【目标检测实战】目标检测实战之一--手把手教你LMDB格式数据集制作!
文章目录
1 目标检测简介
2 lmdb数据制作
2.1 VOC数据制作
2.2 lmdb文件生成
lmdb格式的数据是在使用caffe进行目标检测或分类时,使用的一种数据格式。这里我主要以目标检测为例讲解lmdb格式数据的制作。
1 目标检测简介
【1】目标检测主要有两个任务:
- 判断图像中对象的类别
- 类别的位置
【2】目标检测需要的数据:
- 训练所需的图像数据,可以是jpg、png等图片格式
- 图像数据对应的类别信息和类别框的位置信息。
2 lmdb数据制作
caffe一般使用lmdb格式的数据,在制作数据之前,我们需要对数据进行标注,可以使用labelImg对图像进行标注(https://github.com/tzutalin/labelImg),这里就不多赘述数据标注的问题。总之,我们得到了图像的标注Annotations数据。lmdb数据制作,首先需要将annotations数据和图像数据制作为VOC格式,然后将其生成LMDB文件即可。下边是详细的步骤:
2.1 VOC数据制作
这里我以caffe环境的Mobilenet+YOLOv3模型的代码为例(https://github.com/eric612/MobileNet-YOLO),进行lmdb数据制作,并且也假设你已经对其配置编译成功(如没成功,可以参考博文进行配置),所以我们的根目录为:caffe-Mobilenet-YOLO-master,下边为详细步骤:
【1】VOC格式目录建立:
VOC格式目录主要包含为:

其中,Annotations里存储的是xml标注信息,JPEGImages存储的是图片,ImageSets则是训练和测试的txt列表等信息,下边我们就要安装如上的目录进行建立我们自己的数据目录。
创建Annotations、JPEGImages、ImageSets/Main等文件,命令如下(也可直接界面操作哈):
注:建议新手按照我的名称,对于后续文件修改容易!!!
cd ~/ # 进入home目录
cd Documents/ # 进入Documents目录
cd caffe-Mobilenet-YOLO-master/ # 进入我们的根目录
cd data # 进入data目录内
mkdir VOCdevkit # 创建存储我们自己的数据的文件夹
cd VOCdevkit
mkdir MyDataSet # 创建存储voc的目录
cd MyDataSet
# 创建VOC格式目录
mkdir Annotations
mkdir JPEGImages
mkdir ImageSets
cd ImageSets
mkdir Main
好啦,我们的文件夹就建立好了,如下图所示:
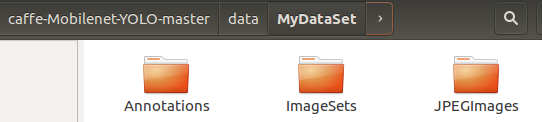
【2】将所有xml文件考入至Annotations文件夹内
【3】将所有图片考入至JPEGImages文件夹内
【4】划分训练接、验证集合测试集,如下为Python代码,需要修改的地方注释已标明:
import os
import random
# 标注文件的路径,需要你自己修改
xmlfilepath=r'/home/Documents/caffe-Mobilenet-YOLO-master/data/VOCdevkit/MyDataSet/Annotations/'
# 这里是存储数据的本目录,需要改为你自己的目录
saveBasePath=r"/home/Documents/caffe-Mobilenet-YOLO-master/data/VOCdevkit/"
trainval_percent=0.8 # 表示训练集和验证集所占比例,你需要自己修改,也可选择不修改
train_percent=0.8 # 表示训练集所占训练集验证集的比例,你需要自己修改,也可选择不修改
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'MyDataSet/ImageSets/Main/trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'MyDataSet/ImageSets/Main/test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'MyDataSet/ImageSets/Main/train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'MyDataSet/ImageSets/Main/val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
上述代码修改之后,在根目录caffe-Mobilenet-YOLO-master执行上述代码即可,
在data/VOCdevkit/MyDataSet/ImageSets下生成trainval.txt、test.txt、train.txt、val.txt等所需的txt文件,如下图所示:
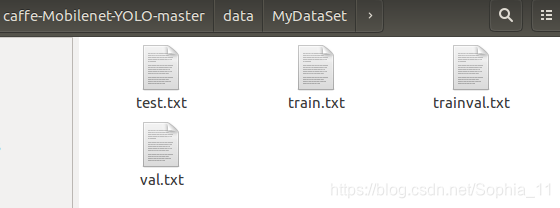
这些TXT文件会包含图片的名字,不带路径,如下图所示:

2.2 lmdb文件生成
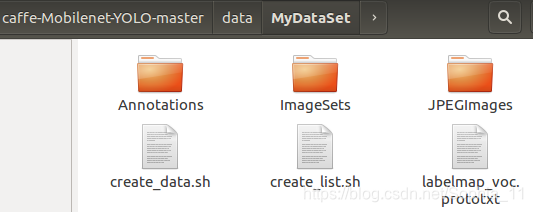
【1】执行如下命令,将生成lmdb所需的脚本复制至data/VOCdevkit/MyDataSet文件夹内:
cp data/VOC0712/create_* data/MyDataSet/ # 把create_list.sh和create_data.sh复制到MyDataSet目录
cp data/VOC0712/labelmap_voc.prototxt data/MyDataSet/ # 把labelmap_voc.prototxt复制到MyDataSet目录
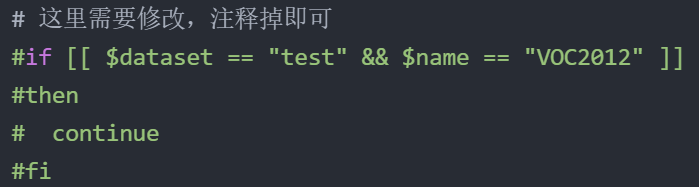
【2】修改create_list.sh文件:
1 第3行修改目录路径,截止到VOCdevkit即可

2 第13行修改为for name in MyDataSet(VOCdevkit下自己建立的文件夹名字)

3 第15-18行注释掉
4 第41行get_image_size修改为自己的路径(注意,这里是build caffe_mobilenet_yolo之后才会形成的):

#!/bin/bash
# 如果严格安装我上述的步骤,就可以不用修改路径位置。
# 需要修改的位置也使用注释进行了标注和解释
# 这里需要更改,你数据的根目录位置,需要修改的地方!!!!
root_dir="/home/Documents/Caffe_Mobilenet_YOLO/data/VOCdevkit/"
sub_dir=ImageSets/Main
bash_dir="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
for dataset in trainval test
do
dst_file=$bash_dir/$dataset.txt
if [ -f $dst_file ]
then
rm -f $dst_file
fi
for name in MyDataSet # 如果你建立的不是MyDataSet,这里需要修改为你自己的名字
do
# 这里需要修改,注释掉即可
#if [[ $dataset == "test" && $name == "VOC2012" ]]
#then
# continue
#fi
echo "Create list for $name $dataset..."
dataset_file=$root_dir/$name/$sub_dir/$dataset.txt
img_file=$bash_dir/$dataset"_img.txt"
cp $dataset_file $img_file
sed -i "s/^/$name\/JPEGImages\//g" $img_file
sed -i "s/$/.jpg/g" $img_file
label_file=$bash_dir/$dataset"_label.txt"
cp $dataset_file $label_file
sed -i "s/^/$name\/Annotations\//g" $label_file
sed -i "s/$/.xml/g" $label_file
paste -d' ' $img_file $label_file >> $dst_file
rm -f $label_file
rm -f $img_file
done
# Generate image name and size infomation.
if [ $dataset == "test" ]
then
home/Documents/Caffe_Mobilenet_YOLO/caffe-MobileNet-YOLO-master/build/tools/get_image_size $root_dir $dst_file $bash_dir/$dataset"_name_size.txt"
【3】creat_data.sh修改:
1 第2行修改为自己的路径:root_dir="/home/Documents/caffe-MobileNet-YOLO-master/"

2 第7行修改为:data_root_dir="/home/Documents/caffe-MobileNet-YOLO-master/data/VOVdevkit/

3 第8行修改为:dataset_name="MyDataSet"

4 第9行修改为:mapfile="\(root_dir/data/VOCdevkit/\)dataset_name/labelmap_voc.prototxt"

5 第26行修改为\(root_dir/data/VOCdevkit/\)dataset_name/$subset.txt

cur_dir=$(cd $( dirname ${BASH_SOURCE[0]} ) && pwd )
# 修改为自己的路径
root_dir="/home/Documents/Caffe_Mobilenet_YOLO/caffe-MobileNet-YOLO-master/"
cd $root_dir
redo=1
# 这里需要修改为自己的路径
data_root_dir="/home/Documents/Caffe_Mobilenet_YOLO/caffe-MobileNet-YOLO-master/data/VOCdevkit/"
dataset_name="MyDataSet" # 修改为自己的名字
mapfile="$root_dir/data/VOCdevkit/$dataset_name/labelmap_voc.prototxt" # 修改为自己的路径
anno_type="detection"
db="lmdb"
min_dim=0
max_dim=0
width=0
height=0
extra_cmd="--encode-type=jpg --encoded"
if [ $redo ]
then
extra_cmd="$extra_cmd --redo"
fi
for subset in test trainval
# subset.txt路径需要修改
do
python $root_dir/scripts/create_annoset.py --anno-type=$anno_type \
--label-map-file=$mapfile --min-dim=$min_dim --max-dim=$max_dim --resize-width=$width \
--resize-height=$height --check-label $extra_cmd $data_root_dir $root_dir/data/VOCdevkit/$dataset_name/$subset.txt \
$data_root_dir/$dataset_name/$db/$dataset_name"_"$subset"_"$db examples/$dataset_name
【3】修改labelmap_voc.prototxt文件:
除了第一个背景标签部分不要修改,其他改成自己的标签就行,多的删掉,少了添加进入就行
【4】最后在caffe-MobileNet-YOLO-master/examples文件夹内新建一个MyDataSet文件夹(空的)
【5】运行create_list.sh脚本: ./data/VOCdevkit/MyDataSet/create_list.sh,运行完后,会在自己建的VOCdevkit/MyDataSet/目录内生成trainval.txt, test.txt, test_name_size.txt。
【6】运行create_data.sh脚本: ./data/VOCdevkit/MyDataSet/create_data.sh
运行此命令时,提示:bash:./data/VOCdevkit/MyDataSet/create_list.sh:Permission denied,没有权限,需要执行如下命令赋予执行命令:
chmod u+x data/VOCdevkit/MyDataSet/create_data.sh
出现了错误:ValueError: need more than 2 values to unpack,

需要将create_annoset.py中第88行的seg去掉,因为我们的Annotations只有两个值,img_file和anno。
运行完后,会在会在自己建的VOCdevkit/MyDataSet目录内生成lmdb文件夹:

lmdb对应训练集和测试集的lmdb格式的文件夹:
 ***
***
好啦,今天的教程就到这里,如有疑问,可关注公众号【计算机视觉联盟】私信我或留言交流!!
【目标检测实战】目标检测实战之一--手把手教你LMDB格式数据集制作!的更多相关文章
- TF项目实战(基于SSD目标检测)——人脸检测1
SSD实战——人脸检测 Tensorflow 一 .人脸检测的困难: 1. 姿态问题 2.不同种族人, 3.光照 遮挡 带眼睛 4.视角不同 5. 不同尺度 二. 数据集介绍以及转化VOC: 1. F ...
- Java Web项目漏洞:检测到目标URL存在http host头攻击漏洞解决办法
检测到目标URL存在http host头攻击漏洞 详细描述 为了方便的获得网站域名,开发人员一般依赖于HTTP Host header.例如,在php里用_SERVER["HTTP_HOST ...
- 检测到目标URL存在http host头攻击漏洞
检测到目标URL存在http host头攻击漏洞 1.引发安全问题的原因 为了方便的获得网站域名,开发人员一般依赖于HTTP Host header.例如,在php里用_SERVER["HT ...
- 【图像处理】Haar Adaboost 检测自定义目标(视频车辆检测算法代码)
阅读须知 本博客涉及到的资源: 正样本:http://download.csdn.net/detail/zhuangxiaobin/7326197 负样本:http://download.csdn.n ...
- 目标检测之人头检测(HaarLike Adaboost)---高密度环境下行人检测和统计
实验程序视频 下载 1 问题描述 高密度环境下的行人统计一直没有得到很好的解决,主要原因是对高密度人群中的行人检测和跟踪是一个很难的问题,如下图所示环境,存在的困难包括: 检测方面: 由于人群整体处于 ...
- 目标检测之行人检测(Pedestrian Detection)基于hog(梯度方向直方图)--- 梯度直方图特征行人检测、人流检测2
本文主要介绍下opencv中怎样使用hog算法,因为在opencv中已经集成了hog这个类.其实使用起来是很简单的,从后面的代码就可以看出来.本文参考的资料为opencv自带的sample. 关于op ...
- 语义分割(semantic segmentation) 常用神经网络介绍对比-FCN SegNet U-net DeconvNet,语义分割,简单来说就是给定一张图片,对图片中的每一个像素点进行分类;目标检测只有两类,目标和非目标,就是在一张图片中找到并用box标注出所有的目标.
from:https://blog.csdn.net/u012931582/article/details/70314859 2017年04月21日 14:54:10 阅读数:4369 前言 在这里, ...
- faster-rcnn 目标检测 数据集制作
本文的目标是制作目标检测的数据集 使用的工具是 python + opencv 实现目标 1.批量图片重命名,手动框选图片中的目标,将目标框按照一定格式保存到txt中 图片名格式(批量) .jpg . ...
- 目标检测之单步检测(Single Shot detectors)
目标检测之单步检测(Single Shot detectors) 前言 像RCNN,fast RCNN,faster RCNN,这类检测方法都需要先通过一些方法得到候选区域,然后对这些候选区使用高质量 ...
随机推荐
- Arduino学习笔记⑥ 硬件串口通信
1.前言 Ardunio与计算机通信最常用的方式就是串口通信.在Arduino控制器上,串口都是位于Rx和Tx两个引脚,Arduino的USB口通过一个转换芯片与这两个串口引脚连接.该转换芯片 ...
- 自定义表头Datagrid
自定义的一个表头 <bp:BasePage x:Class="NetReform.Pages.RealProbabiTableCompare" xmlns="htt ...
- Java 异常(二) 自定义异常
上篇文章介绍了java中异常机制,本文来演示一下自定义异常 上篇文章讲到非运行时异常和运行时异常,下面我们来看一下简单实现代码. 首先,先来看下演示目录 非运行时异常 也称 检查时异常 public ...
- 树莓派上搭建arduino命令行开发环境
-------------还是博客园上面的格式看这舒服,不去新浪了------------- 为什么要在树莓派上开发arduino呢?总要把树莓派用起来嘛,不然老吃灰. 树莓派使用SSH时没有图形界面 ...
- kmp算法,求重复字符串
public class Demo { public static void main(String[] args) { String s1 = "ADBCFHABESCACDABCDABC ...
- HTTP 结构详解
转至 :https://blog.csdn.net/u010256388/article/details/68491509?utm_source=copy 引用 学习Web开发不好好学习HTTP报 ...
- django-模板之block(四)
base.html <!DOCTYPE html> <html lang="en"> <head> <meta charset=" ...
- GO基础之List
一.List定义 概述1.list是一种非连续存储的容器,由多个节点组成,节点通过一些变量记录彼此之间的关系.list有多种实现方法,如单向链表.双向链表等.2.Go语言中list的实现原理是双向链表 ...
- 盘点飞思卡尔i.MX多媒体处理器前世今生 (转)
现如今,移动处理器领域,大家关注最多的是德州仪器.高通.展讯.MTK,甚至包括Intel,但是请别忘记飞思卡尔,他的i.MX处理器已经发展到第六代. 那么我们今天就来盘点下i.MX的前世今生吧. i. ...
- 卷积神经网络详细讲解 及 Tensorflow实现
[附上个人git完整代码地址:https://github.com/Liuyubao/Tensorflow-CNN] [如有疑问,更进一步交流请留言或联系微信:523331232] Reference ...