java 中的编码(二)
UTF-16编码规则:

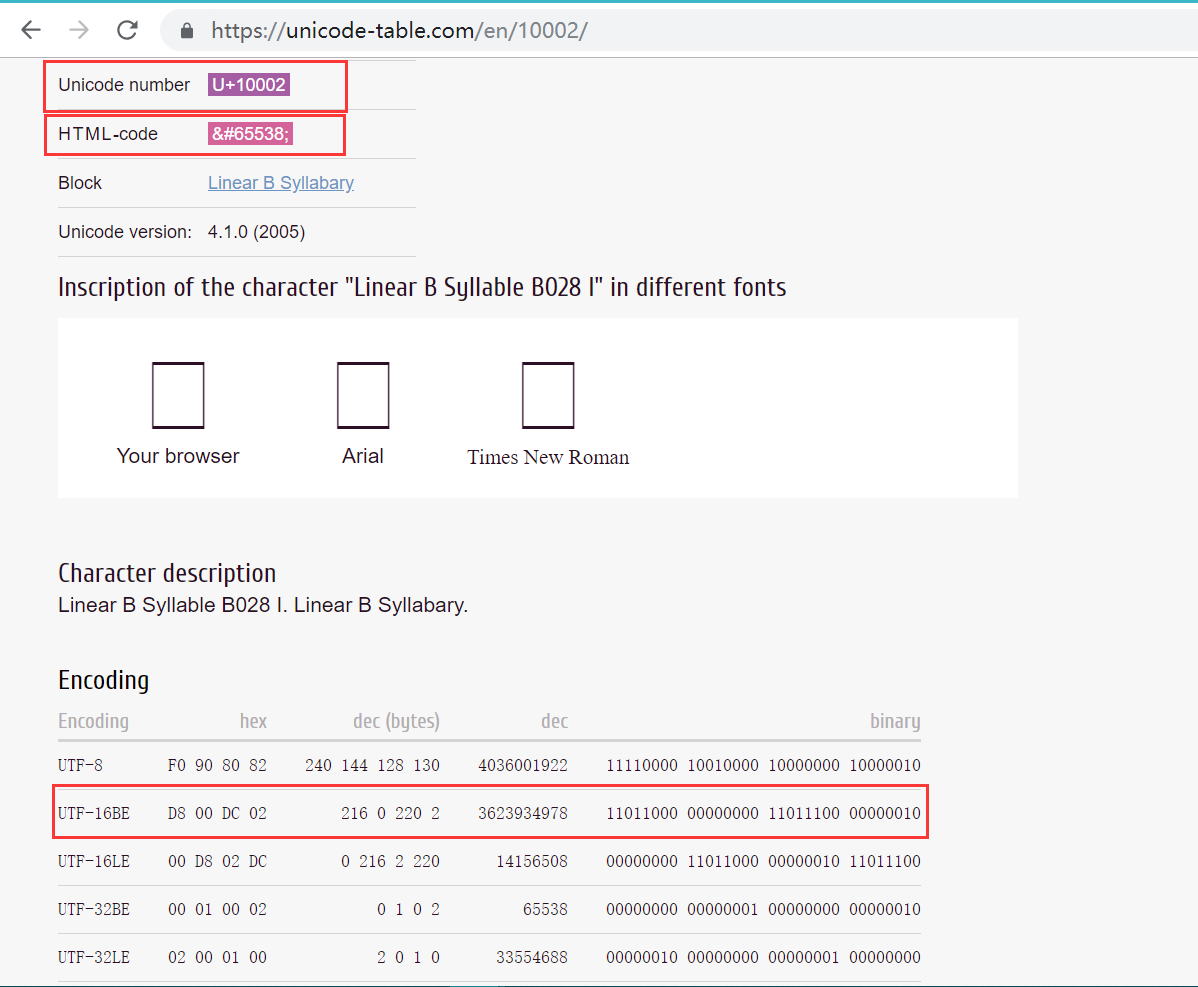
按照UTF-16编码规则计算下Unicode码位为 U+10002 (十进制:65538)的字符的UTF-16编码表示。
U+10002落在 [U+10000, U+10FFFF] 区间内。其UTF-16编码需要用四字节16位。
1、码位减去0x10000,0x10002 - 0x10000得到 0x02,即 0000000000 0000000010(20位比特)
2、高10位加上0xD800,0x00 + 0xD800得到 0xD800,即 1101 1000 0000 0000 (16位比特)
3、低10位加上0xDC00,0x02 + 0xDC00得到 0xDC02,即1101 1100 0000 0000 (16位比特)
4、所以U+10002的UTF-16编码表示位:0xD800DC02 ,即11011000 00000000 11011100 00000000(32位比特)
通过UTF-16编码,反推其Unicode码位:
1、UTF-16编码:0xD800DC02 ,即11011000 00000000 11011100 00000000(32位)。
2、前两个字节(16位)0xD800 减去 0xD800 得到 0x00,即 00 00000000(10位)
3、后两个字节(16位)0xDC02 减去 0xDC00 得到 0x02,即 00 00000010(10位)
4、0x00 和 0x02组合起来拼成0x02,即 0000 00000000 00000010(20位比特)
5、0x02 加上 0x10000 得到 0x10002,其Unicode码表示为U+10002,十进制即65538。
通过代码查看U+10002的utf-16be编码:
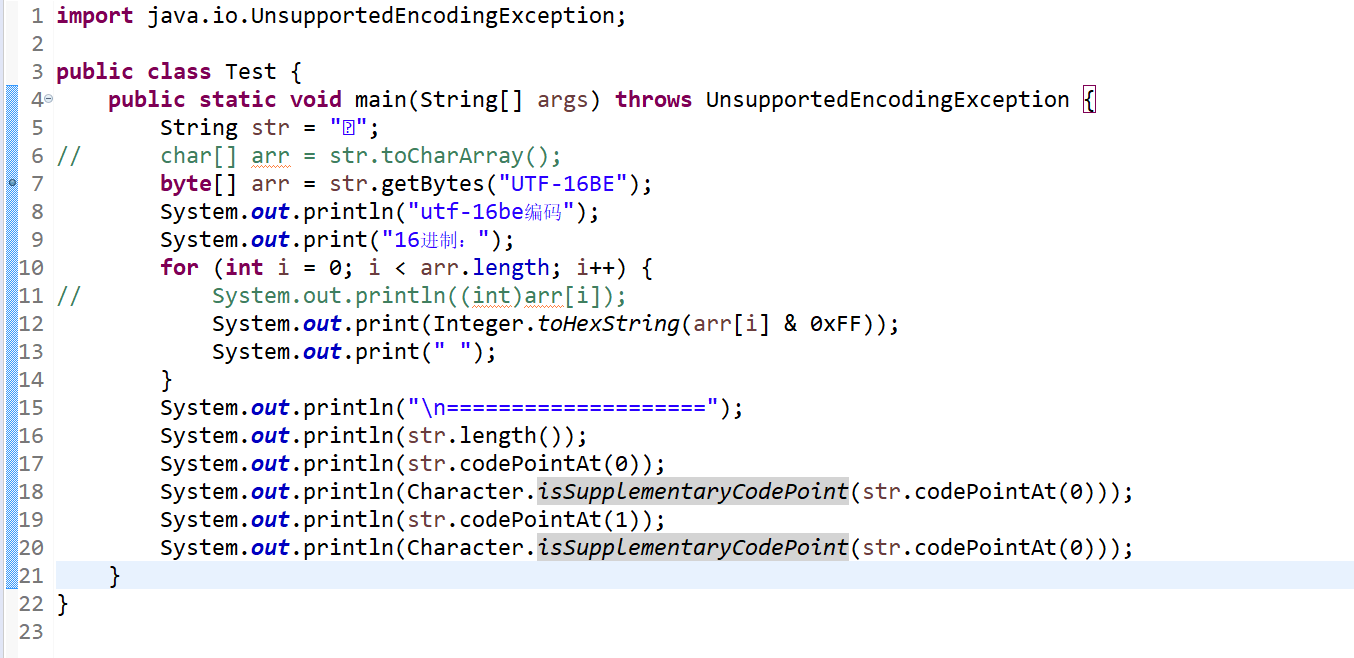
输出:
utf-16be编码
16进制:d8 0 dc 2
====================
2
65538
true
56322
true
由输出可只U+10002的UTF-16BE编码表示是:D8 00 DC 02,由4字节表示。
codePointAt()方法:
public int codePointAt(int index) {
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return Character.codePointAtImpl(value, index, value.length);
}
==============================================================================
static int codePointAtImpl(char[] a, int index, int limit) {
char c1 = a[index];
// utf-16四字节编码的字符,第一个码位(16位)的范围是 ['\uD800', '\uDBFF')
if (isHighSurrogate(c1) && ++index < limit) {
char c2 = a[index];
// 第二个码位(16位)的范围是 ['\uDC00', '\uDFFF')
if (isLowSurrogate(c2)) {
return toCodePoint(c1, c2);
}
}
// 2字节UTF-16编码则直接返回该2字节。
// 4字节UTF-16编码的第二个codePoint则直接返回该4字节中的后2字节。
return c1;
}
==============================================================================
public static final char MIN_HIGH_SURROGATE = '\uD800';
public static final char MAX_HIGH_SURROGATE = '\uDBFF';
public static final char MIN_LOW_SURROGATE = '\uDC00';
public static final char MAX_LOW_SURROGATE = '\uDFFF';
public static final int MIN_SUPPLEMENTARY_CODE_POINT = 0x010000;
==============================================================================
public static boolean isHighSurrogate(char ch) {
// Help VM constant-fold; MAX_HIGH_SURROGATE + 1 == MIN_LOW_SURROGATE
return ch >= MIN_HIGH_SURROGATE && ch < (MAX_HIGH_SURROGATE + 1);
}
public static boolean isLowSurrogate(char ch) {
return ch >= MIN_LOW_SURROGATE && ch < (MAX_LOW_SURROGATE + 1);
}
==============================================================================
// 根据4字节(32位)UTF-16编码求Unicode码位(通过UTF-16编码,反推其Unicode码位)
public static int toCodePoint(char high, char low) {
// Optimized form of:
// return ((high - MIN_HIGH_SURROGATE) << 10)
// + (low - MIN_LOW_SURROGATE)
// + MIN_SUPPLEMENTARY_CODE_POINT;
return ((high << 10) + low) + (MIN_SUPPLEMENTARY_CODE_POINT
- (MIN_HIGH_SURROGATE << 10)
- MIN_LOW_SURROGATE);
}
==============================================================================
isSupplementaryCodePoint()方法:
public static final int MIN_SUPPLEMENTARY_CODE_POINT = 0x010000;
public static final int MAX_CODE_POINT = 0X10FFFF; =================================================================
// 根据Unicode number判断字符是否在增补字符范围
public static boolean isSupplementaryCodePoint(int codePoint) {
return codePoint >= MIN_SUPPLEMENTARY_CODE_POINT
&& codePoint < MAX_CODE_POINT + 1;
}
小demo,输出字符的Unicode number的十进制形式:
public class Test {
public static void main(String[] args) throws UnsupportedEncodingException {
// str的第二个字符的Unicode码是U+10002
// 10进制65538
// UTF-16BE编码二进制11011000 00000000 11011100 00000010
String str = "A
java 中的编码(二)的更多相关文章
- java基础---->java中字符编码问题(一)
这里面对java中的字符编码做一个总结,毕竟在项目中会经常遇到这个问题.爱不爱都可以,我怎样都依你,连借口我都帮你寻. 文件的编码格式 一.关于中文的二进制字节问题 public static Str ...
- 理清Java中的编码解码转换
1.字符集及编码方式 概括:字符编码方式及大端小端 详细:彻底理解字符编码 可以通过Charset.availableCharsets()获取Java支持的字符集,以JDK8为例,得到其支持的字符集: ...
- java中封装类(二)
java中的数字类型包括 Byte,Short,Integer,Long,Float,Double.其中前四个是整数,后两个是浮点数. 在说java中数字类型之前先来看看它们统一的基类Number. ...
- java中的编码和编码格式问题
看来问的人和回答的人都不一定清楚什么是“编码和编码格式”,以及如何理解“java中字符串的编码”;首先明确几点: unicode是一种“编码”,所谓编码就是一个编号(数字)到字符的一种映射关系,就仅仅 ...
- 关于java中的编码问题
ok,今天搞了一天都在探索java字符的编码问题.十分头疼.最后终于得出几点: 1.网上有很多博客说判断一个String的编码的方法是通过如下代码;但其实这个代码完全是错的,用一种编码decode后, ...
- JAVA中的编码分析
在实际编程中可以不用关注JVM中使用的是什么编码,而只需要关注自己输出需要采用的编码,JVM会根据你设置的编码正确操作. 1.String采用的是什么编码? 很多厂家根据规范实现了JVM,JVM只说明 ...
- java中字符串编码转换
Java 正确的做字符串编码转换 字符串的内部表示? 字符串在java中统一用unicode表示( 即utf-16 LE) , 对于 String s = "你好哦!"; 如果源码 ...
- Java中字符编码和字符串所占字节数 .
首 先,java中的一个char是2个字节.java采用unicode,2个字节来表示一个字符,这点与C语言中不同,C语言中采用ASCII,在大多数 系统中,一个char通常占1个字节,但是在0~12 ...
- java 中的编码
1.1字节=8位,1024字节=1KB2.16进制0x12345678,其二进制为00010010 00110100 01010110 01111000共4字节3.字节序:两个或多个字节存放的先后顺序 ...
- 一文解开java中字符串编码的小秘密
目录 简介 Unicode的发展史 Unicode详解 UTF-8 UTF-16 UTF-32 Null-terminated string 和变种UTF-8 简介 在本文中你将了解到Unicode和 ...
随机推荐
- IFG以太网帧间隙
交换机的线速 描述交换机性能可以使用“线速”这个概念,那它是什么意思呢?所谓的线速是指经过交换机处理的理想状态下最大数据率.描述数据率可以用bps(bit per second)和mpps(milli ...
- VGA接口一根针折了
注意!!要由 针 对照着 接口 看!!别看反了! VGA接头图如下: VGA接口,15根针,其对应接口定义如下: 1红基色 red 2 绿基色 green 3 蓝基色 blue 4 地址码 ID Bi ...
- 细数EDM营销中存在的两大盲点
国庆节了,祝大家国庆快乐,转眼博客至今已有三年了.下面博主为大家介绍EDM营销中存在的两大盲点,供大家参考. 一是忽略用户友好.用户友好策略是Email营销成功的关键要素,具体包括内容友好策略.方式友 ...
- k8s架构
master节点 k8s的集群由master和node组成,节点上运行着若干k8s服务. master节点之上运行着的后台服务有kube-apiserver .kube-scheduler.kube- ...
- 数据结构系列之2-3-4树的插入、查找、删除和遍历完整版源代码实现与分析(dart语言实现)
本文属于原创,转载请注明来源. 在上一篇博文中,详细介绍了2-3树的操作(具体地址:https://www.cnblogs.com/outerspace/p/10861488.html),那么对于更多 ...
- 【组策略】1.组策略介绍group policy
组策略介绍group policy 高效学习法,念念不忘,必有回响. 分享一个高效学习思维,潜意识思考.就是在您没有大量时间的情况下,学习十分钟. 然后离开去完成别的事情的时候,大脑潜意识中还会继续思 ...
- java 内部编译异常的处理方法
1.可能存在的问题. 在cmd 输入 java -version 和javac -version 检验java的环境是否正常,不正常就卸载重装. 搞定!
- kafka学习(五)
kafka可靠的数据传递 kafka可靠性保证 ACID 是关系型数据库保证数据的规范,指的是原子性,一致性,隔离性和持久性,这是数据库给出的可靠性保证. kafka给出的保证是什么? 1.k ...
- vue组件注册(极客时间Vue视频笔记)
vue组件注册 组件是为了方便代码复用,只需引入组件即可在不同的地方使用想同的功能代码 <body> <div class="app"> <todo- ...
- JavaScript Return Object.Type
var getType = function(obj) { if (obj == null) { return String(obj); } return typeof obj === 'object ...