【Tomcat】Tomcat工作原理及简单模拟实现
Tomcat应该都不陌生,我们经常会把写好的代码打包放在Tomcat里并启动,然后在浏览器里就能愉快的调用我们写的代码来实现相应的功能了,那么Tomcat是如何工作的?
一、Tomcat工作原理
我们启动Tomcat时双击的startup.bat文件的主要作用是找到catalina.bat,并且把参数传递给它,而catalina.bat中有这样一段话:
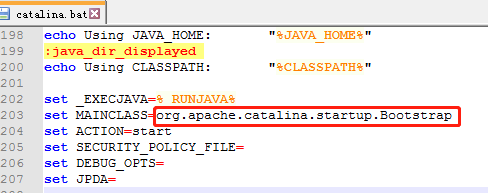
Bootstrap.class是整个Tomcat 的入口,我们在Tomcat源码里找到这个类,其中就有我们经常使用的main方法:
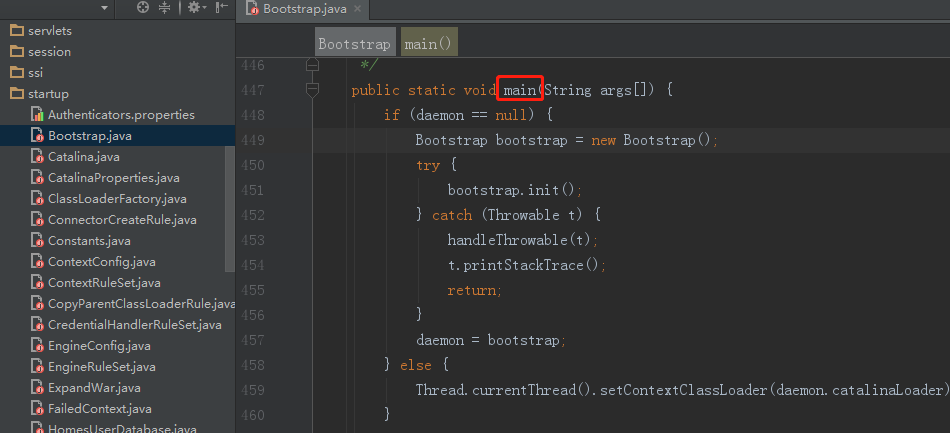
这个类有两个作用 :1.初始化一个守护进程变量、加载类和相应参数。2.解析命令,并执行。
源码不过多赘述,我们在这里只需要把握整体架构,有兴趣的同学可以自己研究下源码。Tomcat的server.xml配置文件中可以对应构架图中位置,多层的表示可以配置多个:
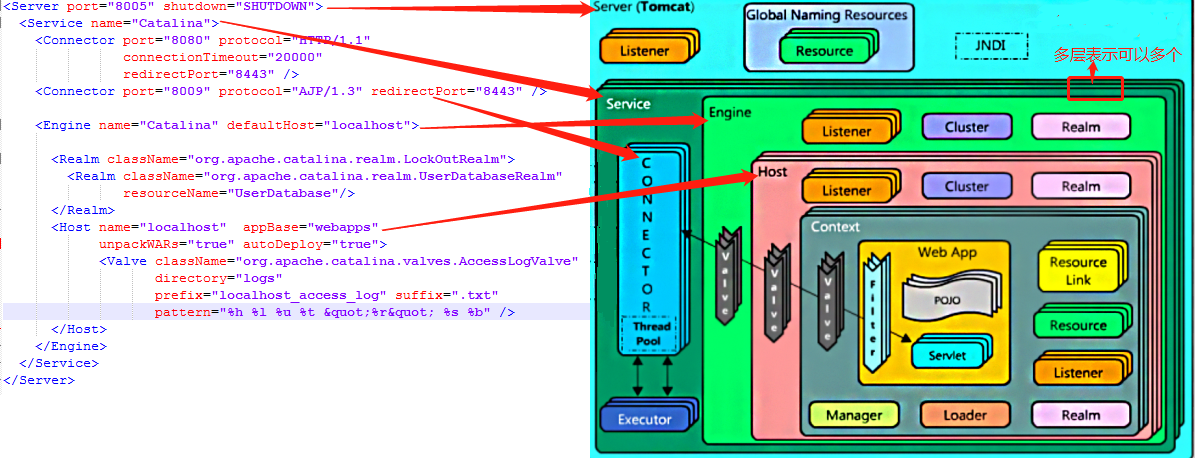
即一个由 Server->Service->Engine->Host->Context 组成的结构,从里层向外层分别是:
- Server:服务器Tomcat的顶级元素,它包含了所有东西。
- Service:一组 Engine(引擎) 的集合,包括线程池 Executor 和连接器 Connector 的定义。
- Engine(引擎):一个 Engine代表一个完整的 Servlet 引擎,它接收来自Connector的请求,并决定传给哪个Host来处理。
- Container(容器):Host、Context、Engine和Wraper都继承自Container接口,它们都是容器。
- Connector(连接器):将Service和Container连接起来,注册到一个Service,把来自客户端的请求转发到Container。
- Host:即虚拟主机,所谓的”一个虚拟主机”可简单理解为”一个网站”。
- Context(上下文 ): 即 Web 应用程序,一个 Context 即对于一个 Web 应用程序。Context容器直接管理Servlet的运行,Servlet会被其给包装成一个StandardWrapper类去运行。Wrapper负责管理一个Servlet的装载、初始化、执行以及资源回收,它是最底层容器。
比如现在有以下网址,根据“/”切割的链接就会定位到具体的处理逻辑上,且每个容器都有过滤功能。

二、Tomcat实现思路
下面只是简单实现效果,当浏览器访问对应地址时:
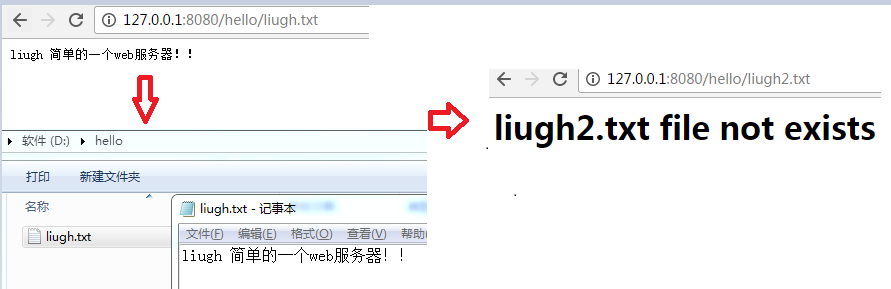
实现以上效果整体思路如下:
1.ServerSocket占用8080端口,用while(true)循环等待用户发请求。
2.拿到浏览器的请求,解析并返回URL地址,用I/O输入流读取本地磁盘上相应文件。
3.读取文件,不存在构建响应报文头、HTML正文内容,存在则写到浏览器端。
三、实现Tomcat
工程文件结构和pom.xml文件:
1.HttpServer核心处理类,用于接受用户请求,传递HTTP请求头信息,关闭容器:
public class HttpServer {
// 用于判断是否需要关闭容器
private boolean shutdown = false;
public void acceptWait() {
ServerSocket serverSocket = null;
try {
//端口号,最大链接数,ip地址
serverSocket = new ServerSocket(8080, 1, InetAddress.getByName("127.0.0.1"));
}
catch (IOException e) {
e.printStackTrace();
System.exit(1);
}
// 等待用户发请求
while (!shutdown) {
try {
Socket socket = serverSocket.accept();
InputStream is = socket.getInputStream();
OutputStream os = socket.getOutputStream();
// 接受请求参数
Request request = new Request(is);
request.parse();
// 创建用于返回浏览器的对象
Response response = new Response(os);
response.setRequest(request);
response.sendStaticResource();
//关闭一次请求的socket,因为http请求就是采用短连接的方式
socket.close();
//如果请求地址是/shutdown 则关闭容器
if(null != request){
shutdown = request.getUrL().equals("/shutdown");
}
}
catch (Exception e) {
e.printStackTrace();
continue;
}
}
}
public static void main(String[] args) {
HttpServer server = new HttpServer();
server.acceptWait();
}
}
2.创建Request类,获取HTTP的请求头所有信息并截取URL地址返回:
public class Request {
private InputStream is;
private String url;
public Request(InputStream input) {
this.is = input;
}
public void parse() {
//从socket中读取一个2048长度字符
StringBuffer request = new StringBuffer(Response.BUFFER_SIZE);
int i;
byte[] buffer = new byte[Response.BUFFER_SIZE];
try {
i = is.read(buffer);
}
catch (IOException e) {
e.printStackTrace();
i = -1;
}
for (int j=0; j<i; j++) {
request.append((char) buffer[j]);
}
//打印读取的socket中的内容
System.out.print(request.toString());
url = parseUrL(request.toString());
}
private String parseUrL(String requestString) {
int index1, index2;
index1 = requestString.indexOf(' ');//看socket获取请求头是否有值
if (index1 != -1) {
index2 = requestString.indexOf(' ', index1 + 1);
if (index2 > index1)
return requestString.substring(index1 + 1, index2);
}
return null;
}
public String getUrL() {
return url;
}
}
3.创建Response类,响应请求读取文件并写回到浏览器
public class Response {
public static final int BUFFER_SIZE = 2048;
//浏览器访问D盘的文件
private static final String WEB_ROOT ="D:";
private Request request;
private OutputStream output;
public Response(OutputStream output) {
this.output = output;
}
public void setRequest(Request request) {
this.request = request;
}
public void sendStaticResource() throws IOException {
byte[] bytes = new byte[BUFFER_SIZE];
FileInputStream fis = null;
try {
//拼接本地目录和浏览器端口号后面的目录
File file = new File(WEB_ROOT, request.getUrL());
//如果文件存在,且不是个目录
if (file.exists() && !file.isDirectory()) {
fis = new FileInputStream(file);
int ch = fis.read(bytes, 0, BUFFER_SIZE);
while (ch!=-1) {
output.write(bytes, 0, ch);
ch = fis.read(bytes, 0, BUFFER_SIZE);
}
}else {
//文件不存在,返回给浏览器响应提示,这里可以拼接HTML任何元素
String retMessage = "<h1>"+file.getName()+" file or directory not exists</h1>";
String returnMessage ="HTTP/1.1 404 File Not Found\r\n" +
"Content-Type: text/html\r\n" +
"Content-Length: "+retMessage.length()+"\r\n" +
"\r\n" +
retMessage;
output.write(returnMessage.getBytes());
}
}
catch (Exception e) {
System.out.println(e.toString() );
}
finally {
if (fis!=null)
fis.close();
}
}
}
四、扩展点
1.在WEB_INF文件夹下读取web.xml解析,通过请求名找到对应的类名,通过类名创建对象,用反射来初始化配置信息,如welcome页面,Servlet、servlet-mapping,filter,listener,启动加载级别等。
2.抽象Servlet类来转码处理请求和响应的业务。发过来的请求会有很多,也就意味着我们应该会有很多的Servlet,例如:RegisterServlet、LoginServlet等等还有很多其他的访问。可以用到类似于工厂模式的方法处理,随时产生很多的Servlet,来满足不同的功能性的请求。
3.使用多线程。本文的代码是死循环,且只能有一个链接,而现实中的情况是往往会有很多很多的客户端发请求,可以把每个浏览器的通信封装到一个线程当中。
【Tomcat】Tomcat工作原理及简单模拟实现的更多相关文章
- 你还记得 Tomcat 的工作原理么
SpringBoot 就像一条巨蟒,慢慢缠绕着我们,使我们麻痹.不得不承认,使用了 SpringBoot 确实提高了工作效率,但同时也让我们遗忘了很多技能.刚入社会的时候,我还是通过 Tomcat 手 ...
- Optaplanner规划引擎的工作原理及简单示例(2)
开篇 在前面一篇关于规划引擎Optapalnner的文章里(Optaplanner规划引擎的工作原理及简单示例(1)),老农介绍了应用Optaplanner过程中需要掌握的一些基本概念,这些概念有且于 ...
- RabbitMQ系列(二)深入了解RabbitMQ工作原理及简单使用
深入了解RabbitMQ工作原理及简单使用 RabbitMQ系列文章 RabbitMQ在Ubuntu上的环境搭建 深入了解RabbitMQ工作原理及简单使用 RabbitMQ交换器Exchange介绍 ...
- 深入解读RabbitMQ工作原理及简单使用
RabbitMQ系列目录 RabbitMQ在Ubuntu上的环境搭建 深入解读RabbitMQ工作原理及简单使用 Rabbit的几种工作模式介绍与实践 Rabbit事务与消息确认 Rabbit集群搭建 ...
- 深入了解RabbitMQ工作原理及简单使用
深入了解RabbitMQ工作原理及简单使用 RabbitMQ系列文章 RabbitMQ在Ubuntu上的环境搭建 深入了解RabbitMQ工作原理及简单使用 RabbitMQ交换器Exchange介绍 ...
- LVS负载均衡机制之LVS-DR模式工作原理以及简单配置
本博文主要简单介绍一下LVS负载均衡集群的一个基本负载均衡机制:LVS-DR:如有汇总不当之处,请各位在评论中多多指出. LVS-DR原理: LVS的英文全称是Linux Virtual Server ...
- JDBC【2】-- JDBC工作原理以及简单封装
目录 1. 工作原理 1.1 加载驱动 1.1.1 类加载相关知识 1.1.2 为什么JDK 1.6之后不需要显示加载了? 1.2 驱动加载完成了,然后呢? 2. 简单封装 1. 工作原理 一般我们主 ...
- Tomcat Servlet工作原理
前言 Tomcat的启动过程 Web应用初始化 创建Servlet实例 初始化Servlet 执行service方法 前言 Servlet实际上就是一个java类,只不过可以和浏览器进行一些数据的交换 ...
- 【IntelliJ IDEA】idea部署服务到Tomcat的工作原理
参考地址: https://blog.csdn.net/qq_41116058/article/details/81435084 为什么idea部署服务到tomcat时候,一定要修改Applicati ...
随机推荐
- es6学习笔记-proxy对象
前提摘要 尤大大的vue3.0即将到来,虽然学不动了,但是还要学的啊,据说vue3.0是基于proxy来进行对值进行拦截并操作,所以es6的proxy也是要学习一下的. 一 什么是proxy Prox ...
- MIP 与 AMP 合作进展(3月7日)
"到目前为止,全网通过 MIP 校验的网页已超10亿.除了代码和缓存, MIP 还想做更多来改善用户体验移动页面." 3月7日,MIP 项目负责人在首次 AMP CONF 上发言. ...
- Python爬虫使用lxml模块爬取豆瓣读书排行榜并分析
上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢.本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快. 本次爬取的豆瓣书籍排行榜的首页地 ...
- 使用ConcurrentHashMap一定线程安全?
前言 老王为何半夜惨叫?几行代码为何导致服务器爆炸?说好的线程安全为何还是出问题?让我们一起收看今天的<走进IT> 正文 CurrentHashMap出现背景 说到ConcurrentHa ...
- MySQL8.0新特性——支持原子DDL语句
MySQL 8.0开始支持原子数据定义语言(DDL)语句.此功能称为原子DDL.原子DDL语句将与DDL操作关联的数据字典更新,存储引擎操作和二进制日志写入组合到单个原子事务中.即使服务器在操作期间暂 ...
- php一致性hash算法的应用
阅读这篇博客前首先你需要知道什么是分布式存储以及分布式存储中的数据分片存储的方式有哪些? 分布式存储系统设计(2)—— 数据分片 阅读玩这篇文章后你会知道分布式存储的最优方案是使用 一致性hash算法 ...
- 【译】在C#中实现单例模式
目录 介绍 第一个版本 --不是线程安全的 第二个版本 -- 简单的线程安全 第三个版本 - 使用双重检查锁定尝试线程安全 第四个版本 - 不太懒,不使用锁且线程安全 第五版 - 完全懒惰的实例化 第 ...
- 如何高效的学习WEB前端
IT 行业的变化快是众人皆知的,需要持续去学习新的知识内容.但是,往往我们工作之后,经常发现学习的东西很少了,学习效率非常低,感觉自己到了一个瓶颈期,久而久之,就演变成『一年工作经验,重复去用十年』的 ...
- 学习笔记—HTML基础标签
HTML的概念 概念: HTML 是用来描述网页的一种语言. HTML 指的是超文本标记语言 (Hyper Text Markup Language) HTML 不是一种编程语言,而是一种标记语言 ( ...
- Beyond Compare 3.3.8 build 16340 + Key
本文摘录自冰点社区:http://forum.z27315.com/topic/14746-beyond-compare-338-build-16340-key/ Download Beyond Co ...