Python—字符串和常用数据结构
序言:这一章我们学习字符串、列表、元组、字典 等常用存储结构
1. 字符串
所谓字符串,就是由零个或多个字符组成的有限序列 ,简单来说:双引号或者单引号中的数据,就是字符串
通过下面代码,我们来了解一下字符串的使用
# -*- coding:utf-8 -*-
def main():
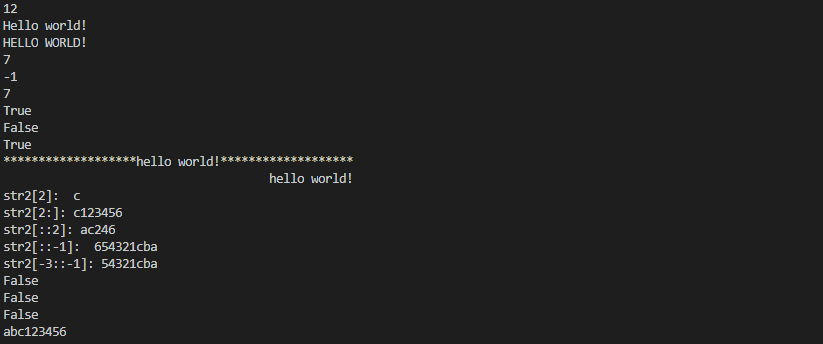
str1 = 'hello world!'
#通过len 计算函数字符串的长度
print(len(str1))
#获得字符串首字母大写的拷贝
print(str1.capitalize())
#获得字符串全大写的拷贝
print(str1.upper())
#查询or 是否被包含str1中 包含返回索引值
print(str1.find("or"))
#查询and 是否被包含str1
print(str1.find("and"))
#index 与find类似 但是找不到会抛异常
print(str1.index("or"))
#print(str1.index("or"))
#检查字符串是否以指定的字符串开头
print(str1.startswith("he"))
print(str1.startswith("1he"))
#检查字符串是否以指定的字符串结尾
print(str1.endswith("!"))
#将字符串以指定的宽度居中 并在两边添加指定的字符
print(str1.center(50,"*"))
print(str1.rjust(50," "))
str2 = "abc123456 ";
# 字符串切片:从字符串中取出指定位置的字符
print("str2[2]: ",str2[2])
print("str2[2:]:",str2[2:])
print("str2[::2]:",str2[::2])
print("str2[::-1]:",str2[::-1])
print("str2[-3::-1]:",str2[-3::-1])
# 检查字符串是否由数字构成
print(str2.isdigit())
# 检查字符串是否由字母构成
print(str2.isalpha())
# 检查字符串是否由数字字母组成
print(str2.isalnum())
#去除两侧空格
print(str2.strip())
if __name__ == '__main__':
main()
输出结果
str = "helloworld"
| 方法 | 说明 | 结果 |
|---|---|---|
| len(str) | 字符串长度 | 10 |
| str.capitalize() | 字符串首字母大写 | Helloworld |
| str.upper() | 字符串全大写 | HELLOWORLD |
| str.find("or") | 检测 "or" 是否包含在 str 中,如果是返回开始的索引值,否则返回-1 | 6 |
| str.startswith("h") | 检查字符串是否以指定的字符串开头 | True |
| str.endswith("!") | 检查字符串是否以指定的字符串结尾 | False |
| str.center(20,"*") | 将字符串以指定的宽度居中 并在两边添加指定的字符 | *****helloworld***** |
| str.isdigit() | 检查字符串是否由数字构成 | False |
| str.isalpha() | 检查字符串是否由字母构成 | True |
| str.strip() | 去除两侧空格 | helloworld |
2. 列表
列表是Python中内置有序、可变序列,列表的所有元素放在一对中括号“[]”中,并使用逗号分隔开
列表常用方法
| 方法 | 说明 |
|---|---|
| lst.append(x) | 将元素x添加至列表lst尾部 |
| lst.extend(L) | 将列表L中所有元素添加至列表lst尾部 |
| lst.insert(index, x) | 在列表lst指定位置index处添加元素x,该位置后面的所有元素后移一个位置 |
| lst.remove(x) | 在列表lst中删除首次出现的指定元素,该元素之后的所有元素前移一个位置 |
| lst.pop([index]) | 删除并返回列表lst中下标为index(默认为-1)的元素 |
| lst.clear() | 删除列表lst中所有元素,但保留列表对象 |
| lst.index(x) | 返回列表lst中第一个值为x的元素的下标,若不存在值为x的元素则抛出异常 |
| lst.count(x) | 返回指定元素x在列表lst中的出现次数 |
| lst.reverse() | 对列表lst所有元素进行逆序 |
| lst.sort(key=None, reverse=False) | 对列表lst中的元素进行排序,key用来指定排序依据,reverse决定升序(False),还是降序(True) |
| lst.copy() | 返回列表lst的浅复制 |
2.1 列表的增删改查
def main():
list1 = [1,3,5,7,100]
print(list1)
list2 = ['hello'] * 5
print(list2)
# 计算列表的长度
print("列表的长度为:",len(list2))
#下标索引
print("索引为0的元素:",list1[0])
print("索引为3的元素:",list1[3])
print("索引为-1的元素:",list1[-1])
#修改元素
list1[2] = 300
print("修改结果:",list1)
#添加元素
list1.append(121)
print("append添加元素的结果:",list1)
list1.insert(1,676);
print("insert插入元素的结果:",list1)
list1 += [700,800]
print("+=添加元素:",list1)
#删除元素
list1.remove(700) #移除某个元素
print("remove移除元素:",list1)
list1.pop(); #移除列表最后一位元素
print("pop移除最后一位",list1)
del list1[0] #移除某个下标的元素
print("del移除:",list1)
list1.clear() #清空列表
print("清空后的列表:",list1)
if __name__ == "__main__":
main()
输出结果

2.2 列表的切片和排序
1、列表的切片操作
"""
列表的切片操作
version:0.1
author:coke
"""
def main():
names = ["A","B","C","D"]
names += ["E","F","G"]
# 循环遍历列表元素
for name in names:
print(name,end = " ")
print()
# 列表切片
names2 = names[1:4]
print("names2:",names2)
# 可以完整切片操作来复制列表
names3 = names[:]
print("names3:",names3)
# 可以通过反向切片操作来获得倒转后的列表的拷贝
names4 = names[::-1]
print("names4:",names4)
if __name__ == "__main__":
main()
输出结果

2、列表的排序操作
"""
列表的排序操作
version:0.1
author:coke
"""
def main():
list1 = ["A","Be","C","D","E"]
list2 = sorted(list1)
print("list2:",list2)
# sorted函数返回列表排序后的拷贝不会修改传入的列表
list3 = sorted(list1,reverse=True)
print("list3:",list3)
# 通过key关键字参数指定根据字符串长度进行排序 而不是默认的字母表顺序
list4 = sorted(list1,key=len)
print("list4:",list4)
if __name__ == "__main__":
main()
输出结果

2.3 生成式语法
我们还可以使用列表的生成式语法来创建列表
"""
生成试语法创建列表
version:0.1
author:coke
"""
import sys
def main():
f = [x for x in range(1,10)]
print("f:",f)
f = [ x + y for x in "ABCDE" for y in "1234567"]
print("f:",f)
#通过列表的生成表达式语法创建列表容器
#用这种语法创建列表之后 元素已经准备就绪所有需要耗费较多的内存空间
f = [x ** 2 for x in range(1,1000)]
print("生成试语法:",sys.getsizeof(f)) #9024
#print(f)
#请注意下面的代码创建的不是一个列表 而是一个生成器对象
#每次生成器对象可以获取到数据 但它不占用额外的空间存储数据
#每次需要数据的时候就通过内部运算得到数据
f = (x ** 2 for x in range(1,1000))
print("生成器对象:",sys.getsizeof(f))
print(f)
"""
for val in f:
print(val)
print(sys.getsizeof(f))
"""
if __name__ == "__main__":
main()
输出结果

除了上面提到的生成器语法,Python中还有另外一种定义生成器的方式,就是通过yield关键字将一个普通函数改造成生成器函数。下面的代码演示了如何实现一个生成斐波拉切数列的生成器。所谓斐波拉切数列可以通过下面递归的方法来进行定义:
"""
定义生成器
version:0.1
author:coke
"""
def fib(n):
a,b = 0,1
for _ in range(n):
a,b = b, a+b
yield a
def main():
for val in fib(20):
print(val)
if __name__ == '__main__':
main()
3. 元组
Python的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号。
def main():
# 定义元组
t = ('骆昊', 38, True, '四川成都')
print(t)
# 获取元组中的元素
print(t[0])
print(t[3])
# 遍历元组中的值
for member in t:
print(member)
# 重新给元组赋值
# t[0] = '王大锤' # TypeError
# 变量t重新引用了新的元组原来的元组将被垃圾回收
t = ('王大锤', 20, True, '云南昆明')
print(t)
# 将元组转换成列表
person = list(t)
print(person)
# 列表是可以修改它的元素的
person[0] = '李小龙'
person[1] = 25
print(person)
# 将列表转换成元组
fruits_list = ['apple', 'banana', 'orange']
fruits_tuple = tuple(fruits_list)
print(fruits_tuple)
if __name__ == '__main__':
main()
这里有一个非常值得探讨的问题,我们已经有了列表这种数据结构,为什么还需要元组这样的类型呢?
- 元组中的元素是无法修改的,事实上我们在项目中尤其是多线程环境(后面会讲到)中可能更喜欢使用的是那些不变对象(一方面因为对象状态不能修改,所以可以避免由此引起的不必要的程序错误,简单的说就是一个不变的对象要比可变的对象更加容易维护;另一方面因为没有任何一个线程能够修改不变对象的内部状态,一个不变对象自动就是线程安全的,这样就可以省掉处理同步化的开销。一个不变对象可以方便的被共享访问)。所以结论就是:如果不需要对元素进行添加、删除、修改的时候,可以考虑使用元组,当然如果一个方法要返回多个值,使用元组也是不错的选择。
- 元组在创建时间和占用的空间上面都优于列表。
4.集合
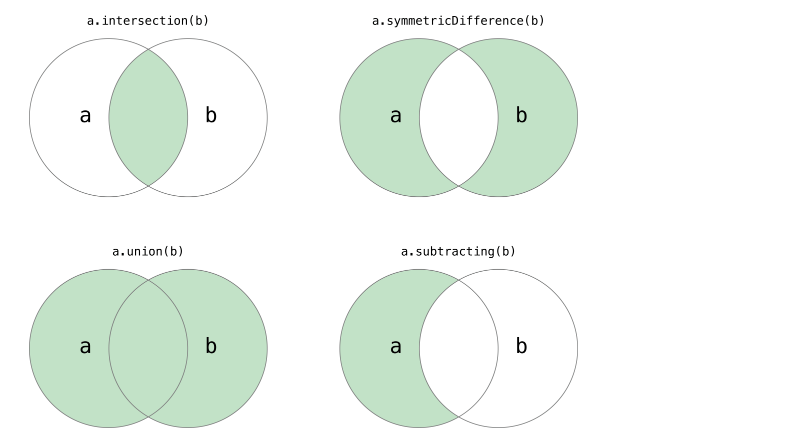
Python中的集合跟数学上的集合是一致的,不允许有重复元素,而且可以进行交集、并集、差集等运算。
"""
使用集合
version:0.1
author:coke
"""
def main():
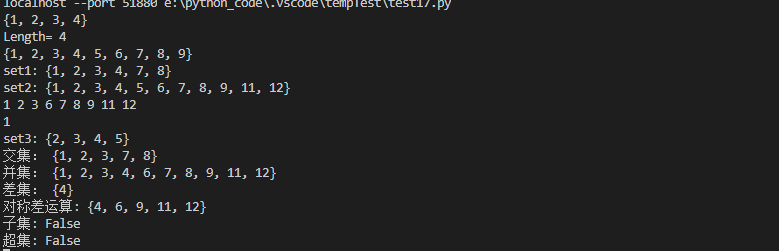
set1 = {1,2,3,3,2,4}
print(set1)
# len() 求集合的长度
print('Length=',len(set1))
set2 = set(range(1,10))
print(set2)
set1.add(7)
set1.add(8)
set2.update([11,12])
print("set1:",set1)
print("set2:",set2)
# 移除元素5
set2.discard(5)
# remove的元素 如果不存在会引发keyError
if 4 in set2:
set2.remove(4)
#遍历集合容器
for ele in set2:
print(ele,end=" ")
print(" ")
#将元组转换成集合
set3 = set((1,2,3,4,5))
print(set3.pop())
print("set3:",set3)
# 集合的交集、并集、差集、对称差运算
print("交集:",set1 & set2)
print("并集:",set1 | set2)
print("差集:",set1 - set2)
print("对称差运算:",set1 ^ set2)
#判断子集和超集
print("子集:",set1 <= set2)
#print(set1.issuperset(set2))
print("超集:",set1 >= set2)
#print(set1.issubset(set2))
if __name__ == "__main__":
main()
输出结果
5. 字典
字典和列表一样,也能够存储多个数据。字典的每个元素由2部分组成,键:值。例如 'name':'班长' ,'name'为键,'班长'为值
5.1 字典的增删改查
1、添加元素
info = {'name':'班长', 'sex':'f', 'address':'地球亚洲中国北京'}
# print('id为:%d'%info['id'])#程序会终端运行,因为访问了不存在的键
newId = input('请输入新的学号:')
info['id'] = newId
print('添加之后的id为:',info['id'])
2、修改元素
info = {'name':'班长', 'id':100, 'sex':'f', 'address':'地球亚洲中国北京'}
newId = input('请输入新的学号:')
info['id'] = int(newId)
print('修改之后的id为:',info['id'])
3、删除元素
del删除指定元素clear()清空整个字典
info = {'name':'班长', 'sex':'f', 'address':'地球亚洲中国北京'}
print("删除前:",info)
del info['name']
print('删除后:',info)
info.clear()
print("清空后:",info)
4、查找某个元素
字典在查询某个元素时,若该字典没有所查询的元素会报错,所以查询前最好进行判断
info = {'id':1,'name':'班长', 'sex':'f', 'address':'地球亚洲中国北京'}
print("查询:",info)
print("查询存在的元素:",info['id'])
#print("查询不存在的元素:",info['age']) keyError
print("查询不存在的元素:",info['age'] if 'age' in info else "元素不存在")
5.2 字典的常见操作
1、len():测量字典键值对的个数
dict = {"name":"Jack","age":11}
print(len(dict))
2、 keys():返回一个包含字典所有key的列表
dict = {"name":"Jack","age":11}
print(dict.keys())
3、values():返回一个包含字典所有value的列表
dict = {"name":"Jack","age":11}
print(dict.values())
4、items():返回一个包含所有(键,值)元组的列表
dict = {"name":"Jack","age":11}
print(dict.items)
5、字典遍历
"""
字典测试
version:0.1
author:coke
"""
info = {"name":"coke","age":11,"height":"198"}
print("遍历字典项--------------------第一种方式")
for item in info.items():
print(item)
print("遍历字典项--------------------第二种方式")
for key,value in info.items():
print("%s:%s"%(key,value))
Python—字符串和常用数据结构的更多相关文章
- PYTHON 100days学习笔记007-3:字符串和常用数据结构
目录 Day007:字符串和常用数据结构 1.使用字符串 2.使用列表 3.使用元组 4.使用字典 4.练习 4.1:在屏幕上显示跑马灯文字 4.2 设计一个函数产生指定长度的验证码,验证码由大小写字 ...
- Python学习-第二天-字符串和常用数据结构
Python学习-第二天-字符串和常用数据结构 字符串的基本操作 def main(): str1 = 'hello, world!' # 通过len函数计算字符串的长度 print(len(str1 ...
- Day7 字符串和常用数据结构
字符串和常用数据结构 使用字符串 第二次世界大战促使了现代电子计算机的诞生,当初的想法很简单,就是用计算机来计算导弹的弹道,因此在计算机刚刚诞生的那个年代,计算机处理的信息主要是数值,而世界上的第一台 ...
- Python字符串的常用操作学习
>>> name = "I love my job!" >>> name.capitalize() #首字母大写 'I love my job! ...
- python字符串,常用编码
Python的字符串和编码 1.常用编码 与python有关的编码主要有:ASCII.Unicode.UTF-8 其中ASCII如今可以视作UTF-8的子集 内存中统一使用Unicode编码(如记事本 ...
- 『无为则无心』Python序列 — 17、Python字符串操作常用API
目录 1.字符串的查找 @1.find()方法 @2.index()方法 @3.rfind()和rindex()方法 @4.count()方法 2.字符串的修改 @1.replace()方法 @2.s ...
- 【python基础】--常用数据结构
list tuple dict set四种常用数据结构 list list 有序的集合,可以随时添加.删除其中元素值; 支持list嵌套模式, >>> p = ['a','b']&g ...
- Python机器视觉编程常用数据结构与示例
本文总结了使用Python进行机器视觉(图像处理)编程时常用的数据结构,主要包括以下内容: 数据结构 通用序列操作:索引(indexing).分片(slicing).加(adding).乘(multi ...
- python学习之常用数据结构
前言:数据结构不管在哪门编程语言之中都是非常重要的,因为学校的课程学习到了python,所以今天来聊聊关于python的数据结构使用. 一.列表 list 1.列表基本介绍 列表中的每个元素都可变的, ...
随机推荐
- 使用flask-restful搭建API
最简单的例子 ---~~~~ 访问http://127.0.0.1:5000/ , 返回{"hello": "world"} from flask import ...
- 本地项目上传到github上最直接步骤
1.首先得有一个git账号(本地安装git) 2.git上创建一个project 3.回到本地你要提交文件夹位置 4.按住shift + 鼠标右键 选择在此处打开命令窗口 5.输入命令 git in ...
- 80后,天才程序员, Facebook 第一任 CTO,看看开挂的人生到底有多变态?
鸡仔说:今天介绍一位天才程序员--亚当·德安格洛(Adam D'Angelo),他被<财富>杂志誉为"科技界最聪明的人之一",大学去了被誉为"天才" ...
- ECMAScript---数据类型的分类
数据值是一门编程语言生产的材料,JS中包含的值有以下类型: 1.基本数据类型(值类型):包含 数字 number.字符串string .布尔 boolean .null(其他语言都有的类型) .und ...
- POJ 1661 暴力dp
题意略. 思路: 很有意思的一个题,我采用的是主动更新未知点的方式,也即刷表法来dp. 我们可以把整个路径划分成横向移动和纵向移动,题目一开始就给出了Jimmy的高度,这就是纵向移动的距离. 我们dp ...
- CodeForces 909C
题意略. 思路: 开始的时候,定义dp[i]:当前行在第i行,i~n有多少种排列方式,如果i为f,那么dp[i] = dp[i + 1],因为第i + 1条语句只能放在f后且向右缩进一位: 如果i为s ...
- JNI开发流程
交叉编译 在一个平台上去编译另一个平台上可以执行的本地代码 cpu平台 arm x86 mips 操作系统平台 windows linux mac os 原理 模拟不同平台的特性去编译代码 jni开发 ...
- Django之使用中间件解决前后端同源策略问题
问题描述 前端时间在公司的时候,要使用angular开发一个网站,因为angular很适合前后端分离,所以就做了一个简单的图书管理系统来模拟前后端分离. 但是在开发过程中遇见了同源策略的跨域问题,页面 ...
- 2019DX#2
Solved Pro.ID Title Ratio(Accepted / Submitted) 1001 Another Chess Problem 8.33%(1/12) 1002 Beau ...
- HDU- 6437.Videos 最“大”费用流 -化区间为点
参考和完全学习:http://www.cnblogs.com/xcantaloupe/p/9519617.html HDU-6437 题意: 有m场电影,电影分为两种,看一场电影可以得到对应的快乐值. ...