es的调优
3.1、分片查询方式
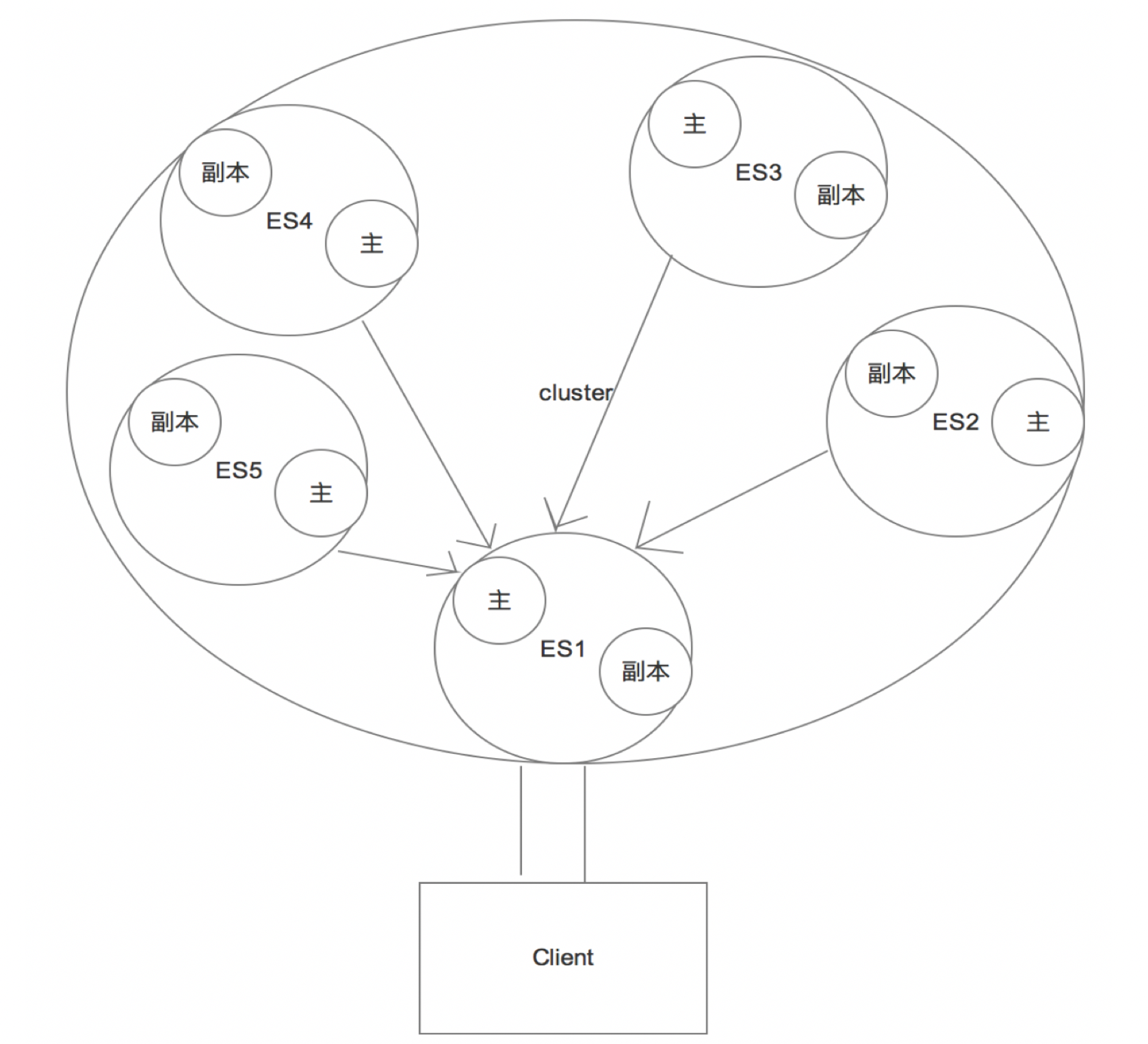

当前的图片中有5个主分片,5个副本;这对于es的集群来说,这种配置是非常常见的;
但是问题来了,当我们的客户端做查询的时候,程序会向主分片发送请求还是副本发送请求?
还是说直接去集群上随机找一台机器查询,还是在这个机器里面在随机的找到分片和副本查询?
【注意】:
默认情况下是随机查询的
这种随机的方式其实效率并不高,
1查询阶段
(1):客户端发送一个检索请求给node3,此时node3会创建一个空的优先级队列并且配置好分页参数from与size。
(2):node3将检所请求发送给index中的每一个shard(primary 和 replica),每一个在本地执行检索,并将结果添加到本地的优先级队列中;
(3):每个shard返回本地优先级序列中所记录的_id与score值,并发送node3。Node3将这些值合并到自己的本地的优先级队列中,并做全局的排序。
2获取阶段
(1):node 3获取了所有待检索数据的定位之后,发送一个mget的请求给与数据相关的shard。
(2):每个收到node 3的get请求的shard将读取相关文档_source中的内容,并将它们返回给node 3。
(3):当node 3获取到了所有shard返回的文档后,node 3将它们合并成一条汇总的结果,返回给客户端。

我们通过上面的查询方式可以了解到,如果我们直接将客户端定位到指定的机器上查询,就少去了中间的来回复制的步骤,这样在检索大量数据的时候,网络的IO也得到了提升
其实,在elasticsearch的查询阶段,我们可以做很多的优化措施,比如控制我们的分片查询方式:
Es会将数据均衡的存储在分片中,我们可以指定es去具体的分片或节点中查询从而进一步的实现es极速查询。 1:randomizeacross shards
随机选择分片查询数据,es的默认方式 2:_local
优先在本地节点上的分片查询数据然后再去其他节点上的分片查询,本地节点可以减少跨网络的IO问题,但有可能造成负载不均问题 3:_primary
只在主分片中查询不去副本查 4:_primary_first
优先在主分片中查,如果主分片挂了则去副本查 5:_only_node[已经被移除]
只在指定id的节点中的分片中查询 6:_prefer_node
优先在指定你给节点中查询 7:_shards
在指定分片中查询 8:_only_nodes
可以自定义去指定的多个节点查询,es不提供此方式需要改源码。
/**
* 分片查询方式
* */
@Test
public void searchType(){
SearchRequestBuilder builder = client.prepareSearch("school").setTypes("student");
SearchResponse searchResponse = builder.setQuery(QueryBuilders.matchQuery("name", "于谦"))
// .setPreference("_local")
// .setPreference("_primary")
// .setPreference("_only_nodes:*")
// .setPreference("_prefer_nodes:jnrN6IYURTKYPE_ZYQqFDg")
// .setPreference("_shards:0,1,2")//TODO 可以提高查询效率
// .setPreference("randomizeacross")
.get();//指定查询方式
SearchHits hits = searchResponse.getHits();
System.out.println("查询的结果数量有"+hits.getTotalHits()+"条");
System.out.println("结果中最高分:"+hits.getMaxScore()); // 遍历每条数据
Iterator<SearchHit> iterator = hits.iterator();
while(iterator.hasNext()){
SearchHit searchHit = iterator.next();
System.out.println("所有的数据JSON的数据格式:"+searchHit.getSourceAsString());
System.out.println("每条得分:"+searchHit.getScore());
// 获取每个字段的数据
System.out.println("id:"+searchHit.getSource().get("id"));
System.out.println("name:"+searchHit.getSource().get("name"));
System.out.println("age:"+searchHit.getSource().get("age"));
System.out.println("**********************************************");
for(Iterator<SearchHitField> ite = searchHit.iterator(); ite.hasNext();){
SearchHitField next = ite.next();
System.out.println(next.getValues());
}
}
}
es的调优的更多相关文章
- [数据库]漫谈ElasticSearch关于ES性能调优几件必须知道的事(转)
ElasticSearch是现在技术前沿的大数据引擎,常见的组合有ES+Logstash+Kibana作为一套成熟的日志系统,其中Logstash是ETL工具,Kibana是数据分析展示平台.ES让人 ...
- 漫谈ElasticSearch关于ES性能调优几件必须知道的事
lasticSearch是现在技术前沿的大数据引擎,常见的组合有ES+Logstash+Kibana作为一套成熟的日志系统,其中Logstash是ETL工具,Kibana是数据分析展示平台.ES让人惊 ...
- es性能调优---写优化操作
ES 的默认配置,是综合了数据可靠性.写入速度.搜索实时性等因素.实际使用时,我们需要根据公司要求,进行偏向性的优化. 写优化 假设我们的应用场景要求是,每秒 300 万的写入速度,每条 500 字节 ...
- ES 基础理论 配置调优
一.简介 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java开发的,并作为 ...
- ES调优
ES Connection timed out,调优方向 1. 使用游标滚动查询 scrollId 游标id searchResponse.getScrollId() scroll 设置游标的保留时间 ...
- 一次看完28个关于ES的性能调优技巧,很赞,值得收藏!
因为总是看到很多同学在说Elasticsearch性能不够好.集群不够稳定,询问关于Elasticsearch的调优,但是每次都是一个个点的单独讲,很多时候都是case by case的解答,本文简单 ...
- elasticsearch 了解多少,说说你们公司 es 的集群架构,索 引数据大小,分片有多少,以及一些调优手段 ?
面试官:想了解应聘者之前公司接触的 ES 使用场景.规模,有没有做过比较大 规模的索引设计.规划.调优. 解答: 如实结合自己的实践场景回答即可. 比如:ES 集群架构 13 个节点,索引根据通道不同 ...
- elasticsearch 了解多少,说说你们公司 es 的集群架构,索 引数据大小,分片有多少,以及一些调优手段 。
面试官:想了解应聘者之前公司接触的 ES 使用场景.规模,有没有做过比较大 规模的索引设计.规划.调优. 解答: 如实结合自己的实践场景回答即可. 比如:ES 集群架构 13 个节点,索引根据通道不同 ...
- elasticsearch运维实战之2 - 系统性能调优
elasticsearch性能调优 集群规划 独立的master节点,不存储数据, 数量不少于2 数据节点(Data Node) 查询节点(Query Node),起到负载均衡的作用 Linux系统参 ...
随机推荐
- Oracle SQL调优
在多数情况下,Oracle使用索引t来更快地遍历表,优化器主要根据定义的索引来提高性能. 但是,如果在SQL语句的where子句中写的SQL代码不合理,就会造成优化器删去索引而使用全表扫描,一般就这种 ...
- linux之网卡绑定
1 什么是网卡绑定 将多块网卡绑定同一IP地址对外提供服务,可以实现高可用或者负载均衡.直接给两块网卡设置同一IP地址是不可以的.通过bonding,虚拟一块网卡对外提供连接,物理网卡的被修改为相同的 ...
- linux 进程2
一. exec族函数 1.1. 为什么需要exec函数 a. fork子进程是为了执行新程序(fork创建了子进程后,子进程和父进程同时被OS调度执行,因此子进程可以单独的执行一个程序,这个程序宏观上 ...
- C#选择文件返回缩略图
传入文件路径,返回临时文件中缩略图的路径,jpg,pdf,office,rar都行 string path = ThumbnailHelper.GetInstance().GetJPGThumbnai ...
- JS调用PageMethods
http://www.cnblogs.com/Ren_Lei/archive/2010/07/14/1777413.html JS调用PageMethods 操作步骤: 1.新建一个WebApplic ...
- j网络爬虫之WebMagic
WebMagic官网:http://webmagic.io/ 注意: 1.在自定义PageProcessor中使用System.out.println(“str”),Spider.create(new ...
- mac安装卸载brew
1.安装 访问https://brew.sh,copy图中的命令到命令行中,进行下载安装 2.卸载 官方版本的卸载: /usr/bin/ruby -e "$(curl -fsSL https ...
- [七月挑选]IntelliJ IDEA常用设置
title: IntelliJ IDEA常用设置 设置idea的类注释快捷键 File -> Settings -> Live Templates 1.右边的 + -> Templa ...
- MySQl查询语句大全
综合使用 查询 目录: #----综合使用 书写顺序 select distinct * from '表名' where '限制条件' group by '分组依据' having '过滤条件' or ...
- 01.Linux-CentOS系统清理缓存脚本
#自动清理缓存脚本 [root@k8s-node3 ~]# vim freemem.sh#! /bin/sh#当前已使用内存大小used=`free -m | awk 'NR==2' | awk '{ ...