护下运行的,但是某些情况下进程异常崩溃会导致502.下面是解决思想: 1. 单进程运行: php -d display_erro ...