流式计算(一)-Java8Stream
大约各位看官君多少也听说了Storm/Spark/Flink,这些都是大数据流式处理框架。如果一条手机组装流水线上不同的人做不同的事,有的装电池,有的装屏幕,直到最后完成,这就是典型的流式处理。如果手机组装是先全部装完电池,再交给装屏幕的组,直到完成,这就是旧式的集合式处理。今天,就来先说说JDK8中的流,虽然不是很个特新鲜的话题,但是一个很好的开始,因为——思想往往比细节重要!
准备:
Idea2019.03/Gradle5.6.2/JDK11.0.4/Lambda
难度:新手--战士--老兵--大师
目标:
1.Lambda表达式使用
2.流的筛选/切片/查找/匹配/映射/归约操作
步骤:
为了遇见各种问题,同时保持时效性,我尽量使用最新的软件版本。代码地址:其中的day22,https://github.com/xiexiaobiao/dubbo-project.git
1.先来两个概念:
- 流(Stream):一个元素序列。位于包java.util.stream.Stream,注意这个序列是可以串行或并行处理的。有多种方式建立流,最常见的是从集合(Collection)对象获取,有序集合如List的流有序,Set的流则无序。
- Lambda表达式:流式处理的绝佳搭档!什么是Lambda表达式?略。哪里可以用Lambda表达式?需要实现一个函数式接口(只定义了一个抽象函数的接口)的地方就可以使用Lambda表达式,代替匿名类方式。源代码中com.biao.lambda包里,我写了一个简单的Lambda实例,供参考。
2.流式处理特点:
- 流水线:流操作可返回一个流,多个操作从而可形成一个链,
- 内部迭代:使用Iterator/forEach显式迭代器为外部迭代,流的迭代是流内部完成的,只需声明,是内部迭代,
- 一次使用:每个流只能消费一次,不能结束后又从头开始!
3.流的一般使用:
建立流:创建一个Stream对象,如从一个数据源来执行一个查询;
操作流:一个包含了各种操作的操作链;
结束流:一个终端操作,形成一个结果集或值
4.来个例子,假设这里有个com.biao.Fruit类:
@Data
public class Fruit {
private String name;
private String origin;
private Integer price;
}
我们要从一堆水果里,找前4种产自中国的名称是字母A开头的水果。这还不是小菜?几次使用Iterator或者forEach循环就实现了!
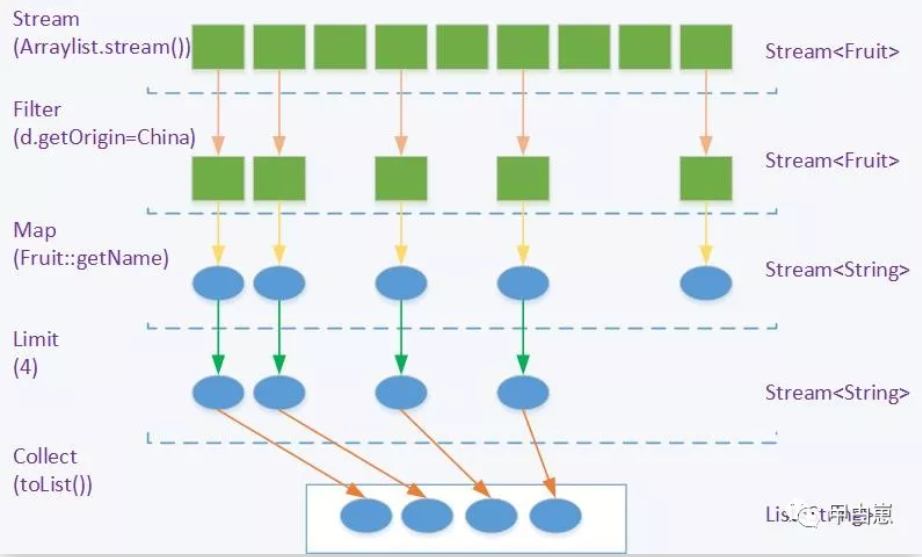
如果使用流处理,大致处理流程图示则如下,代码后面再聊:
5.流的主要操作:筛选/切片/查找/匹配/映射/归约
下面将一一道来:
筛选/切片:使用filter/skip/limit/distinct方法过滤。filter接收一个Predicate函数表达式,方法签名是T --> boolean,我们来实现上面的图示逻辑,至于JDK7的实现,看官君可以想一想,对比一下,com.biao.Application1代码实现片段:
// 创建流
Stream<Fruit> fruitStream = fruitList.stream();
// 过滤
Stream<Fruit> filteredStream = fruitStream.filter(d -> "China".equals(d.getOrigin()));
// 去掉重复元素
Stream<Fruit> distinctStream = filteredStream.distinct();
// 打印流中元素,forEach是终端操作,如果这里使用了,则collect方法无法使用,即一个流只能消费一次
// distinctStream.forEach(System.out::println);
// 跳过1个元素,
Stream<Fruit> skippedStream = distinctStream.skip(1);
// 切片,参数为maxSize
Stream<Fruit> limitStream = skippedStream.limit(4);
// 结束,collect方法是收集器,如果这里使用了,则forEach无法使用,即一个流只能有一个终端操作
List<Fruit> newList = limitStream.collect(Collectors.toList());
// 打印结果,lambda方式
newList.forEach(System.out::println); // 链式操作,和上面效果一样,一气呵成,真爽!
List<Fruit> newList2 = fruitList.stream()
.filter(d -> "China".equals(d.getOrigin()))
.distinct()
.skip(1)
.limit(4)
.collect(Collectors.toList());
// 打印结果集
newList2.forEach(System.out::println);
以上代码核心点:
- 尽量使用链式语法配合Lambda,简洁至极!
- 一个流只能有一个终端操作!即一个流只能被消费一次!
- filter方法的参数表达式可以进行逻辑复合运算,如and/not/or,
映射:对流中的每个元素应用映射函数,变换成新的对象。使用map方法,接受一个Function类型,函数签名是 T—> R,比如对以上Fruit流提取水果的名称,并过滤字母A开头的水果,com.biao.Application2代码实现片段:
// 创建流
Stream<Fruit> fruitStream = fruitList.stream();
//转换,变为String流
Stream<String> stringStream = fruitStream.map(Fruit::getName);
//过滤,名称以A开头
Stream<String> filteredStream = stringStream.filter(str -> "A".equals(String.valueOf(str.charAt(0))));
//终端操作,set自动去重复
Set<String> stringSet = filteredStream.collect(Collectors.toSet());
//打印结果集
stringSet.forEach(System.out::println); //链式语法实现,请君想象下JDK7的实现,
fruitList.stream()
.map(Fruit::getName)
.filter(str -> "A".equals(str.substring(0,1)))
.collect(Collectors.toSet())
.forEach(System.out::println);
我还写了个map映射+flatMap扁平化流例子,com.biao.Application3代码片段:
/**映射示例2:map映射+flatMap扁平化流*/
String[] arraysOfWords = {"Apple","Banana","Nuts","Olive"};
// 使用Arrays的静态方法创建流
Stream<String> stringStream = Arrays.stream(arraysOfWords);
// 对每个word映射为String[]
stringStream.map(word -> word.split(""))
// flatMap扁平化流,将生成的流组合成一个流
// 如果使用map(Arrays::stream),则生成由流元素组成的流
.flatMap(Arrays::stream)
// 去掉重复
.distinct()
// 终端操作,collect方法是收集器
.collect(Collectors.toList())
.forEach(System.out::println);
流的扁平化,一言以蔽之,flatmap方法让你把一个流中的每个值都换成一个的流(即流中的元素也是流),然后把所有的流连接起来成为一个流。
查找/匹配:StreamAPI通过allMatch,anyMatch,noneMatch,findFirst,findAny方法找到符合的元素,com.biao.Application4代码实现片段:
// 注意这里每个都要重建一个流
// 是否全部价格大于50
boolean almach = fruitList.stream().allMatch(fruit -> fruit.getPrice() > 50);
System.out.println(almach);
// 是否至少有一种产自America
boolean anyMatch = fruitList.stream().anyMatch(fruit -> "America".equals(fruit.getOrigin()));
System.out.println(anyMatch);
// 找出流中第3个,
Optional<Fruit> thirdOne = fruitList.stream().skip(2).findFirst();
// 存在则打印,防止NPE
thirdOne.ifPresent(System.out::println);
// 找出流中任意一个,,
Optional<Fruit> anyOne = fruitList.stream().findAny();
// ifPresent,值存在则执行操作,否则 do nothing!
anyOne.ifPresent(System.out::println);
以上代码核心点:
- 这里每个查找/匹配都要重建一个流,
- 找可能的第3个元素,skip(2).findFirst(),返回Optional T 类,解决返回null的NPE问题,这样即使不存在第3个元素,返回对象仍然可以继续做计算,
- findAny时,流水线将在后台进行优化使其只需走一遍,并在利用短路找到结果时立即结束
归约:使用reduce对流中元素累积计算,最后得到一个值。比如找到上面水果中价格最高的,计算出产自Japan的水果的总价格,com.biao.Application5代码实现片段:
// 注意这里每个都要重建一个流
int totalPrice = fruitList.stream()
.filter(fruit -> "Japan".equals(fruit.getOrigin()))
//映射转换为Integer流
.map(Fruit::getPrice)
//reduce归约计算
// 也可使用reduce(0,(a,b) -> a+b);
.reduce(0,Integer::sum);
System.out.println(totalPrice); /** reduce无初始值的归约计算 */
Optional<Integer> totalPrice2 = fruitList.stream()
.map(Fruit::getPrice)
.reduce((a,b) -> a+b);
// ifPresent,值存在则执行操作,否则 do nothing!
totalPrice2.ifPresent(System.out::println); /** reduce计算最大*/
Optional<Integer> maxPrice = fruitList.stream()
.map(Fruit::getPrice)
// 归约计算最大值:
// 这里也可以使用reduce((x,y) -> x>y?x:y)
.reduce(Integer::max);
// ifPresent,值存在则执行操作,否则 do nothing!
maxPrice.ifPresent(System.out::println); /** reduce计算最小值*/
Optional<Integer> minPrice = fruitList.stream()
.map(Fruit::getPrice)
// 归约计算最小值:也可以使用reduce((x,y) -> x<y?x:y)
.reduce(Integer::min);
// ifPresent,值存在则执行操作,否则 do nothing!
minPrice.ifPresent(System.out::println);
以上代码核心点:
- reduce的函数参数有几种重载,返回的值不一样,无初始值的返回Optional对象,
- Optional. ifPresent方法,Optional对象值存在则执行操作,否则 do nothing,
- map和reduce的连接通常称为map-reduce模式,源于google的搜索模式,
6.看完了上面的各种流操作,看官君也许会说,似乎也没啥大不了的啊,顶多是少写了几行代码,那请用集合式实现下相同逻辑!另请君回忆下,是否有过多层嵌套或者N多分支的if-elseif-else/switch-case场景?那现在就请试试流式写法!事实上我这里只是举了几个常规的应用例子而已,抓住下看官君的兴趣,StreamAPI还有其他强大的功能:
- 无限流、范围流:能直接创建无限流,再局部处理,
- Collect收集器的分区分组:将最终结果集按条件分区分组,类比SQL的groupBy,
- 流的parallel/sequential并行计算和顺序计算:声明式并行计算,无需为锁烦恼,
- 分支/合并ForkJoin框架的递归计算:多线程方式处理,还可自定义线程池参数,
- 同步/异步执行:使用CompletableFuture类实现更高效的异步处理,
总结:
1.流不仅仅是将外部迭代变为内部迭代,更是一种编程思想的转变,结合函数抽象,行为参数化,将函数作为参数,提升为与值一样的地位,威力巨大,这就是生产力。
2.流计算能大大简化编程,使用声明式语法,配合Lambda,写起代码根本停不下来!
3.后期会在看看其他Storm/Spark/Flink流式计算框架,发现点新鲜货。
全文结束!

推荐阅读:
- Dubbo学习系列之十六(ELK海量日志分析)
- Linux下Redis集群
- Dubbo学习系列之十五(Seata分布式事务方案TCC模式)
- Dubbo学习系列之十四(Seata分布式事务方案AT模式)
- Dubbo学习系列之十三(Mycat数据库代理)
流式计算(一)-Java8Stream的更多相关文章
- 流式计算(二)-Kafka Stream
前面说了Java8的流,这里还说流处理,既然是流,比如水流车流,肯定得有流的源头,源可以有多种,可以自建,也可以从应用端获取,今天就拿非常经典的Kafka做源头来说事,比如要来一套应用日志实时分析框架 ...
- 流式计算(三)-Flink Stream 篇一
原创文章,谢绝任何形式转载,否则追究法律责任! 流的世界,有点乱,群雄逐鹿,流实在太多,看完这个马上又冒出一个,也不知哪个才是真正的牛,据说Flink是位重量级选手,能流计算,还能批处理, 和其他伙 ...
- 搜索广告与广告网络Demand技术-流式计算平台
流式计算平台-Storm 我们以Storm为例来看流式计算的功能是什么. 下面内容引用自大圆的博客.在Storm中,一个实时应用的计算任务被打包作为Topology发布,这同Hadoop的MapRed ...
- 流式计算与计算抽象化------《Designing Data-Intensive Applications》读书笔记15
上篇的内容,我们探讨了分布式计算中的MapReduce与批处理.所以本篇我们将继续探索分布式计算优化的相关细节,并且分析MapReduce与批处理的局限性,看看流式计算是否能给我们在分布式计算层面提供 ...
- Apache Beam—透视Google统一流式计算的野心
Google是最早实践大数据的公司,目前大数据繁荣的生态很大一部分都要归功于Google最早的几篇论文,这几篇论文早就了以Hadoop为开端的整个开源大数据生态,但是很可惜的是Google内部的这些系 ...
- kafka 流式计算
http://www.infoq.com/cn/articles/kafka-analysis-part-7/ Kafka设计解析(七)- 流式计算的新贵 Kafka Stream
- Others-阿里专家强琦:流式计算的系统设计和实现
阿里专家强琦:流式计算的系统设计和实现 更多深度文章,请关注云计算频道:https://yq.aliyun.com/cloud 阿里云数据事业部强琦为大家带来题为“流式计算的系统设计与实现”的演讲,本 ...
- 大数据入门第十六天——流式计算之storm详解(一)入门与集群安装
一.概述 今天起就正式进入了流式计算.这里先解释一下流式计算的概念 离线计算 离线计算:批量获取数据.批量传输数据.周期性批量计算数据.数据展示 代表技术:Sqoop批量导入数据.HDFS批量存储数据 ...
- 【流处理】Kafka Stream-Spark Streaming-Storm流式计算框架比较选型
Kafka Stream-Spark Streaming-Storm流式计算框架比较选型 elasticsearch-head Elasticsearch-sql client NLPchina/el ...
随机推荐
- .Net Core3.1下使用Swagger搭建web api项目
前言:微软于前天发布.net core 3.1正式版,并将长期支持3.1.所以我听到这个消息后就急忙下载.net core 3.1的SDK和Runtime,应该是公司最先用3.1的攻城狮了
- Good Bye 2017 A B C
Good Bye 2017 A New Year and Counting Cards 题目链接: http://codeforces.com/contest/908/problem/A 思路: 如果 ...
- windows下RocketMQ下载安装教程
一.下载(原文链接:http://www.studyshare.cn/software/details/1183/0 ) 1.官网下载:下载地址 2.百度网盘下载:下载地址 提取码:0g5a ja ...
- doget,dopst,service方法的区别
先看servlet: package com.szxy.test; import java.io.IOException; import javax.servlet.ServletException; ...
- C.Dominated Subarray
题目:受主导的子序列 题意:序列t至少有2个元素,我们称序列t被数字出现次数最多的元素v主导,且出现次数最多的元素必须是唯一的 你被给予了序列a1, a2, ..., an,计算它的最短受主导子序列, ...
- OSC2019关于开源的见闻-开源让世界更美好 社会更文明
一.开源生态报告-红薯-开源中国创始人 1.协作乏力-大厂同样 2.协议许可证使用不当 新许可证-木兰 3.开发者对法律认识完全不够 著作权意识不够 红线意识不够 相关法律法规的熟悉不够 维权及其弱势 ...
- 每个pool pg数计算
ceph PGs per Pool Calculator 原文档:http://xiaqunfeng.cc/2017/09/18/ceph-PGs-per-Pool-Calculator/ 2017- ...
- 《吊打面试官》系列-ConcurrentHashMap & HashTable
你知道的越多,你不知道的越多 点赞再看,养成习惯 本文 GitHub https://github.com/JavaFamily 已收录,有一线大厂面试点思维导图,也整理了很多我的文档,欢迎Star和 ...
- idea 几个常用的设置
一.主题的背景
- 我在知识星球上创建了免费的Web3D学习的星球~
大家好,我是YYC. 我在知识星球创建了一个免费的星球-"YYC的Web 3D旅程",欢迎大家加入- 本星球完全免费,致力于打造专业的Web 3D技术学习区,分享各种3D技术和信息 ...