php面试专题---MySQL分表
php面试专题---MySQL分表
一、总结
一句话总结:
分库分表要数据达到一定的量级才用,这样才有效率,不然利不一定大于弊,可能会增加一次I/O消耗
1、分库分表的使用量级是多少?
单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
2、分库分表的使用场景?
当产品运营很多年时数据量就会变的很大,如QQ的用户表,不知道QQ有多少用户,而且一个人可能有多个QQ号,如订单表,比如淘宝的订单数据有多少,都是惊人的数据量
3、水平分表的标准及实例是什么?
1、根据业务:水平分割最重要的是找到分割的标准,不同的表应根据业务找出不同的标准
2、不同手机号头:用户表可以根据用户的手机号段进行分割如user183、user150、user153、user189等,每个号段就是一张表
3、id除3的余数:用户表也可以根据用户的id进行分割,加入分3张表user0,user1,user2,如果用户的id%3=0就查询user0表,如果用户的id%3=1就查询user1表
4、时间:对于订单表可以按照订单的时间进行分表
4、数据库分片方案?
客户端代理: 分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。 当当网的 Sharding-JDBC 、阿里的TDDL是两种比较常用的实现。
中间件代理: 在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。 我们现在谈的 Mycat、360的Atlas、网易的DDB等等都是这种架构的实现。
二、MySQL性能优化(五):分表
转自或参考:MySQL性能优化(五):分表
https://blog.csdn.net/vbirdbest/article/details/81084182
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/vbirdbest/article/details/81084182
一:为什么要分表?
- 如果一个表的每条记录的内容很大,那么就需要更多的IO操作,如果字段值比较大,而使用频率相对比较低,可以将大字段移到另一张表中,当查询不查大字段的时候,这样就减少了I/O操作
- 如果一个表的数据量很少,那么查询就很快;如果表的数据量非常非常大,那么查询就变的比较慢;也就是表的数据量影响这查询的性能。
- 表中的数据本来就有独立性,例如分别记录各个地区的数据或者不同时期的数据,特别是有些数据常用,而另外一些数据不常用。
大表对DDL操作有一定的影响,如创建索引,添加字段
修改表结构需要长时间锁表,会造成长时间的主从延迟,影响正常的数据操作
当产品运营很多年时数据量就会变的很大,如QQ的用户表,不知道QQ有多少用户,而且一个人可能有多个QQ号,如订单表,比如淘宝的订单数据有多少,都是惊人的数据量。单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
二:分割方式
分表有两种分割方式,一种垂直分割另一种水平分割。
①:垂直分割
简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。 垂直分割一般用于拆分大字段和访问频率低的字段,分离冷热数据。
垂直分割适用于记录不是非常多的,但是字段却很多,这样占用空间比较大,检索时需要执行大量的I/O,严重降低了性能,这个时候需要把大的自读那拆分到另一个表中,并且该表与源表时一对一关系。
垂直分割比较常见:
- 例如博客系统中的文章表,比如文章tbl_articles(id, titile, summary, content, user_id, create_time),因为文章中的内容content字段可能会比较长,如果放在tbl_articles中会严重影响文章表的查询速度,所以将内容放到tbl_articles_detail(article_id, content),像文章列表只需要查询tbl_articles中的字段即可,如果想要查询文章的具体内容就关联tbl_articles_detail,
- 像我们经常看到的tbl_order表有对应的tbl_order_detail, 就是减少order字段的数量,将一些使用频率相对较低的放在detail详情表中
垂直拆分的优点: 可以使得行数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。
垂直拆分的缺点: 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂。
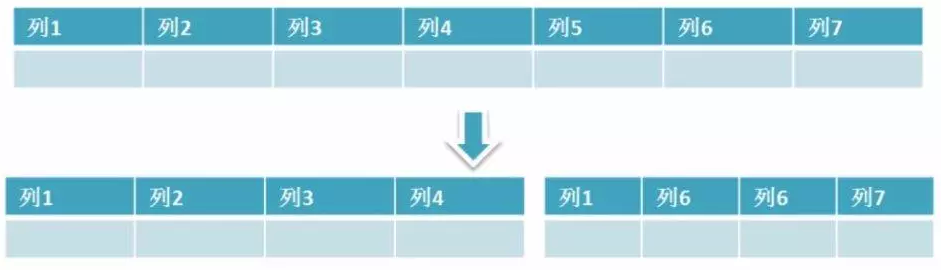
②:水平分割
水平拆分是指数据表行的拆分,表的行数超过500万行或者单表容量超过10GB时,查询就会变慢,这时可以把一张的表的数据拆成多张表来存放。水平分表尽可能使每张表的数据量相当,比较均匀。举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
水品拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以水品拆分最好分库。
水平拆分能够支持非常大的数据量存储,应用端改造也少,但分片事务难以解决,跨界点Join性能较差,逻辑复杂。
水平拆分会给应用增加复杂度,它通常在查询是需要多个表名,查询所有数据需要union操作。在许多数据库应用中,这种复杂性会超过它带来的优点,因为只要索引关键字不大,则在索引用于查询时,表中增加2-3倍数据量,查询时也就增加读一个索引层的磁盘次数,所以水平拆分要考虑数据量的增长速度,根据实际情况决定是否需要对表进行水平拆分。
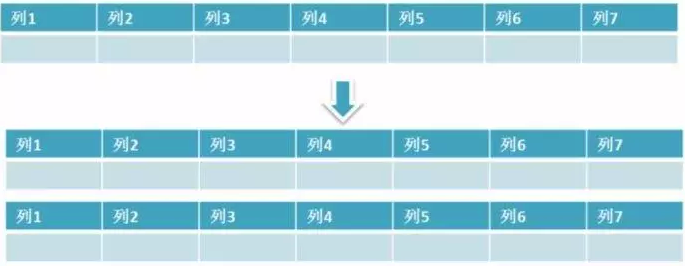
例如:电话账单就可以分成多个表:最近3个月的账单数据存在一个表,3个月前的历史账单存放到另一种表,超过一年的历史账单可以存储到单独的存储介质上,这种拆分是最常用的水平拆分方法。
水平分割标准
水平分割最重要的是找到分割的标准,不同的表应根据业务找出不同的标准
- 用户表可以根据用户的手机号段进行分割如user183、user150、user153、user189等,每个号段就是一张表
- 用户表也可以根据用户的id进行分割,加入分3张表user0,user1,user2,如果用户的id%3=0就查询user0表,如果用户的id%3=1就查询user1表
- 对于订单表可以按照订单的时间进行分表
三 数据库分片方案
客户端代理: 分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。 当当网的 Sharding-JDBC 、阿里的TDDL是两种比较常用的实现。
中间件代理: 在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。 我们现在谈的 Mycat、360的Atlas、网易的DDB等等都是这种架构的实现。
四:中间表查询:大表统计
创建一个中间表,中间表的结构和原始表结构一样,或多字段,将原始表中的部分数据转移到中间表,然后对中间表进行统计。
中间表复制源表部分数据,并且与源表相隔离,在中间表上做统计查询不会对在线应用产生负面影响
中间表上可以灵活的添加索引增加临时用的新字段,从而达到提高统计查询效率和辅助统计查询作用。
Sharding-JDBC+JPA|MyBatis+Druid分库分表实现: https://blog.csdn.net/vbirdbest/article/details/81176134
php面试专题---MySQL分表的更多相关文章
- php面试专题---mysql数据库分库分表
php面试专题---mysql数据库分库分表 一.总结 一句话总结: 通过数据切分技术将一个大的MySQLServer切分成多个小的MySQLServer,既攻克了写入性能瓶颈问题,同一时候也再一次提 ...
- php面试专题---MySQL分区
php面试专题---MySQL分区 一.总结 一句话总结: mysql的分区操作还比较简单,好处是也不用自己动手建表进行分区,和水平分表有点像 1.mysql分区简介? 一个表或索引-->N个物 ...
- 总结下Mysql分表分库的策略及应用
上月前面试某公司,对于mysql分表的思路,当时简要的说了下hash算法分表,以及discuz分表的思路,但是对于新增数据自增id存放的设计思想回答的不是很好(笔试+面试整个过程算是OK过了,因与个人 ...
- php面试专题---MYSQL查询语句优化
php面试专题---MYSQL查询语句优化 一.总结 一句话总结: mysql的性能优化包罗甚广: 索引优化,查询优化,查询缓存,服务器设置优化,操作系统和硬件优化,应用层面优化(web服务器,缓存) ...
- php面试专题---MySQL常用SQL语句优化
php面试专题---MySQL常用SQL语句优化 一.总结 一句话总结: 原理,万变不离其宗:其实SQL语句优化的过程中,无非就是对mysql的执行计划理解,以及B+树索引的理解,其实只要我们理解执行 ...
- php面试专题---Mysql索引类型、介绍及优点
php面试专题---Mysql索引类型.介绍及优点 一.总结 一句话总结: 精品视频讲解里面的资料来源也是通过各种资料,比如博客.书等,只不过是基于讲解者的知识体系有整理的过程 1.B-Tree索引三 ...
- php面试专题---Mysql索引原理及SQL优化
php面试专题---Mysql索引原理及SQL优化 一.总结 一句话总结: 注意:只写精品 1.为表设置索引要付出代价 是什么? 存储空间:一是增加了数据库的存储空间 修改插入变动索引时间:二是在插入 ...
- mysql分表和表分区详解
为什么要分表和分区? 日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能 ...
- MySQL分表(Partition)学习研究报告
最近在开发一个新的项目,可能会产生大数据量,需要对部分表进行分表操作,故来研究学习MySQL的分表功能. 由于实验报告已经写成Exlce文件了,各位看过就直接下载吧:MySQL分表分析报告.xls 以 ...
随机推荐
- Oracle创建表 创建库 数据恢复
--建用户CREATE USER szs IDENTIFIED BY szs DEFAULT TABLESPACE NN_DATA01 TEMPORARY TABLESPACE temp;--用户赋权 ...
- [BNDSOJ] #1106代码
#include<bits/stdc++.h> using namespace std; ]; ][]; int n; bool check(int i,int j) { ]==]==]= ...
- BZOJ1185[HNOI2007] 最小矩形覆盖(旋转卡壳)
BZOJ1185[HNOI2007] 最小矩形覆盖 题面 给定一些点的坐标,要求求能够覆盖所有点的最小面积的矩形,输出所求矩形的面积和四个顶点的坐标 分析 首先可以先求凸包,因为覆盖了凸包上的顶点,凸 ...
- python 更快地判断数字的奇数还是偶数
使用 按位与运算符(&) 将能更加快速地判断一个整数是奇数还是偶数 使用举例如下: def check_number(n): if n & 1: return '奇数' else: r ...
- window.onload后跟函数 和跟函数名的区别【window.onload = asd() 和 window.onload = asd 】
window.onload:页面加载完毕执行[DOM tree + 外部图片 + 资源] <script> function asd(){ return 10; } window.onlo ...
- python 字符串 string模块导入及用法
字符串也是一个模块,有自己的方法,可以通过模块导入的方式来调用 1,string模块导入 import string 2, 其用法 string.ascii_lowercase string.dig ...
- C++对象构造时,构造函数运行时并不知道VT的存在
class A {public: A() { init(); } virtual void init() { printf("A::init\n"); }}; class B : ...
- JavaScript 模块化简析
关于模块化,最直接的表现就是我们写的 require 和 import 关键字,如果查阅相关资料,就一定会遇到 CommonJS .CMD AMD 这些名词,以及 RequireJS.SeaJS 等陌 ...
- js的事件流理解
面试问到js的事件流,当时说的不是很清楚,现在觉得有必要把这个弄清楚. 事件捕获和事件冒泡 事件流描述的是从页面中接收事件的顺序,也可理解为事件在页面中传播的顺序. 事件流主要分为两种,即事件捕获和事 ...
- int型、char*、string、的swap算法
1.俩整数,不使用中间变量交换其值: int& intswap(int& a, int& b) { b ^= a; a ^= b; b ^= a; return b; } 2. ...