一、爬虫的基本体系和urllib的基本使用
爬虫
网络是一爬虫种自动获取网页内容的程序,是搜索引擎的重要组成部分。网络爬虫为搜索引擎从万维网下载网页。一般分为传统爬虫和聚焦爬虫。
爬虫的分类
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。通俗的讲,也就是通过源码解析来获得想要的内容。
聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
防爬虫:KS-WAF将爬虫行为分为搜索引擎爬虫及扫描程序爬虫,可屏蔽特定的搜索引擎爬虫节省带宽和性能,也可屏蔽扫描程序爬虫,避免网站被恶意抓取页面。
爬虫的本质
网络爬虫本质就是浏览器http请求。
浏览器和网络爬虫是两种不同的网络客户端,都以相同的方式来获取网页:
1)首先, 客户端程序连接到域名系统(DNS)服务器上,DNS服务器将主机 名转换成ip 地址。
2)接下来,客户端试着连接具有该IP地址的服务器。服务器上可能有多个 不同进程程序在运行,每个进程程序都在监听网络以发现新的选接。.各个进程监听不同的网络端口 (port). 端口是一个l6位的数卞,用来辨识不同的服务。Http请求一般默认都是80端口。
3) 一旦建立连接,客户端向服务器发送一个http请求,服务器接收到请求后,返回响应结果给客户端。
4)客户端关闭该连接。
通用的爬虫框架流程:
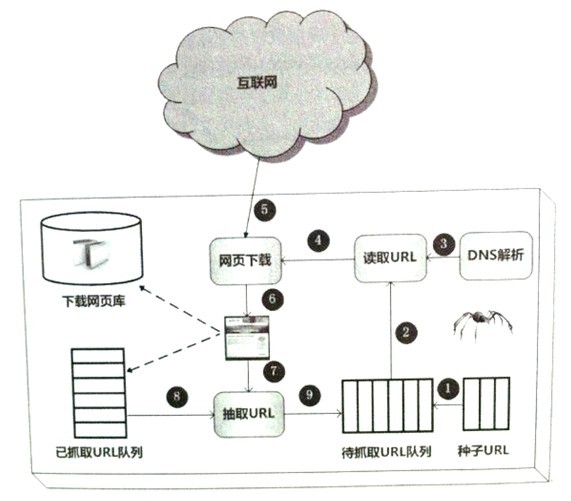
1)首先从互联网页面中精心选择一部分网页,以这 些网页的链接地址作为种子URL;
2)将这些种子URL放入待抓取URL队列中;
3)爬虫从待抓取 URL队列依次读取,并将URL通过DNS解析,把链接地址转换为网站服务器对应的IP地址。
4)然后将IP地址和网页相对路径名称交给网页下载器,
5)网页下载器负责页面内容的下载。
6)对于下载到 本地的网页,一方面将其存储到页面库中,等待建立索引等后续处理;另一方面将下载网页的 URL放入己抓取URL队列中,这个队列记载了爬虫系统己经下载过的网页URL,以避免网页 的重复抓取。
7)对于刚下载的网页,从中抽取出所包含的所有链接信息,并在已抓取URL队列 中检査,如果发现链接还没有被抓取过,则将这个URL放入待抓取URL队歹!
8,9)末尾,在之后的 抓取调度中会下载这个URL对应的网页,如此这般,形成循环,直到待抓取URL队列为空
爬虫的基本流程:
发起请求:
通过HTTP库向目标站点发起请求,也就是发送一个Request,请求可以包含额外的header等信息,等待服务器响应
获取响应内容
如果服务器能正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能是HTML,Json字符串,二进制数据(图片或者视频)等类型
解析内容
得到的内容可能是HTML,可以用正则表达式,页面解析库进行解析,可能是Json,可以直接转换为Json对象解析,可能是二进制数据,可以做保存或者进一步的处理
保存数据
保存形式多样,可以存为文本,也可以保存到数据库,或者保存特定格式的文件
详情请看http://www.cnblogs.com/alex3714/articles/8359348.html
什么是Urllib库
Urllib是Python提供的一个用于操作URL的模块,我们爬取网页的时候,经常需要用到这个库。
升级合并后,模块中的包的位置变化的地方较多。在此,列举一些常见的位置变动,方便之前用Python2.x的朋友在使用Python3.x的时候可以快速掌握。
常见的变化有:
- 在Pytho2.x中使用import urllib2——-对应的,在Python3.x中会使用import urllib.request,urllib.error。
- 在Pytho2.x中使用import urllib——-对应的,在Python3.x中会使用import urllib.request,urllib.error,urllib.parse。
- 在Pytho2.x中使用import urlparse——-对应的,在Python3.x中会使用import urllib.parse。
- 在Pytho2.x中使用import urlopen——-对应的,在Python3.x中会使用import urllib.request.urlopen。
- 在Pytho2.x中使用import urlencode——-对应的,在Python3.x中会使用import urllib.parse.urlencode。
- 在Pytho2.x中使用import urllib.quote——-对应的,在Python3.x中会使用import urllib.request.quote。
- 在Pytho2.x中使用cookielib.CookieJar——-对应的,在Python3.x中会使用http.CookieJar。
- 在Pytho2.x中使用urllib2.Request——-对应的,在Python3.x中会使用urllib.request.Reques
urllib.request 请求模块
urllib.error 异常处理模块
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块
先进行一个简单的实例:利用有道翻译(post请求)
#引入模块
import urllib.request
import urllib.parse #URL选好非常重要,选不好将会出错
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' '''
设置Headers
有很多网站为了防止程序爬虫爬网站造成网站瘫痪,会需要携带一些headers头部信息才能访问,最长见的有user-agent参数
'''
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
} key = input('enter your word:\n') form_data = {
'i': key,
'from':'AUTO',
'to':'AUTO',
'keyfrom':'fanyi.web',
'doctype':'json',
'version':'2.1',
'action':'FY_BY_REALTIME',
'typoResult':'flase'
} '''
这里用到urllib.parse,通过urllib.parse.urlencode(form_data).encode(encoding='utf-8')可以将post数据进行转换放到urllib.request.urlopen的data参数中。这样就完成了一次post请求。
所以如果我们添加data参数的时候就是以post请求方式请求,如果没有data参数就是get请求方式
'''
data =urllib.parse.urlencode(form_data).encode(encoding='utf-8') request = urllib.request.Request(url, data=data , headers=headers) '''
urlopen一般常用的有三个参数,它的参数如下:urllib.requeset.urlopen(url,data,timeout) 当然上述的urlopen只能用于一些简单的请求,因为它无法添加一些header信息,很多情况下我们是需要添加头部信息去访问目标站的,这个时候就用到了urllib.request '''
response = urllib.request.urlopen(request) #response.read()可以获取到网页的内容
result = response.read().decode('utf8')
#target = json.loads(result)
#target = urllib.parse.unquote(target)
#print(target['translateResult'][0][0]["tgt"])
#a = target['translateResult'][0][0]["tgt"]
#print(type(a))
#print(a)
print(result)
#print(target)
运行结果:
enter your words:
I love python
{"type":"EN2ZH_CN",
"errorCode":0,
"elapsedTime":1,
"translateResult":[[{"src":"I love python",
"tgt":"我喜欢python"}]]
}
另外一个简单的小实例是:豆瓣网剧情片排名前20的电影(Ajax请求)
import urllib.request
import urllib.parse
import json url = 'https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action' headers = {
'Accept': ' */*',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
} form_data = {
'start': '',
'limit': ''
} data =urllib.parse.urlencode(form_data).encode(encoding='utf-8')
request = urllib.request.Request(url, data=data , headers=headers)
response = urllib.request.urlopen(request)
result = response.read()
targets = json.loads(result) #print(result)
for num,target in enumerate(targets):
print(num+1, target["title"])
运行结果:
1 肖申克的救赎
2 控方证人
3 霸王别姬
4 美丽人生
5 这个杀手不太冷
6 阿甘正传
7 辛德勒的名单
8 十二怒汉
9 泰坦尼克号 3D版
10 十二怒汉
11 控方证人
12 盗梦空间
13 灿烂人生
14 茶馆
15 背靠背,脸对脸
16 巴黎圣母院
17 三傻大闹宝莱坞
18 千与千寻
19 泰坦尼克号
20 海上钢琴师
这些只是一些简单的运用。
一、爬虫的基本体系和urllib的基本使用的更多相关文章
- 小白学 Python 爬虫(12):urllib 基础使用(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(13):urllib 基础使用(三)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(14):urllib 基础使用(四)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(15):urllib 基础使用(五)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(16):urllib 实战之爬取妹子图
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- python爬虫入门(一)urllib和urllib2
爬虫简介 什么是爬虫? 爬虫:就是抓取网页数据的程序. HTTP和HTTPS HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的 ...
- 001 爬虫的基本概念以及urllib的request和parse
1.http的请求方式: get请求 优点:比较便捷 缺点:不安全.长度有限制post请求 优点:比较安全.数据整体没有限制.可以上传文件putdelete(删除一些信息) 发送网络请求(可以带一定的 ...
- Python爬虫(2):urllib库
爬虫常用库urllib 注:运行环境为PyCharm urllib是Python3内置的HTTP请求库 urllib.request:请求模块 urllib.error:异常处理模块 urllib.p ...
- 潭州课堂25班:Ph201805201 爬虫基础 第三课 urllib (课堂笔记)
Python网络请求urllib和urllib3详解 urllib是Python中请求url连接的官方标准库,在Python2中主要为urllib和urllib2,在Python3中整合成了url ...
随机推荐
- [国嵌攻略][044][初始化Bss段]
BSS段的作用 1.变量存储的空间 初始化的全局变量:数据段 未初始化的全局变量:BSS段 局部变量:栈 动态分配变量:堆 2.为什么要对BSS段初始化 未初始化的全局变量在使用时才被赋值,未了避免在 ...
- 使用 Gacutil.exe 将.Net程序集添加到GAC的方法
使用gacutil.exe工具安装:gacutil -i "要注册的dll文件全路径" "gacutil.exe”工具为.NET自带工具 ,需要注意的是:这个工具在.NE ...
- Tomcat学习笔记(二)—— 一个简单的Servlet容器
1.简介:Servlet编程是通过javax.Servlet和javax.servlet.http这两个包的类和接口实现的,其中javax.servlet.Servlet接口至关重要,所有的Servl ...
- SQL用了Union后的排序问题
最近使用SQL语句进行UNION查询,惊奇的发现:SQL没问题,UNION查询也没问题,都可以得到想要的结果,可是在对结果进行排序的时候,却出问题了. 1.UNION查询没问题 SELECT `id` ...
- tp5命名空间
- JavaScript 变量、类型与计算
变量类型 变量计算 变量 题目: JavaScript 中使用typeof能得到的有哪些类型? ``` 1.1 变量类型 (1).js中的数据类型:字符串.数字.布尔.数组.对象.Null.Undef ...
- BSA Network Shell系列-nsh命令
nsh nsh命令软链接到zsh,直接运行nsh可进入Network Shell,所有的Network Shell命令都需要运行nsh进入Network Shell执行 1 使用cd命令访问远程主机和 ...
- 网络编程之UDP编程
网络编程之UDP编程 UDP协议是一种不可靠的网络协议,它在通信的2端各建立一个Socket,但是这个Socket之间并没有虚拟链路,这2个Socket只是发送和接受数据的对象,Java提供了Data ...
- 【Python3之迭代器,生成器】
一.可迭代对象和迭代器 1.迭代的概念 上一次输出的结果为下一次输入的初始值,重复的过程称为迭代,每次重复即一次迭代,并且每次迭代的结果是下一次迭代的初始值 注:循环不是迭代 while True: ...
- TPYBoard开发板搭建与阿里云服务发送数据
今天给大家带来的是TPYBoard V202开发板的一次测试项目使用心得.而测试项目就是给服务端发送硬件底层数据,而数据有产品名称,WF模块MAC地址,温湿度数据. 什么是MicroP ...