使用EHPC实现“完美并行”的高效批处理方案
使用EHPC实现“完美并行”的高效批处理方案
在高性能计算场景中,用户一次业务计算可以划分为大量的任务,每个任务的处理逻辑相同,但是输入文件、参数设置和输出文件不同。由于每个任务处理逻辑相似,执行时彼此没有依赖,按照高性能计算的并行计算模式,可归为 “embarrassing parallel”一类(又被称为完美并行问题),这类问题很少或根本不需要将问题分成许多并行任务的工作,通这些并行任务之间很少或没有依赖或需要通信,这类问题有一个另外的名称,叫做“批处理”,是高性能计算领域最“完美”的一种场景。在此,给出了基于阿里云弹性高性能计算场景的数组作业解决方案——利用E-HPC集成的作业调度系统,将用户的批处理任务自动分配到数组作业,实现在云超算集群上高并发执行。同时,依靠“云”弹性,动态扩展集群的计算资源,控制批处理的完成时间。
背景介绍
本节先通过一个示例介绍批处理的场景,然后讨论高性能计算集群以及数组作业。
批处理
在高性能计算领域中,存在大批量、可同时处理的计算场景,如以下freebayes应用场景,不同任务均使用freebayes应用程序,但是每个任务处理不同的输入文件(--bam-list)、不同的参数(-r)和不同的结果文件(--vcf)。由于作业量巨大,需要任务的并发执行,以缩短任务处理时间。

高性能计算集群与数组作业介绍
高性能计算集群是将大量的计算节点通过网络互联,进行统一的管理和调度,为大规模应用运行提供计算环境,包括账号管理、调度管理、文件系统、集群监控等模块。
由于集群包含大量计算节点,通常为多个用户共同使用,每个用户可以提交多个作业,每个作业需要一个或多个计算节点。集群资源的分配是由调度管理协调,以避免资源使用冲突,常用的调度管理软件包括PBS,Slurm,SGE,LSF等。
数组作业是一组作业的集合,可以执行一条提交作业的命令,提交作业集合中的所有作业,每个作业用各自的index取值进行区分。
如使用PBS调度器提交1个数组作业,文件名为 qjob.sh,内容如下:
#!/bin/bash
#PBS -N arrjob # 作业名称
#PBS -l nodes=1:ppn=1 # 每个作业需要1个计算节点,每个节点1个核的资源
#PBS -J 1-3 # 数组作业的作业编号为1,2,3
echo $PBS_ARRAY_ID # 每个作业的编号在PBS_ARRAY_ID 环境变量中qjob.sh脚本定义了一个数组作业,包含3个作业。作业编号范围用-J指定,取值为1-3。在具体作业执行时,每个作业的编号通过环境变量$PBS_ARRAY_ID获取。通过以下命令就可以提交qjob.sh 作业:
qsub ./qjob.sh此时,创建了3个作业,而作业能否立刻执行,需要调度器根据集群空闲资源和作业的资源需求来定。若资源充裕,3个作业可以同时运行。
使用数组作业解决批处理任务
从批处理和数组作业介绍看,数组作业适用批处理计算的场景,但做到简易使用,还存在以下问题:
- 批处理任务与作业的对应关系?当任务数量巨大时,是一个任务就是一个作业,还是一个作业包含多个任务?
- 如何从
$PBS_ARRAY_ID到不同任务的关联?并能够方便对应不同任务的不同参数? - 如何跟踪任务的执行情况?如何方便查看任务日志?在个别任务执行失败后,如何能够快速的筛选,并在调整后重新执行?
为此,我们给出使用数组作业解决批处理的方案,包括批处理任务到作业分配、批处理任务定义和任务运行及追踪功能。
批处理任务到作业分配
当批处理任务数目巨大时,如果每个任务都分配一个作业,调度器的负载就加重,虽然调度器能够显示不同作业的运行状态,作业数目过大,也会导致查看不方便。此外,相邻任务在一个节点执行,如果使用相同文件,可以重用节点的本地缓存。
为此,若任务数为Nt,作业数为Nj,每个作业处理的任务数为 Nt/Nj,如果不能整除,作业编号小于Nt%Nj的作业多处理一个任务。如之上批处理任务,如果Nt/Nj=2,但不能整除,作业编号小的作业会处理3个任务,而编号大的作业,会处理2个任务。
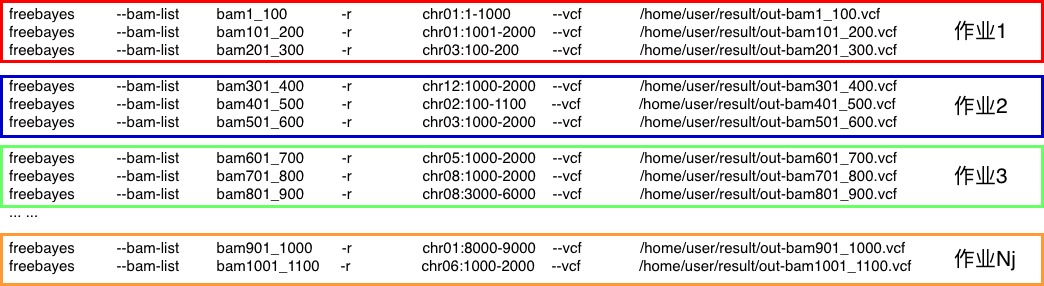
批处理任务定义
从批处理任务示例中我们可以看出,每个任务进行部分参数不同,若将这些变化的部分用变量代替,则批处理任务的处理脚本为(存放在文件 task.sh中):
$ cat task.sh
#!/bin/bash
echo "process $bamlist and $chrvar"
#other shell commands 如通过cd $bamlist
freebayes --bam-list $bamlist -r $chrvar --vcf /home/user/result/out-$bamlist.vcf
ret=$? # 保留主要程序的退出状态
# other shell commands
# ... ...
exit $ret # 任务执行状态,0为成功,非0表示失败其中,用$bamlist表示 --bam-list 选项的变化取值和--vcf参数取值的变化部分,用$chrvar表示 -r选型的变化取值。
将具体变化的取值,存储在变量名同名的文件中,每一行代表不同的取值,示例中有2个变量,因此需要两个文件——bamlist和chrvar。
$ cat bamlist
bam1_100
bam101_200
bam201_300
bam301_400
bam401_500
bam501_600
bam601_700
bam701_800
bam801_900
... ...
bam901_1000
bam1001_1100$ cat chrvar
chr01:1-1000
chr01:1001-2000
chr03:100-200
chr12:1000-2000
chr02:100-1100
chr03:1000-2000
chr05:1000-2000
chr08:1000-2000
chr08:3000-6000
... ...
chr01:8000-9000
chr06:1000-2000任务运行与追踪
在批处理任务定义后之后,需要实现任务与作业映射、变量文件的解析和赋值。这些通用功能,E-HPC提供了ehpcarrayjob.py python 脚本,进行处理,数组作业的脚本名若为qjob.sh,其内容为:
$ cat qjob.sh
#!/bin/bash
PBS -N bayes.job
#PBS -l nodes=1:ppn=1
#PBS -J 1-Nj
cd $PBS_O_WORKDIR # 表示打开提交作业的目录。
python ehpcarrayjob.py -n Nj -e ./task.sh bamlist chrvar通过qsub命令提交到集群上,有PBS进行调度,实现批量执行(其中Nj为作业的数目,根据需求进行替换)。
$ python ehpcarrayjob.py -h
usage: ehpcarrayjob.py [-h] -n NJOBS -e EXECFILE argfiles [argfiles ...]
positional arguments:
argfiles
optional arguments:
-h, --help show this help message and exit
-n NJOBS, --njobs NJOBS
number of jobs
-e EXECFILE, --execfile EXECFILE
job command file其中:
-n表示有多少个作业
-e指明每个任务的处理脚本(需要带路径)
argfiles 一个或多个,指定多个参数文件。
作业提交后,数组作业会分配一个作业id,如“1[].manager”,每个子作业都有自己的子作业编号,如从1-Nj。
ehpcarrayjob.py会生成以”作业id“为名的目录(如1[].manager),每个子作业在该目录下有“log.子作业编号”命名的日志文件,记录每个作业的执行情况。
当任务的返回作状态为非0(失败)时,会将任务变量的取值在”作业id“目录下记录到名为”fails.变量名.子作业编号“的文件中。待确定失败原因,修改处理脚本后,方便重新提交作业。
总结
站在用户的角度,每次数值计算任务来了,除了要划分好批量的任务,即使有遗留的脚本,还需要改写每个任务的处理脚本。
此外,还要面对以下运行场景的问题:
这次计算需要多少资源?
到那里找这些资源?
任务能运行起来吗,出错了怎么找原因?
任务会不会重算、漏算?
机器利用能不能衔接上,会不会出现长时间空闲?
使用阿里云弹性高性能计算(E-HPC)的批处理处理方案可以解决以上问题,让工作更专注。
可以看出,借助E-HPC方案用户仅需要通过以下几个步骤:
- 将批处理任务中变化的取值提取出来,单独存储到一个文件中,文件名符合shell规范,如bamlist, chrvar。
- 编写任务处理的脚本,使用变量名(文件名同名)替换任务中的变化取值,如task.sh。
- 编写数组作业脚本,指明每个作业的资源需求,总作业数,调用 ehpcarrayjob.py启动批处理任务执行,如qjob.sh。
用qsub提交作业,进入”作业id“的目前查看任务处理进度以及又问题的任务列表。作业的运行状态根据集群的资源状态进行判断,如果集群节点充足,所有作业均可以运行;如果资源不满足,少量作业可以先执行。
同时E-HPC“云”超算方案还有以下优势:
- 具备HPC集群原有特性,方便用户登陆集群进行编译和调试单个任务的处理逻辑,并通过E-HPC内置应用级监控模块集谛进行监控、分析、优化应用运行行为。
- 借助E-HPC,可以直接将配置好的环境扩展到新加的计算节点上。同时,使用低配置的登陆和管控节点长久保留已配置环境。
- 根据当前的任务处理效率,在“云”上动态地更换计算实例类型,并扩充计算资源来调整任务的处理时间,以应对紧急的任务处理。
原文链接
本文为云栖社区原创内容,未经允许不得转载。
使用EHPC实现“完美并行”的高效批处理方案的更多相关文章
- JavaScript 将行结构数据转化为树结构数据源(高效转化方案)
js接收到后台的数据如下 /// 部门信息 var departRows = [{ parentDepartId: 'root', departId: 'DC', departName: '集团' } ...
- mysql高效分页方案及原理
很久以前的一次面试中,被面试官问到这个问题,由于平时用到的分页方法不多,只从索引.分表.使用子查询精准定位偏移以外,没有使用到其它方法. 后来在看其它博客看到了一些不同的方案,也一直没有整理.今天有时 ...
- 高效update方案
--方案1:如果有索引,先把索引删除后,再update,最后把索引重新创建一下因为索引对update影响很大. --方案2:1.create table newA as select id,name, ...
- JavaScript 将行结构数据转化为树形结构,可提供给常用的tree插件直接使用(高效转化方案)
前台接收到的数据格式 var rows=[{ parent: 'root', id: 'DC', title: '集团' }, { parent: 'DC', id: '01', title: '上海 ...
- Laravel 处理 Options 请求的原理以及批处理方案
0. 背景 在前后端分离的应用中,需要使用CORS完成跨域访问.在CORS中发送非简单请求时,前端会发一个请求方式为OPTIONS的预请求,前端只有收到服务器对这个OPTIONS请求的正确响应,才会发 ...
- vscode + vim 全键盘操作高效搭配方案
基础知识 vscode-vim vscode-vim是一款vim模拟器,它将vim的大部分功能都集成在了vscode中,你可以将它理解为一个嵌套在vscode中的vim. 由于该vim是被模拟的的非真 ...
- [源码解析] 模型并行分布式训练 Megatron (4) --- 如何设置各种并行
[源码解析] 模型并行分布式训练 Megatron (4) --- 如何设置各种并行 目录 [源码解析] 模型并行分布式训练 Megatron (4) --- 如何设置各种并行 0x00 摘要 0x0 ...
- Radmin Server-3.5 完美绿色破解版(x32 x64通用) 第三版 + 单文件制作方法
Radmin Server v3.5 汉化破解绿色版(x32 x64通用) 第三版 下载链接: https://pan.baidu.com/s/1qYVcSQo 2016年7月8日更新第三版1.修复在 ...
- bat批处理完成jdk tomcat的安装
在完成一个web应用项目后,领导要求做一个配置用的批处理文件,能够自动完成jdk的安装,tomcat的安装,web应用的部署,环境变量的注册,tomcat服务的安装和自动启动 参考了网上很多的类似的批 ...
随机推荐
- BZOJ_1026_[SCOI2009]windy数_数位DP
BZOJ_1026_[SCOI2009]windy数_数位DP 题意:windy定义了一种windy数.不含前导零且相邻两个数字之差至少为2的正整数被称为windy数. windy想知道, 在A和B之 ...
- [NOIP2002]字串变换 T2 双向BFS
题目描述 已知有两个字串 A,B 及一组字串变换的规则(至多6个规则): A1−>B1 A2−>B2 规则的含义为:在 A$中的子串 A1可以变换为可以变换为B1.A2可以变换为可 ...
- Centos打开、关闭、结束tomcat,及查看tomcat运行日志
cd到tomcat目录下之后 启动:一般是执行sh bin/startup.sh 停止:一般是执行sh bin/shutdown.sh查看:执行ps -ef |grep tomcat 输出如下 *** ...
- Layer 使用
官网文档 http://layer.layui.com/mobile/api.html 1.需要添加jquery的引用然后是 loadExtentFile("css", " ...
- Windows环境下springboot集成redis的安装与使用
一,redis安装 首先我们需要下载Windows版本的redis压缩包地址如下: https://github.com/MicrosoftArchive/redis/releases 连接打开后如下 ...
- AWVS12 介绍和安装详解 -- For Windows10
一.AWVS介绍: Acunetix Web Vulnerability Scanner,简称:AWVS,是一个自动化的Web安全测试工具,它可以扫描Web站点和Web应用. AWVS可以快速扫描SQ ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Eclipse连接Hadoop集群及WordCount实践
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.环境准备 1.JDK安装与配置 2.Eclipse下载 下载解压即可,下载地址:https://pan.baidu.com/s/1i51UsVN ...
- 基于promise对小程序http请求方法封装
原因是我不想每次请求都复制粘贴那么长的请求地址,所以我把前边那一坨请求地址作为基础地址,只传后台给的路由就ok,而且,并不是每次请求都要显示正在加载,这对小程序体验很差,所以,我加了个形参,用来判断是 ...
- ansible工具
关于ansible 在ansible官网上是这样介绍ansible的:Ansible is an IT automation tool. It can configure systems, deplo ...