学习笔记64_k邻近算法
1 .假定已知数据的各个属性值,以及其类型,例如:
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类别 |
| m1 | 3 | 104 | 爱情片 |
| m2 | 2 | 100 | 爱情片 |
| m3 | 1 | 81 | 爱情片 |
| m4 | 2 | 90 | 爱情片 |
| w1 | 101 | 10 | 动作片 |
| w2 | 99 | 5 | 动作片 |
| w3 | 98 | 2 | 动作片 |
上述数据称为训练数据。
如果有新的电影, k1 , 18 , 90 ,未知
| 电影名称 | 与未知电影的距离 |
| m1 | 20.5 |
| m2 | 18.7 |
| m3 | 19.2 |
| m4 | 21 |
| w1 | 115.3 |
| w2 | 117.4 |
| w5 | 118.9 |
距离 : 通过一定的计算方法获得 , 总体来说,距离 = f (k1打斗镜头,k1接吻镜头,m1打斗镜头,m1接吻镜头)
如果 k1与 某些电影 最接近,这里,就是3个电影最接近, 所以K1为爱情片,这里K可以为3,或2 ,或1都行。
***如果出现了距离为 50的片1部,它既不是爱情片,也不是动作片,那么,由于
K邻近算法:
1.存在一个样本数据集合, 且样本中,每个数据都存在标签(已经分好类)
2.输入没有标签的新数据后(没有分类的),将新数据的每个特征值,使用一定的办法,与样本中的特征进行比较,然后提取出那些最近似(距离最小)的数据的类型,其中出现最多的类型,作为自己的类型。
***** 一般来说,如果有大量的数据的时候,只需要遍历出K个距离足够小的样本,然后从样本中,选择出现类型最多的分类,作为新数据的分类。
关键点:
1.K的取值(根据数据量,以及各个分类占有的百分比取)。
2.距离如何计算。
3.如何界定距离足够小。
*************************************************************************************************
使用K近邻算法,进行简单的图形识别:
简单: 要识别的东西的特征比较明显;图片颜色有比较强的对比度;图片刚好括着要识别的东西;要识别的东西放得比较正 等等。
***若果不满足简单,那么就需要预处理,将图片简单化*****
假设有图片:

图片的数据是像素,假设图片的数据格式:
| (r11,g11,b11) | (r12,g12,b12) | (r13,g13,b13) | ... |
| (r21,g21,b21) | ... | ... | ... |
| (r31,g31,b31) | ... | ... | ... |
| ... | ... | ... | ... |
这样的数据结构,假设有大量图片,对每个图片:
第一步:读取图片数据,然后上述的数据结构。
第二步:归一化,如上图,颜色可以分为2类,选择 这个颜色的 RGB运算值为1,其他为0
这个颜色的 RGB运算值为1,其他为0
*实际上,每个训练数据的图片,颜色可能都是不一样的,可以使用聚类:
情况可能有如下: 1. 只有两种颜色,如果某种颜色的比例占少数,那么这个颜色运算值应该为1;
2. 三种以上颜色,如果某种颜色的比例占多数,那么这个颜色运算值应该为1;
(归一化的算法很多。)

第三步:形成 特征-分类:
*第n行值,是指第n行中,1的总数。
| 第1行值 | 第2行值 | 第3行值 | ... | 数字类型 |
| 5 | 9 | 10 | ... | 2 |
| 5 | 5 | 5 | ... | 1 |
| 6 | 8 | 11 | ... | 2 |
| ... | ... | ... | ... | 3 |
| ... | ... | ... | ... | 4 |
| ... | ... | ... | ... | ... |
算法使用:
1.如果要识别新的图片,首先要执行上面 一,二,三部;
2.求距离:
d = Math.sqrt( d1² + d2² + ............ )
遍历出K个距离足够小的 样本
3. 在K个样本中,找出“数字类型”出现最多的 类型,作为 新的图片 所识别的数字。
除了使用MSQ(均方差,也就是d平方)的方法外,对于样本属于哪一类,还有使用夹角来衡量:
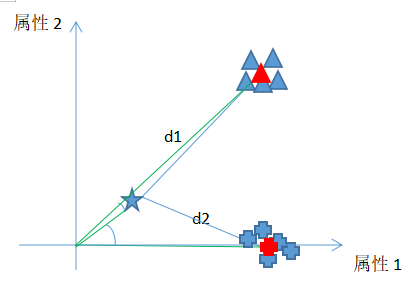
假如属性1为数学成绩,属性2位语文成绩,三角形为“均衡生”,而加号为“偏科生”,那么,要认定星号样本属于“均衡生”还是“偏科生”,
显然应该是“均衡生”,但是d1>d2,所以用空间夹角最好(联想向量点积计算)。
补充一点,这个“距离”,其实可以联想到神经网络中的“损失函数”
学习笔记64_k邻近算法的更多相关文章
- GMM高斯混合模型学习笔记(EM算法求解)
提出混合模型主要是为了能更好地近似一些较复杂的样本分布,通过不断添加component个数,能够随意地逼近不论什么连续的概率分布.所以我们觉得不论什么样本分布都能够用混合模型来建模.由于高斯函数具有一 ...
- 强化学习-学习笔记7 | Sarsa算法原理与推导
Sarsa算法 是 TD算法的一种,之前没有严谨推导过 TD 算法,这一篇就来从数学的角度推导一下 Sarsa 算法.注意,这部分属于 TD算法的延申. 7. Sarsa算法 7.1 推导 TD ta ...
- <机器学习实战>读书笔记--k邻近算法KNN
k邻近算法的伪代码: 对未知类别属性的数据集中的每个点一次执行以下操作: (1)计算已知类别数据集中的点与当前点之间的距离: (2)按照距离递增次序排列 (3)选取与当前点距离最小的k个点 (4)确定 ...
- 【学习笔记】 Adaboost算法
前言 之前的学习中也有好几次尝试过学习该算法,但是都无功而返,不仅仅是因为该算法各大博主.大牛的描述都比较晦涩难懂,同时我自己学习过程中也心浮气躁,不能专心. 现如今决定一口气肝到底,这样我明天就可以 ...
- 挑子学习笔记:DBSCAN算法的python实现
转载请标明出处:https://www.cnblogs.com/tiaozistudy/p/dbscan_algorithm.html DBSCAN(Density-Based Spatial Clu ...
- 【学习笔记】分类算法-k近邻算法
k-近邻算法采用测量不同特征值之间的距离来进行分类. 优点:精度高.对异常值不敏感.无数据输入假定 缺点:计算复杂度高.空间复杂度高 使用数据范围:数值型和标称型 用例子来理解k-近邻算法 电影可以按 ...
- R语言学习笔记—K近邻算法
K近邻算法(KNN)是指一个样本如果在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.即每个样本都可以用它最接近的k个邻居来代表.KNN算法适 ...
- 普通平衡树学习笔记之Splay算法
前言 今天不容易有一天的自由学习时间,当然要用来"学习".在此记录一下今天学到的最基础的平衡树. 定义 平衡树是二叉搜索树和堆合并构成的数据结构,它是一 棵空树或它的左右两个子树的 ...
- 【算法学习笔记】Meissel-Lehmer 算法 (亚线性时间找出素数个数)
「Meissel-Lehmer 算法」是一种能在亚线性时间复杂度内求出 \(1\sim n\) 内质数个数的一种算法. 在看素数相关论文时发现了这个算法,论文链接:Here. 算法的细节来自 OI w ...
随机推荐
- 前端深入之css篇|你真的了解“权重”吗?
写在前面 权重这个概念,相信对许多进行过前端开发的小伙伴来说肯定并不陌生,有时候一个样式添加不上,我们就会一个 !important 怼上去,一切就好像迎刃而解了.但还有的时候,!important也 ...
- centos7.x 部署主、从DNS服务器
1.准备 例:两台192.168.219.146(主), 192.168.219.147(从), 域名www.panyangduola.com 主.从DNS服务器均需要安装bind.bind-chro ...
- 快学Scala 第二十二课 (apply和unapply)
apply和unapply: apply方法经常用在伴生对象中,用来构造对象而不用显式地使用new. unapply是当做是伴生对象的apply方法的反向操作.apply方法接受构造参数,然后将他们变 ...
- Pycharm 快捷键大全 2019.2.3
在Pycharm中打开Help->Keymap Reference可查看默认快捷键帮助文档,文档为PDF格式,位于安装路径的help文件夹中,包含MAC操作系统适用的帮助文档. 下图为2019. ...
- Python中的option Parser
一般来说,Python中有两个内建的模块用于处理命令行参数: 一个是 getopt,<Deep in python>一书中也有提到,只能简单处理 命令行参数: 另一个是 optparse, ...
- 浅谈sqlserver的事务锁
锁的概述 一. 为什么要引入锁 多个用户同时对数据库的并发操作时会带来以下数据不一致的问题: 丢失更新 A,B两个用户读同一数据并进行修改,其中一个用户的修改结果破坏了另一个修改的结果,比如订票系统 ...
- Java自动化测试框架-02 - TestNG之理论实践 - 纸上得来终觉浅,绝知此事要躬行(详细教程)
理论 TestNG,即Testing, NextGeneration,下一代测试技术,是一套根据JUnit 和NUnit思想而构建的利用注释来强化测试功能的一个测试框架,即可以用来做单元测试,也可以用 ...
- postman环境变量设置
1.点击小齿轮进入到环境变量添加页面,点击add添加环境变量 2.输入变量名称和变量值 3.添加成功 4.接口中设置变量
- .NET Core 3.0 里新的JSON API
为什么需要新的JSON API? JSON.NET 大家都用过,老版本的ASP.NET Core也依赖于JSON.NET. 然而这个依赖就会引起一些版本问题:例如ASP.NET Core某个版本需要使 ...
- 2019.10.24 CSP%你赛第二场d1t3
题目描述 Description 精灵心目中亘古永恒的能量核心崩溃的那一刻,Bzeroth 大陆的每个精灵都明白,他们的家园已经到了最后的时刻.就在这危难关头,诸神天降神谕,传下最终兵器——潘少拉魔盒 ...