搭建centos7的开发环境3-Spark安装配置
说起大数据开发,必然就会提到Spark,在这片博文中,我们就介绍一下Spark的安装和配置。
这是Centos7开发环境系列的第三篇,本篇的安装会基于之前的配置进行,有需要的请回复搭建centos7的开发环境1-系统安装及Python配置、搭建centos7的开发环境2-单机版Hadoop2.7.3配置。
安装Spark
这里说明一下各种软件的版本号:
open-JDK: 1.8.0
Hadoop: 2.7.3
scala: 2.11.8
Spark: 2.1.0
scala
- 下载 sacla2.11.8
- 解压安装,并配置环境变量
tar -zxvf scala-2.11.8.tgzsudo mv scala-2.11.8 /usr/scala
spark
- 下载 spark 2.1.0
- 解压安装,并配置环境变量
tar -zxvf spark-2.1.0-bin-hadoop2.7.tgzsudo mv spark-2.1.0 /usr/sparkvim /etc/profile========================export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"SCALA_HOME=/usr/scalaexport PATH=$PATH:$SCALA_HOME/binSPARK_HOME=/usr/sparkexport PATH=$SPARK_HOME/bin:$PATH========================source /etc/profile###########################export SCALA_HOME=/usr/scalaexport JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el7_3.x86_64export SPARK_MASTER_IP=127.0.0.1export SPARK_LOCAL_IP=127.0.0.1export SPARK_WORKER_MEMORY=1gexport HADOOP_CONF_DIR=/usr/hadoop/etc/hadoop
配置完成之后,启动命令
/usr/hadoop/sbin/start-all.sh
/usr/spark/sbin/start-all.sh
打开链接 http://127.0.0.1:8080/,现在可以看到:

在终端分别输入spark-shell和pyspark都运行正常。
wordcount测试
创建数据集
在spark官网拷贝了一个网页作为数据源创建words.txt作为输入数据,并导入hdfs.
touch words.txtvim words.txtcd /usr/hadoop/sbinhadoop fs -mkdir hdfs://localhost:9000/inputhadoop fs -put /home/kejun/words.txt hdfs://localhost:90000/inputpyspark
现在进入pyspark的界面:
textFile=sc.textFile("hdfs://localhost:9000/input/words.txt")counts = textFile.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)counts.saveAsTextFile("hdfs://localhost:9000/input/out")
在hdfs的filesystem可以下载到wordcount结果
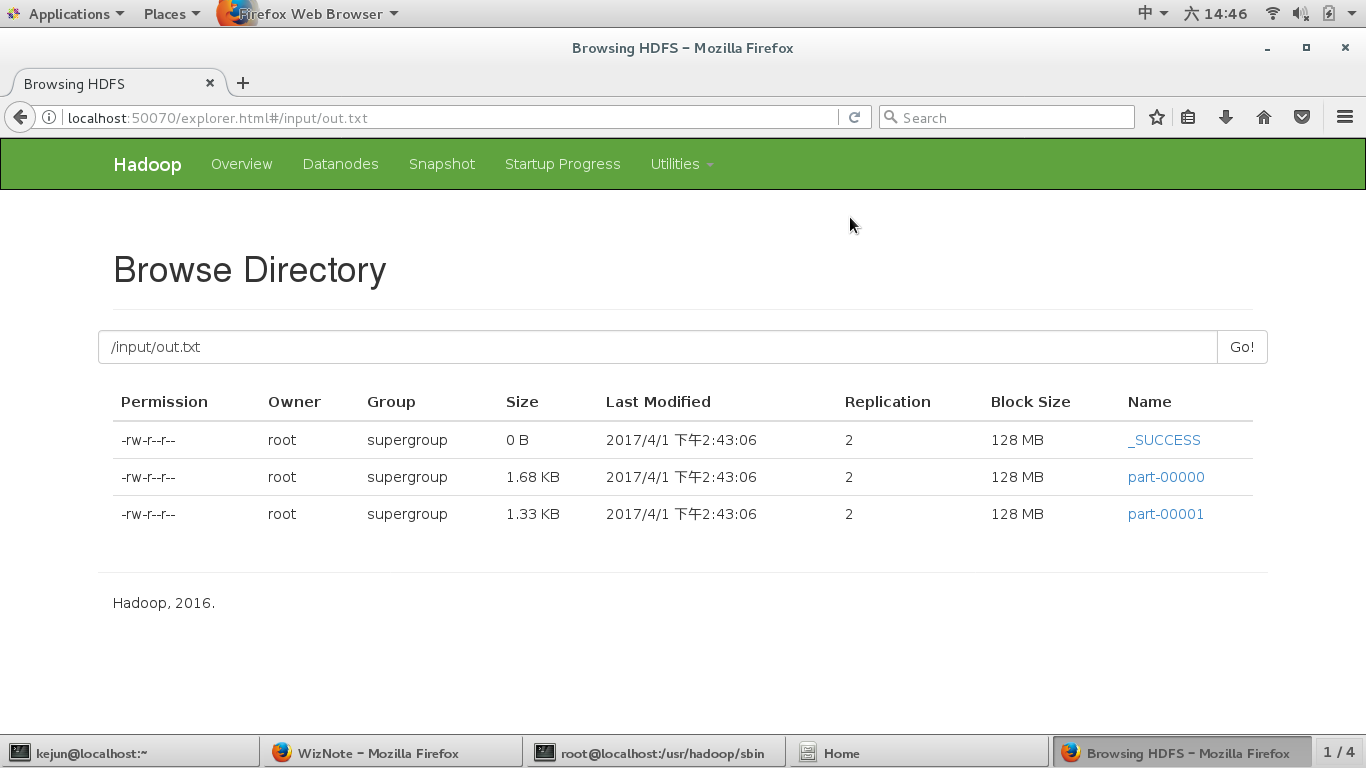
spark安装成功啦~
搭建centos7的开发环境3-Spark安装配置的更多相关文章
- 搭建centos7的开发环境1-系统安装及Python配置
在公司开发部干活的好处是可以再分配一台高性能的PC,有了新的工作电脑,原来分配的笔记本电脑就可以安装linux系统做开发了,主要有两方面的开发计划,一个是计划中要参与爬虫系统的开发,第二个是大数据环境 ...
- 01_2Java开发环境的下载 安装 配置
01_2Java开发环境的下载 安装 配置 l 配置Java开发环境步骤(WindowsXP) l 下载并按照最新版本的J2SDK l 设置Windows环境变量 l 选择合适的文本编辑器或使用集成开 ...
- Java开发环境及工具安装配置
Java开发环境及工具安装配置 Windows JDK 下载地址 https://www.oracle.com/java/technologies/javase-downloads.html 安装配置 ...
- 搭建centos7的开发环境2-单机版Hadoop2.7.3配置
最近公司准备升级spark环境,主要原因是生产环境的spark和hadoop版本都比较低,但是具体升级到何种版本还不确定,需要做进一步的测试分析.这个任务对于大数据开发环境配置有要求,这里记录一下配置 ...
- 搭建vue2.0开发环境及手动安装vue-devtools工具
安装vue脚手架 1.安装node.js,如果安装成功输入 node -v ,查看node版本号,输入npm -v查看npm版本 https://nodejs.org/en/ 2.注册淘宝镜像,定制的 ...
- C/C++代码静态检查工具Cppcheck在VS2008开发环境中的安装配置和使用
Cppcheck is an analysis tool for C/C++code. Unlike C/C++ compilers and many other analysis tools, it ...
- Visual Studio Code搭建NodeJs的开发环境
一.Visual Studio Code搭建NodeJs的开发环境 1.下载安装NodeJs并配置环境变量 可以参考:NodeJs的安装和环境变量配置 2.下载安装 VS Code编辑器 可以参考:V ...
- ES6 学习笔记 (2)-- Liunx环境安装Node.js 与 搭建 Node.js 开发环境
笔记参考来源:廖雪峰老师的javascript全栈教程 一.安装Node.js 目前Node.js的最新版本是6.2.x.首先,从Node.js官网下载对应平台的安装程序. 1.下载 选择对应的Liu ...
- 安装Go语言及搭建Go语言开发环境
一步一步,从零搭建Go语言开发环境. 安装Go语言及搭建Go语言开发环境 下载 下载地址 Go官网下载地址:https://golang.org/dl/ Go官方镜像站(推荐):https://gol ...
随机推荐
- 【翻译】如何创建Ext JS暗黑主题之二
原文:How to Create a Dark Ext JS Theme– Part 2 我已经展示了如何去开发一个精致的暗黑主题,看起来就像Spotify.在本文的第一部分,了解了Fashion.S ...
- Chipmunk僵尸物理对象的出现和解决(七)
首先判断问题出现在Star的类方法doStickShorterWork中,于是逐步分词注释代码,最后剩下如下代码: +(void)doStickShorterWork:(Stick *)stick{ ...
- Could not find property 'outputFile
* What went wrong: A problem occurred configuring project ':app'. > Could not find property 'outp ...
- XBMC源代码分析 6:视频播放器(dvdplayer)-文件头(以ffmpeg为例)
XBMC分析系列文章: XBMC源代码分析 1:整体结构以及编译方法 XBMC源代码分析 2:Addons(皮肤Skin) XBMC源代码分析 3:核心部分(core)-综述 XBMC源代码分析 4: ...
- OpenCV特征点检测------Surf(特征点篇)
Surf(Speed Up Robust Feature) Surf算法的原理 ...
- 图像检索:CEDD(Color and Edge Directivity Descriptor)算法
颜色和边缘的方向性描述符(Color and Edge Directivity Descriptor,CEDD) 本文节选自论文<Android手机上图像分类技术的研究>. CEDD具有抽 ...
- PDA开发数据由本地上传至DB
private void btnUpLoad_Click(object sender, EventArgs e) { if (!System.IO.File.Exists(LoadFile)) { M ...
- LIRe 源代码分析 2:基本接口(DocumentBuilder)
===================================================== LIRe源代码分析系列文章列表: LIRe 源代码分析 1:整体结构 LIRe 源代码分析 ...
- 如何解决Asp.Net中不能上传压缩文件的问题
在使用Asp.Net自带的服务器端控件Fileupload上传文件时,可能会出现不能上传压缩文件的问题,此时可以通过下面的方法解决: 在<system.web>中添加: <httpR ...
- android4.2添加重启菜单项
本文主要是针对android4.2关机菜单添加重启功能 A.关机提示 android4.2/frameworks/base/policy/src/com/android/internal/policy ...