kafka详解(一)--kafka是什么及怎么用
kafka是什么
在回答这个问题之前,我们需要先了解另一个东西--event streaming。
什么是event streaming
我觉得,event streaming 是一个动态的概念,它描述了一个个 event ( "something happened" in the world ) 在不同主体间连续地、正确地流动的状态。(这里我想搞个动图的,不过 plantuml 不支持,所以只能靠想象了。。)
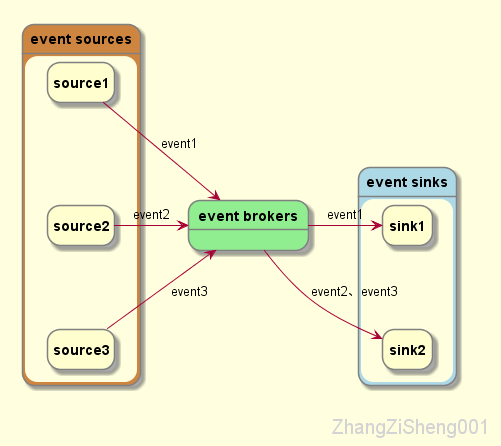
event source 产生 event,event source 可以是数据库、传感器、移动设备、应用程序,等等。
event broker 持久化 event,以备 event sink 可以随时获取它们。
event sink 实时或回顾性地从 broker 中获取 event 进行处理。
有的人可能会问,为什么需要 broker,event 从 source 直接流到 sink 不行吗?当然可以,但是不够解耦,要么 event source 需要事先知道谁需要这些 event,要么 event sink 需要知道 event 从哪里来。
现在,我们可以在脑子里想象出 event streaming 的样子:event 由 source 产生,然后流向 broker,在 broker 被持久化,再流到 sink。并不复杂对吧?
event streaming用来干嘛
我们可以在很多的应用场景中找到 event streaming 的身影,例如:
实时处理支付、金融交易、客户订单等等;
实时跟踪和监控物流进度;
持续捕获和分析来自物联网设备或其他设备的传感器数据;
不同数据源的数据连接;
作为数据平台、事件驱动架构和微服务等的技术基础;
等等。
kafka是什么
现在我们回过头来回答问题:kafka 是什么?
我认为,如果说 event streaming 是一种规范的话,那么 kafka 就是 event streaming 的一种具体实现。
kafka的架构
概念视图
从最上层的抽象看,kafka 由三个部分组成:
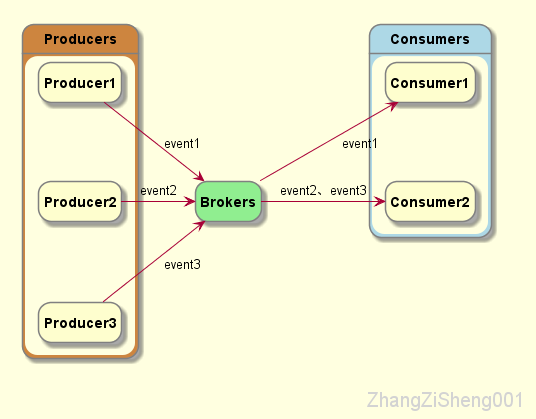
其中,producer 发布 event,broker 持久化 even,consumer 订阅 event。其中,producer 和 consumer 完全解耦,互不知晓。
不过,这是概念视图,不是物理视图。具体实现会因为 source 或 sink 的不同而有所不同。
物理视图
Producer/Consumer API
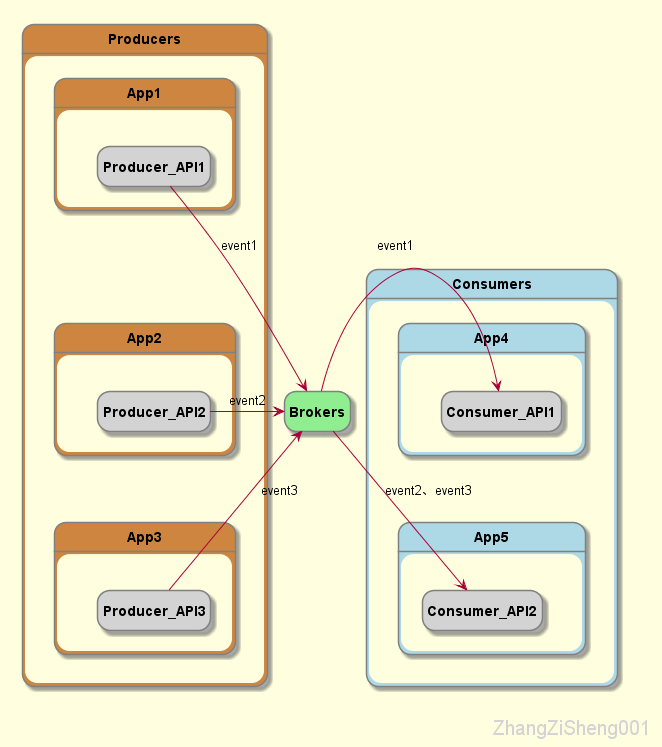
当 event source 为普通应用程序时,可以在程序中引入 Producer API 和 Consumer API 来完成与 broker 的交互。这些 API 涵盖了大部分主流语言,例如 Java、Scala、Go、Python、C/C++,除此之外,我们也可以直接使用 REST API 调用。
Connector
但是,并不是所有 source 或 sink 都能使用 API 的方式,例如,实时捕获数据库的更改、文件的更改,从 RabbitMQ 导入导出消息,等等。
这个时候就需要使用 connector 来完成集成。通常情况下,connector 并不需要我们自己开发,kafka 社区为我们提供了大量的 connector 来满足我们的使用需求。
topic&partition
接下来我们再来补充下 broker 的一些细节。//zzs001
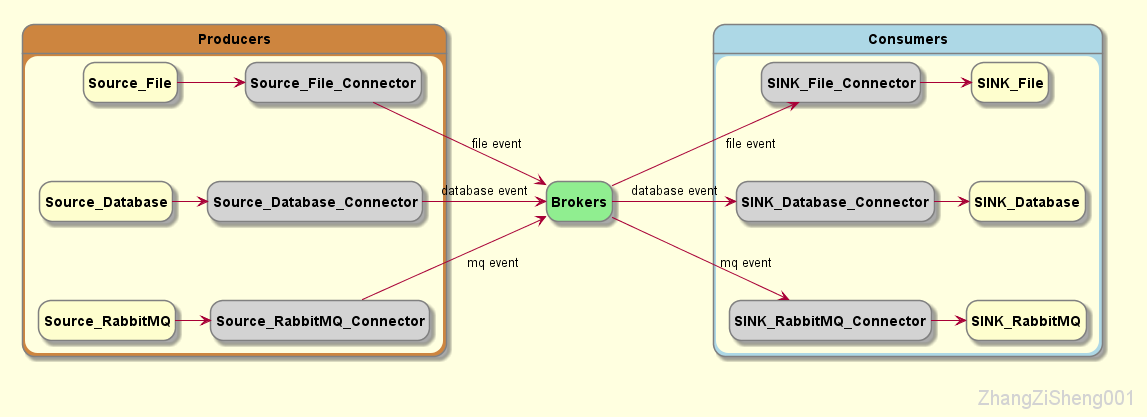
通常情况下,我们的 broker 会接收到很多不同类型的 event ,broker 需要区分它们,以便正确地路由。topic 就发挥了作用,它有点类似文件系统的目录,而 event 就类似于目录里的文件,sink 想要什么 event,只要找到对应的 topic 就行了。
同一 topic 可以有零个或多个 producer 和 consumer,不同于传统 MQ,kafka 的 event 消费后并不删除,为什么这么做呢?这个我们后续的博客会说的。
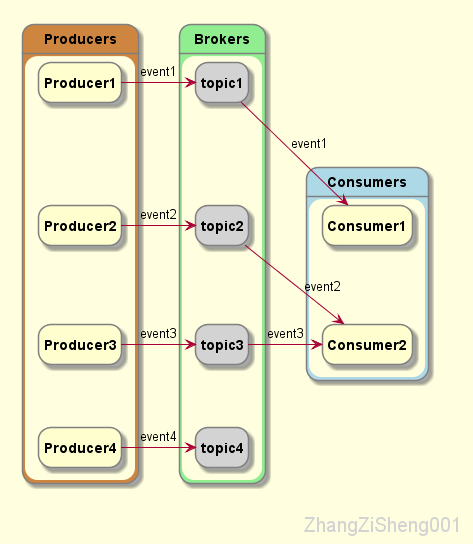
除此之外,一个 topic 会划分成一个或多个 partition,这些 partition 一般分布在不同的 broker 实例。producer 发布的 event 会根据某种策略分配到不同的 partition,这样做的好处是,consumer 可以同时从多台 broker 读取 event,从而大大提高吞吐量。另外,为了高可用,同一个 partition 还会有多个副本,它们分布在不同的 broker 实例。
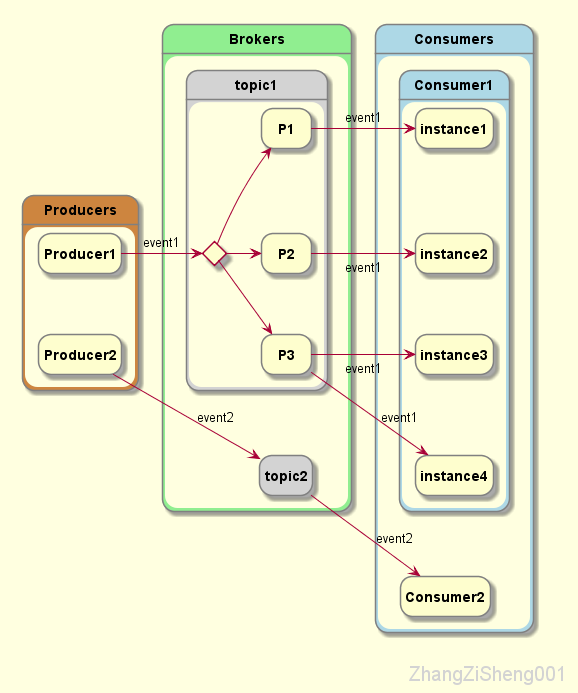
需要注意一下,当同一 topic 的 event 被分发到多个 partition 时,写入和读取的顺序就不能保证了,对于需要严格控制顺序的 topic,partition 需要设置为 1。
Streams
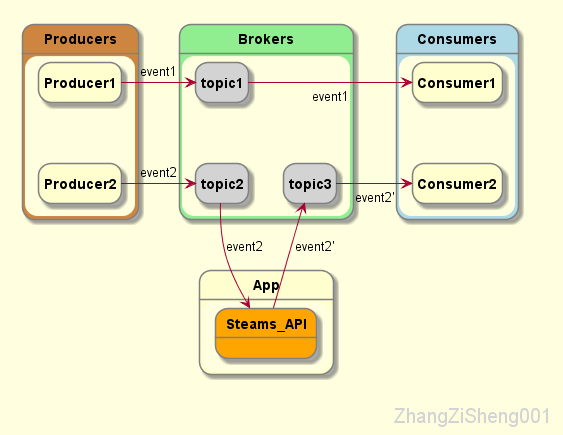
kafka 那么受欢迎,还有一个很重要的原因,就是它提供了流式处理类库,支持对存储于Kafka内的数据进行流式处理和分析。这部分内容,我也是刚入门而已,后续博客再好好研究。
如何使用kafka
环境说明
kafka:3.2.1
os:CentOS Linux release 8.3.2011
JDK:1.8.0_291
注意,kafka 3.2.1 要求本地环境安装 Java 8 及以上版本
下载安装
从 下载页面下载安装包。
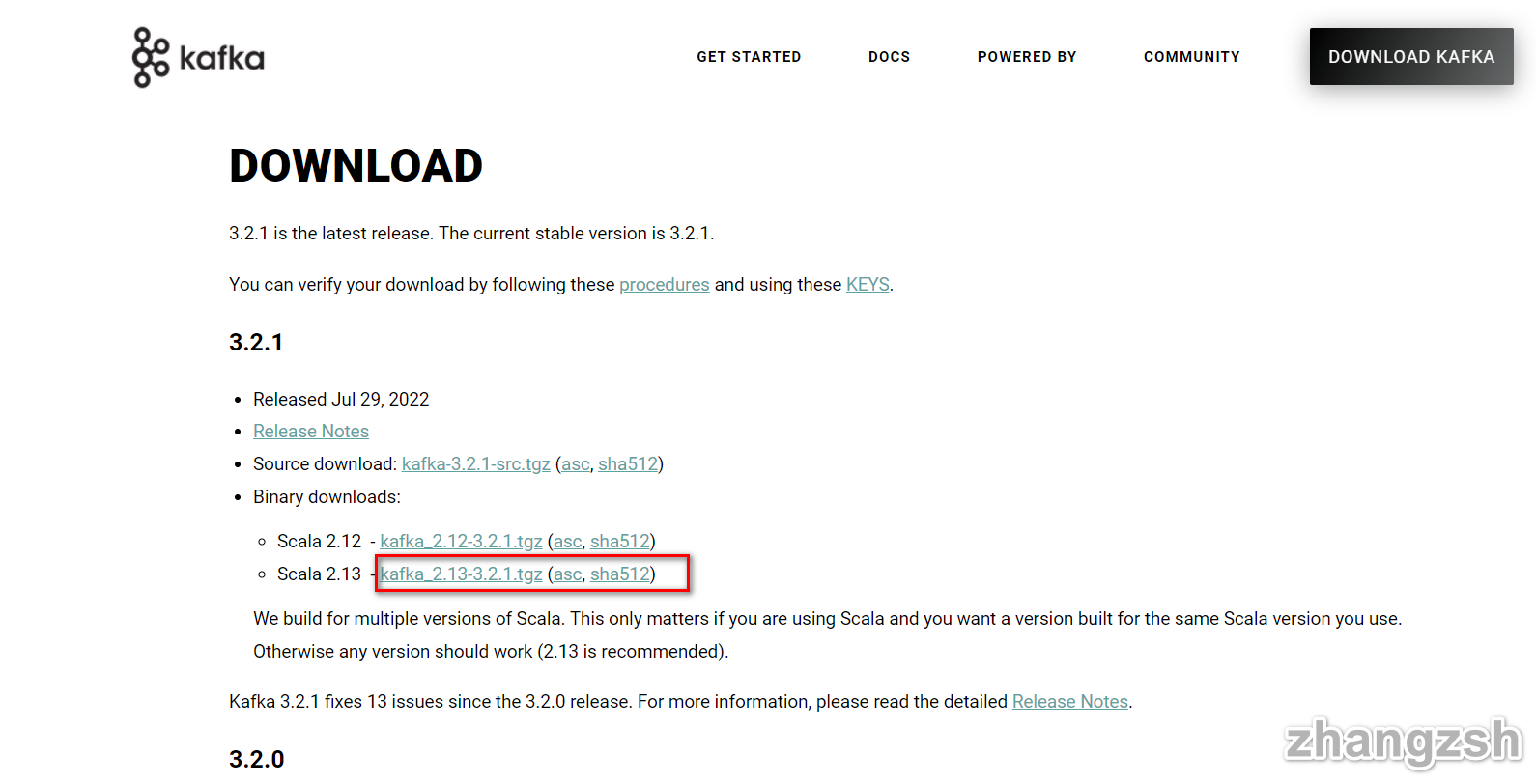
解压安装包。
tar -xzf kafka_2.13-3.2.1.tgz
启动broker
进入到解压目录,我们看看 kafka 的目录结构。
cd kafka_2.13-3.2.1
ls -al
接下来,我们启动 broker 的部分,需要按照顺序依次启动 zookeeper 和 kafka server。
先启动 zookeeper(后续版本可能不再需要 zookeeper)。
bin/zookeeper-server-start.sh config/zookeeper.properties
打开另一个会话,再启动 kafka server。
bin/kafka-server-start.sh config/server.properties
现在,单机版 broker 已经就绪,我们可以开始使用了。
创建topic
producer 发布的 event 会持久化在对应的 topic 中,才能路由给正确的 consumer。所以,在读写 event 之前,我们需要先创建 topic。
打开另一个会话,执行以下命令。
# 创建topic zzs001
bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092
# 查询topic
bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092

简单的读写event
接下来我们用 kafka 自带的 console-consumer 和 console-producer 读写 event。
使用 console-producer 写 event 时,我们每输入一行并回车,就会向 topic 写入一个 event。
bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092

写完之后我们可以按 Ctrl + C 退出。
接着,我们使用 console-consumer 读 event。可以看到,刚写的 event 被读到了。
bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092

读完我们按 Ctrl + C 退出。
我们可以在两个会话中保持 producer 和 consumer 不退出,当我们在 producer 写入 event 时, consumer 将实时读取到。
前面提到过,topic 的 event 会被持久化下来,而且被消费过的 event 并不会删除。这一点很容易验证,我们可以再开一个 consumer 来读取,它还是能读到被别人读过的 event。
使用connect导入导出
前面提到过,有的 source 或 sink 需要依赖 connector 来读写 event,接下来我们以文件为例,演示如何从已有文件中将 event 导入 topic,并从 topic 中导出到另一个文件中。
首先我们需要一个可以导入导出文件的 connector,默认情况下,在 kafka 的 libs 目录就有这样一个 jar 包--connect-file-3.2.1.jar。我们需要在 connect 的配置中引入这个包。
vi config/connect-standalone.properties
按 i 进入编辑,添加或修改plugin.path=libs/connect-file-3.2.1.jar。
按 ESC 后输入 :wq 保存并退出。除此之外,这个文件还可以用来配置需要连接哪个 broker,以及 event 的序列化方式等。

然后,我们创建一个 test.txt 作为 event source,并写入 event。
echo -e "foo\nbar" > test.txt

现在我们先启动 event source 的 connector,将 test.txt 的 event 写入名为 connect-test 的 topic。config/connect-file-source.properties 已经配置好了connector 名称、event source 的文件、topic,等等。
bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties
执行片刻后我们可以按 Ctrl + C 退出。
这时,我们可以先通过 consumer-console 查看 topic 上是否有这些 event。可以看到,event 已经成功导入,至于格式为什么是这样的,这个以后再说明。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning

现在我们启动 event sink 的 connector,将 topic 的 event 导入到 test.sink.txt。connect-file-sink.properties 已经配置好了connector 名称、event source 的文件、topic,等等 。
bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-sink.properties
执行片刻后我们可以按 Ctrl + C 退出。
这时查看 test.sink.txt,可以看到 event 成功导出。

和前面一样,这里我们也可以保持 event source 和 event sink 的 connector 不退出,测试实时生产和消费 event。
使用streams处理
这部分内容后续再补充。
停止
走到这一步,我们已经完成了 kafka 的入门学习。
接下来,我们可以通过以下步骤关闭 kafka。
如果 producer 或 consumer 还在运行,Ctrl + C 退出;
Ctrl + C 退出 kafka server;
Ctrl + C 退出 zookeeper;
如果想清除 kafka 的数据,包括我们创建的 topic 和 event、日志等,执行以下命令:
rm -rf /tmp/kafka-logs /tmp/zookeeper /tmp/connect.offsets
结语
以上内容是最近学习 kafka 的一些思考和总结(主要参考官方文档),如有错误,欢迎指正。
任何的事物,都可以被更简单、更连贯、更系统地了解。希望我的文章能够帮到你。
最后,感谢阅读。
参考资料
本文为原创文章,转载请附上原文出处链接:https://www.cnblogs.com/ZhangZiSheng001/p/16641755.html
kafka详解(一)--kafka是什么及怎么用的更多相关文章
- kafka详解(二)--kafka为什么快
前言 Kafka 有多快呢?我们可以使用 OpenMessaging Benchmark Framework 测试框架方便地对 RocketMQ.Pulsar.Kafka.RabbitMQ 等消息系统 ...
- Kafka 详解(二)------集群搭建
这里通过 VMware ,我们安装了三台虚拟机,用来搭建 kafka集群,虚拟机网络地址如下: hostname ipaddress ...
- [转]kafka详解
一.入门 1.简介 Kafka is a distributed,partitioned,replicated commit logservice.它提供了类似于JMS的特性,但是在设 ...
- kafka详解
一.基本概念 介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计. 这个独特的设计是什么样的呢? 首先让我们看几个基本的消息系统术语:Kafk ...
- (转)kafka 详解
kafka入门:简介.使用场景.设计原理.主要配置及集群搭建(转) 问题导读: 1.zookeeper在kafka的作用是什么? 2.kafka中几乎不允许对消息进行"随机读写"的 ...
- Kafka 详解(一)------简介
在前面几篇博客我们介绍过一种消息中间件——RabbitMQ,本篇博客我们介绍另外一个消息中间件——Kafka,Kafka是由LinkedIn开发的,使用Scala编写,是一种分布式,基于发布/订阅的消 ...
- 大数据入门第十七天——storm上游数据源 之kafka详解(二)常用命令
一.kafka常用命令 1.创建topic bin/kafka-topics. --replication-factor --zookeeper mini1: // 如果配置了PATH可以省略相关命令 ...
- Kafka详解五:Kafka Consumer的底层API- SimpleConsumer
问题导读 1.Kafka如何实现和Consumer之间的交互?2.使用SimpleConsumer有哪些弊端呢? 1.Kafka提供了两套API给Consumer The high-level Con ...
- Kafka详解四:Kafka的设计思想、理念
问题导读 1.Kafka的设计基本思想是什么?2.Kafka消息转运过程中是如何确保消息的可靠性的? 本节主要从整体角度介绍Kafka的设计思想,其中的每个理念都可以深入研究,以后我可能会发专题文章做 ...
随机推荐
- 用QT制作3D点云显示器——QtDataVisualization
因为QT的三维显示模块QtDataVisualization已经对个人开发免费开放了,所以在制作点云,地图,表格之类的东西的时候,其实我们都不需要使用QtCharts或者QOpenGL模块了.直接使用 ...
- BUUCTF-后门查杀
后门查杀 后门查杀这种题最好还是整个D盾直接扫描目录方便. 查看文件得到flag
- Python基础学习_03
程序的流程控制 1.程序的组织结构 (1)顺序结构 (2)选择结构 (3)循环结构 2.对象的布尔值 以下对象的布尔值为False False,数值0,None,空字符串,空列表,空元组,空字典,空集 ...
- Vue最新防抖方案
函数防抖(debounce):当持续触发事件时,一定时间段内没有再触发事件,事件处理函数才会执行一次,如果设定的时间到来之前,又一次触发了事件,就重新开始延时.举个栗子,持续触发scroll事件时,并 ...
- go int64传到前端导致溢出问题排查
简介 开周会的时候一位同事分享了一个踩坑经验,说在go里面还好好的int64类型,到前端就变得奇奇怪怪了,和原来不一样了.正好我对前端javascript有一点点了解,然后连夜写了点代码探索了一下 ...
- js 表面学习 - 认识结构2
单行注释以 // 开头. 多行注释以 /* 开头,以 */ 结尾. 任何位于 /* 和 */ 之间的文本都会被 JavaScript 忽略. JavaScript 数据类型 JavaScript 变量 ...
- C# / VB.NET 将Html转为Word
本文分享以C#程序代码为例,实现将Html文件转换Word文档的方法(附VB.NET代码).在实际转换场景中可参考本文的方法,转换前,请按照如下方法引用Word API的dll文件到Visual St ...
- DNS 系列(三):如何免受 DNS 欺骗的侵害
互联网上每一台设备都会有一个 IP 地址,我们在访问网站或发送信息时,其实都是通过 IP 地址达成准确请求的.但是这个 IP 地址由很长一串数字组成,记忆起来相当困难,所以我们创造了更实用的域名来代替 ...
- 如何用空气质量查询API接口进行快速开发
空气质量的好坏反映了空气污染程度,它是依据空气中污染物浓度的高低来判断的.空气污染是一个复杂的现象,在特定时间和地点空气污染物浓度受到许多因素影响.来自固定和流动污染物的人为污染物排放大小是影响空 ...
- Winsock Client Code
以下代码来自MSDN:https://msdn.microsoft.com/en-us/library/windows/desktop/ms737591(v=vs.85).aspx #define W ...