sql 查询 某字段 重复次数 最多的记录
需求 查询小时气象表中 同一日期、同一城市、同意检测站点 首要污染物出现次数最多的记录
第一步: 添加 排序字段
select StationID,RecordDate,CityID,Primary_Pollutant,ROW_NUMBER() over(partition by StationID,RecordDate,CityID order by count(0) desc ) as Numfrom T_AirHourly
group by StationID,RecordDate,CityID,Primary_Pollutant
第二步 子查询:在查询的基础上再次查询
select StationID,RecordDate,CityID,Primary_Pollutant from (
select StationID,RecordDate,CityID,Primary_Pollutant,ROW_NUMBER() over(partition by StationID,RecordDate,CityID order by count(0) desc ) as Numfrom T_AirHourly
group by StationID,RecordDate,CityID,Primary_Pollutant
)t where t.Num = 1
第三步 创建视图
create view V_Primary_Pollutant as
select StationID,RecordDate,CityID,Primary_Pollutant from (
select StationID,RecordDate,CityID,Primary_Pollutant,ROW_NUMBER() over(partition by StationID,RecordDate,CityID order by count(0) desc ) as Numfrom T_AirHourly
group by StationID,RecordDate,CityID,Primary_Pollutant
)t where t.Num = 1
结果:
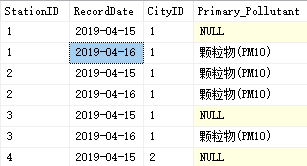
第五步: 统计一天中各种污染物的平均值
将视图作为独立模块 左连接查询 统计一天 各种污染物的平均值。
转载:
row_ number over函数的基本用法
https://xiaoxiaoher.iteye.com/blog/2428619
函数语法: ROW_NUMBER() OVER(PARTITION BY COLUMN ORDER BY COLUMN)
函数作用:从1开始,为按组排序的每条记录添加一个序列号 函数只能用于select和order by子句中 不能用在where子句
不分组排序
不进行分组时语法为ROW_NUMBER() OVER(ORDER BY COLUMN),如:
有一个表A就一个字段num,数据如下
num
10
20
30
查询语句为select row_number() over(order by num) as idx,num from A
结果如下
num idx
10 1
20 2
30 3
分组排序
分组的话ROW_NUMBER() OVER(PARTITION BY COL1 ORDER BY COL2)表示根据COL1分组,在分组内部根据COL2排序,
而此函数的结果值就表示每组内部排序后的顺序编号(组内连续的惟一的)
表employee有数据如下
empid deptid salary
1 10 5500.00
2 10 4500.00
3 20 1900.00
4 20 4800.00
查询语句为:select *,row_number() over(partition by deptid order by salary desc) rank from employee
结果如下
empid deptid salary rank
1 10 5500.00 1
2 10 4500.00 2
4 20 4800.00 1
3 20 1900.00 2
比较
可以看到这个函数不分组时的作用oracle自带row_num也能完成,差别就是row_num从0开始。分组排序这个功能就比较强大
另外还有两个类似函数rank() over() 和dense_rank() over()
区别就是如果排序字段有重复值
row_number()函数还是1 2 3排下去
rank() over()则会出现 1 1 3
dense_rank() over() 则会出现 1 1 2
这三种情况 就是给的序号不一样
ROW_NUMBER() OVER()函数用法;(分组,排序),partition by
转载:https://www.cnblogs.com/alsf/p/6344197.html
http://www.cnblogs.com/BluceLee/p/8004716.html
1、row_number() over()排序功能:
(1) row_number() over()分组排序功能:
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where group by order by 的执行。
partition by 用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组,它和聚合函数不同的地方在于它能够返回一个分组中的多条记录,而聚合函数一般只有一个反映统计值的记录。
例如:employee,根据部门分组排序。

SELECT empno,WORKDEPT,SALARY, Row_Number() OVER (partition by workdept ORDER BY salary desc) rank FROM employee
--------------------------------------
000010 A00 152750 1
000110 A00 66500 2
000120 A00 49250 3
200010 A00 46500 4
200120 A00 39250 5
000020 B01 94250 1
000030 C01 98250 1
000130 C01 73800 2
(2)对查询结果进行排序:(无分组)
SELECT empno,WORKDEPT,SALARY, Row_Number() OVER (ORDER BY salary desc) rank FROM employee
--------------------------------------
000010 A00 152750 1
000030 C01 98250 2
000070 D21 96170 3
000020 B01 94250 4
000090 E11 89750 5
000100 E21 86150 6
000050 E01 80175 7
000130 C01 73800 8
000060 D11 72250 9
row_number() over()和rownum差不多,功能更强一点(可以在各个分组内从1开时排序).
2、rank() over()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内).
select workdept,salary,rank() over(partition by workdept order by salary) as dense_rank_order from emp order by workdept;
------------------
A00 39250 1
A00 46500 2
A00 49250 3
A00 66500 4
A00 152750 5
B01 94250 1
C01 68420 1
C01 68420 1
C01 73800 3
3、dense_rank() over()是连续排序,有两个第二名时仍然跟着第三名。相比之下row_number是没有重复值的 .
select workdept,salary,dense_rank() over(partition by workdept order by salary) as dense_rank_order from emp order by workdept;
------------------
A00 39250 1
A00 46500 2
A00 49250 3
A00 66500 4
A00 152750 5
B01 94250 1
C01 68420 1
C01 68420 1
C01 73800 2
C01 98250 3
使用ROW_NUMBER删除重复数据
---假设表TAB中有a,b,c三列,可以使用下列语句删除a,b,c都相同的重复行。
DELETE FROM (select year,QUARTER,RESULTS,row_number() over(partition by YEAR,QUARTER,RESULTS order by YEAR,QUARTER,RESULTS) AS ROW_NO FROM SALE )
WHERE ROW_NO>1
sql 查询 某字段 重复次数 最多的记录的更多相关文章
- sql 查询哪些字段重复及(in和exict的区别)
select count(1),content_id,keyword_id from tb_content_keyword_relation group by content_id,keyword_i ...
- MySQL查询重复出现次数最多的记录
MySQL查询的方法很多,下面为您介绍的MySQL查询语句用于实现查询重复出现次数最多的记录,对于学习MySQL查询有很好的帮助作用. 在有些应用里面,我们需要查询重复次数最多的一些记录,虽然这是一个 ...
- SQL查询语句去除重复行
1.存在两条完全相同的纪录 这是最简单的一种情况,用关键字distinct就可以去掉 select distinct * from table(表名) where (条件) 2.存在部分字段相同的纪录 ...
- POJ-3693-Maximum repetition substring(后缀数组-重复次数最多的连续重复子串)
题意: 给出一个串,求重复次数最多的连续重复子串 分析: 比较容易理解的部分就是枚举长度为L,然后看长度为L的字符串最多连续出现几次. 既然长度为L的串重复出现,那么str[0],str[l],str ...
- POJ - 3693 Maximum repetition substring(重复次数最多的连续重复子串)
传送门:POJ - 3693 题意:给你一个字符串,求重复次数最多的连续重复子串,如果有一样的,取字典序小的字符串. 题解: 比较容易理解的部分就是枚举长度为L,然后看长度为L的字符串最多连续出现 ...
- <C#>找出数组中重复次数最多的数值
给定一个int数组,里面存在重复的数值,如何找到重复次数最多的数值呢? 这是在某社区上有人提出的问题,我想到的解决方法是分组. 1.先对数组中的所有元素进行分组,那么,重复的数值肯定会被放到一组中: ...
- 【POJ 3693】Maximum repetition substring 重复次数最多的连续重复子串
后缀数组的论文里的例题,论文里的题解并没有看懂,,, 求一个重复次数最多的连续重复子串,又因为要找最靠前的,所以扫的时候记录最大的重复次数为$ans$,扫完后再后从头暴力扫到尾找重复次数为$ans$的 ...
- spoj687 后缀数组重复次数最多的连续重复子串
REPEATS - Repeats no tags A string s is called an (k,l)-repeat if s is obtained by concatenating k& ...
- JS-取出字符串中重复次数最多的字符并输出
/** 取出字符串中重复字数最多的字符 */ var words = 'sdfghjkfastgbyhnvdstyaujskgfdfhlaa'; //创建字符串 var word, //单个字符 le ...
随机推荐
- 《前端之路》之 前端图片 类型 & 优化 & 预加载 & 懒加载 & 骨架屏
目录 09: 前端图片 类型 & 优化 & 预加载 & 懒加载 & 骨架屏 09: 前端图片 类型 & 优化 & 预加载 & 懒加载 & ...
- SpringMVC 中 @ControllerAdvice 注解的三种使用场景!
@ControllerAdvice ,很多初学者可能都没有听说过这个注解,实际上,这是一个非常有用的注解,顾名思义,这是一个增强的 Controller.使用这个 Controller ,可以实现三个 ...
- 【纯技术贴】.NETStandard FreeSql v0.0.9 功能预览
年关将至,首页技术含量文章真是越来越少,理解大家盼着放假过年,哥们我何尝不是,先给大家拜个早年. 兄弟我从11月底发了神经,开启了 ORM 功能库的开发之旅,历时两个月编码和文档整理,目前预览版本更新 ...
- 快速入门:弄懂Kafka的消息流转过程
大家都知道 Kafka 是一个非常牛逼的消息队列框架,阿里的 RocketMQ 也是在 Kafka 的基础上进行改进的.对于初学者来说,一开始面对这么一个庞然大物会不知道怎么入手.那么这篇文章就带你先 ...
- vscode restclient 插件
使用步骤: 1.vscode 安装restclient 扩展 2.创建 .http 或 .rest 文件 ,编写相应内容 同一个文件内 可以通过 ### 分割多个请求 可以通过 @hostname ...
- Yii2设计模式——静态工厂模式
应用举例 yii\db\ActiveRecord //获取 Connection 实例 public static function getDb() { return Yii::$app->ge ...
- 原创分享!SharePoint母版页修改(实战)
分享人:广州华软 极简 一. 前言 SharePoint网站创建时,便自带一份母版页,可由开发人员重新自定义一份母版页,关于如何转换成母版页,由于之前已经讲述过,此篇便不再赘述了. 若自定义母版页,你 ...
- Odoo Linux服务器一键安装脚本使用指南
Odoo安装脚本介绍 为了帮助更多Linux服务器维护人员快速部署Odoo,为此开源智造(OSCG)基于André Schenkels曾经开放的openerp-install-scripts所构建的基 ...
- AI2(App Inventor 2)离线版服务器单机版
注意:每次退出前导出自己的项目到本地做备份. 单机版特点: 1.同步官方最新版本,没有对java源代码进行修改,仅修改war\login.jsp及\war\WEB-INF\appengine-web. ...
- hdfs一直处于safemode模式
目前来看,导致hdfs一直处于safemode模式最直接的原因是已成功复制的块的比例没有达到默认值,块的损坏也会造成一直处于安全模式. 1)文件系统中有损坏的文件,使用fsck命令来查看 hadoop ...