Kakao Brain 的开源 ViT、ALIGN 和 COYO 文字-图片数据集
最近 Kakao Brain 在 Hugging Face 发布了一个全新的开源图像文本数据集 COYO,包含 7 亿对图像和文本,并训练了两个新的视觉语言模型 ViT 和 ALIGN ViT 和 ALIGN。
这是 ALIGN 模型首次公开发布供开源使用,同时 ViT 和 ALIGN 模型的发布都附带有训练数据集。
Google 的 ViT 和 ALIGN 模型都使用了巨大的数据集 (ViT 训练于 3 亿张图像,ALIGN 训练于 18 亿个图像 - 文本对) 进行训练,因为数据集不公开导致无法复现。Kakao Brain 的 ViT 和 ALIGN 模型采用与 Google 原始模型相同的架构和超参数,不同的是其在开源 COYO 数据集上进行训练。对于想要拥有数据并复现视觉语言模型的研究人员有很大的价值。详细的 Kakao ViT 和 ALIGN 模型信息可以参照:
- COYO 数据集仓库地址: https://github.com/kakaobrain/coyo-dataset
- Kakao Brain 文档地址: https://hf.co/kakaobrain
这篇博客将介绍新的 COYO 数据集、Kakao Brain 的 ViT 和 ALIGN 模型,以及如何使用它们!以下是主要要点:
- 第一个开源的 ALIGN 模型!
- 第一个在开源数据集 COYO 上训练的开源 ViT 和 ALIGN 模型。
- Kakao Brain 的 ViT 和 ALIGN 模型表现与 Google 版本相当。
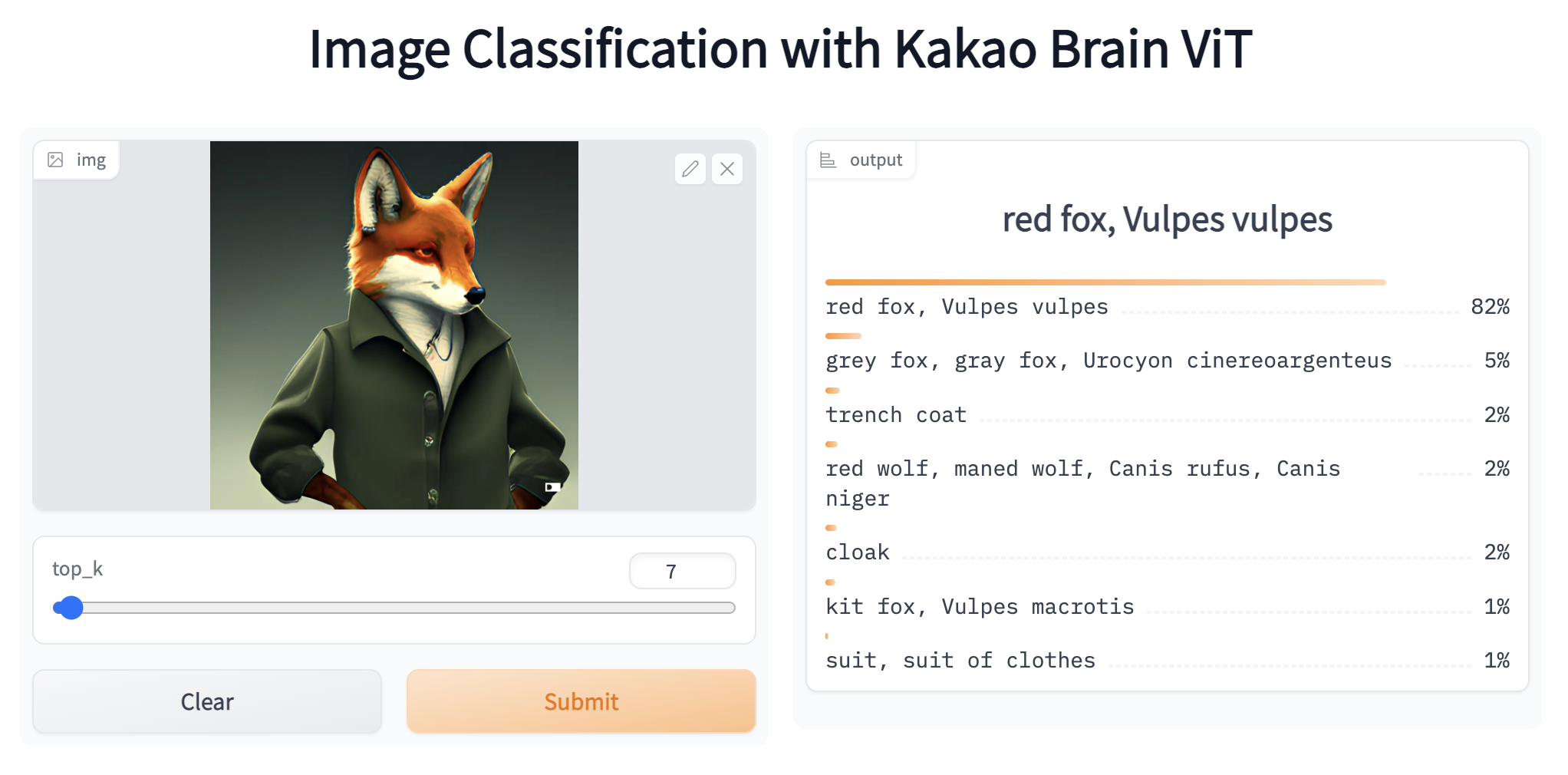
- ViT 模型在 HF 上可演示!您可以使用自己的图像样本在线体验 ViT!
性能比较
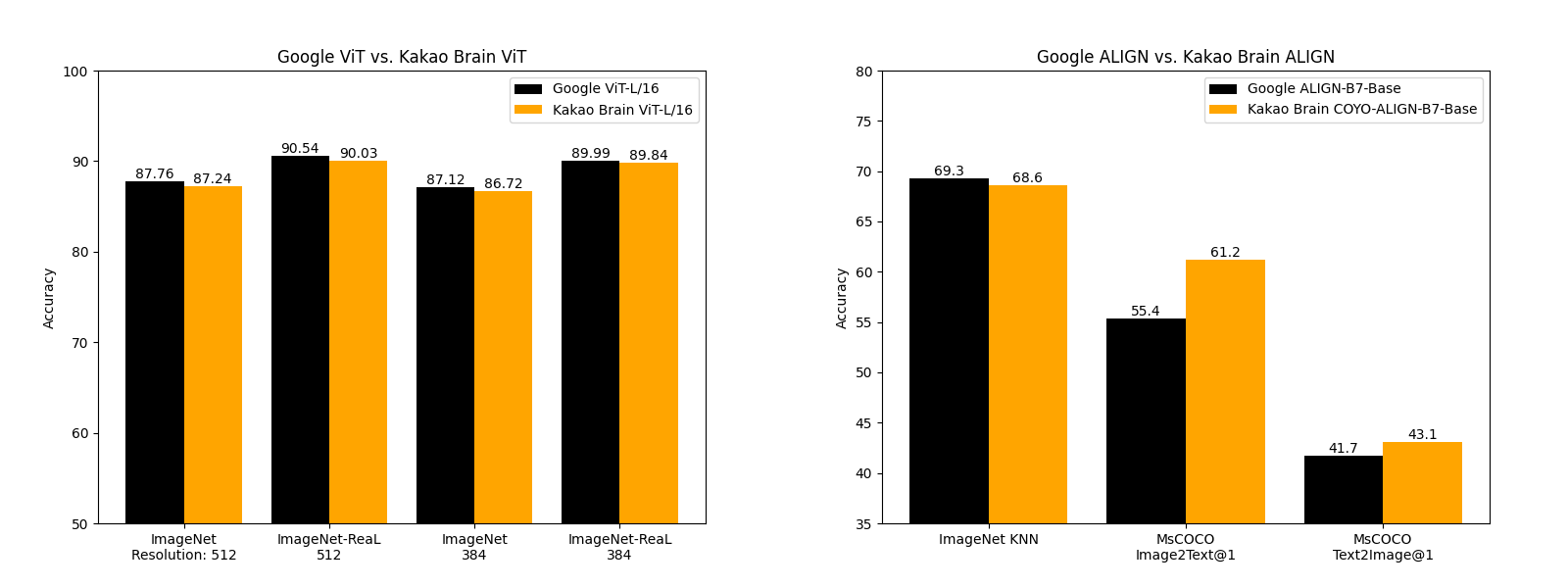
Kakao Brain 发布的 ViT 和 ALIGN 模型与 Google 的模型表现相当,某些方面甚至更好。Kakao Brain 的 ALIGN-B7-Base 模型虽然训练的数据对少得多 ( 7 亿 VS 1.8 亿),但在图像 KNN 分类任务上表现与 Google 的 ALIGN-B7-Base 相当,在 MS-COCO 图像 - 文本检索、文本 - 图像检索任务上表现更好。Kakao Brain 的 ViT-L/16 在 384×512 的 ImageNet 和 ImageNet-ReaL 数据上的表现与 Google 的 ViT-L/16 相当。这意味着同行可以使用 Kakao Brain 的 ViT 和 ALIGN 模型来复现 Google 的 ViT 和 ALIGN ,尤其是当用户需要训练数据时。所以我们很高兴开源这些与现有技术相当的模型!
COYO 数据集

本次发布的模型特别之处在于都是基于开源的 COYO 数据集训练的。COYO 数据集包含 7 亿图像 - 文本对,类似于 Google 的 ALIGN 1.8B图像 - 文本数据集,是从网页上收集的“嘈杂”的 html 文本 (alt-text) 和图像对。 COYO-700M 和 ALIGN 1.8B都是“嘈杂”的,只使用了适当的清洗处理。 COYO 类似于另一个开源的图像–文本数据集 LAION,但有一些区别。尽管 LAION 2B是一个更大的数据集,包含 20 亿个英语配对,但 COYO的附带有更多元数据,为用户提供更多灵活性和更细粒度的使用。以下表格显示了它们之间的区别: COYO所有数据对都提供了美感评分,更健壮的水印评分和面部计数信息 (face count data)。
| COYO | LAION 2B | ALIGN 1.8B |
|---|---|---|
| Image-text similarity score calculated with CLIP ViT-B/32 and ViT-L/14 models, they are provided as metadata but nothing is filtered out so as to avoid possible elimination bias | Image-text similarity score provided with CLIP (ViT-B/32) - only examples above threshold 0.28 | Minimal, Frequency based filtering |
| NSFW filtering on images and text | NSFW filtering on images | Google Cloud API |
| Face recognition (face count) data provided as meta-data | No face recognition data | NA |
| 700 million pairs all English | 2 billion English | 1.8 billion |
| From CC 2020 Oct - 2021 Aug | From CC 2014-2020 | NA |
| Aesthetic Score | Aesthetic Score Partial | NA |
| More robust Watermark score | Watermark Score | NA |
| Hugging Face Hub | Hugging Face Hub | Not made public |
| English | English | English? |
ViT 和 ALIGN 是如何工作的
这些模型是干什么的?让我们简要讨论一下 ViT 和 ALIGN 模型的工作原理。
ViT—Vision Transformer 是谷歌于 2020 年提出的一种视觉模型,类似于文本 Transformer 架构。这是一种与卷积神经网络不同的视觉方法 (AlexNet 自 2012 年以来一直主导视觉任务)。同样表现下,它的计算效率比 CNN 高达四倍,且具有域不可知性 (domain agnostic)。ViT 将输入的图像分解成一系列图像块 (patch),就像文本 Transformer 输入文本序列一样,然后为每个块提供位置嵌入以学习图像结构。ViT 的性能尤其在于具有出色的性能 - 计算权衡。谷歌的一些 ViT 模型是开源的,但其训练使用的 JFT-300 百万图像 - 标签对数据集尚未公开发布。Kakao Brain 的训练模型是基于公开发布的 COYO-Labeled-300M 进行训练,对应的 ViT 模型在各种任务上具有相似表现,其代码、模型和训练数据 (COYO-Labeled-300M) 完全公开,以便能够进行复现和科学研究。
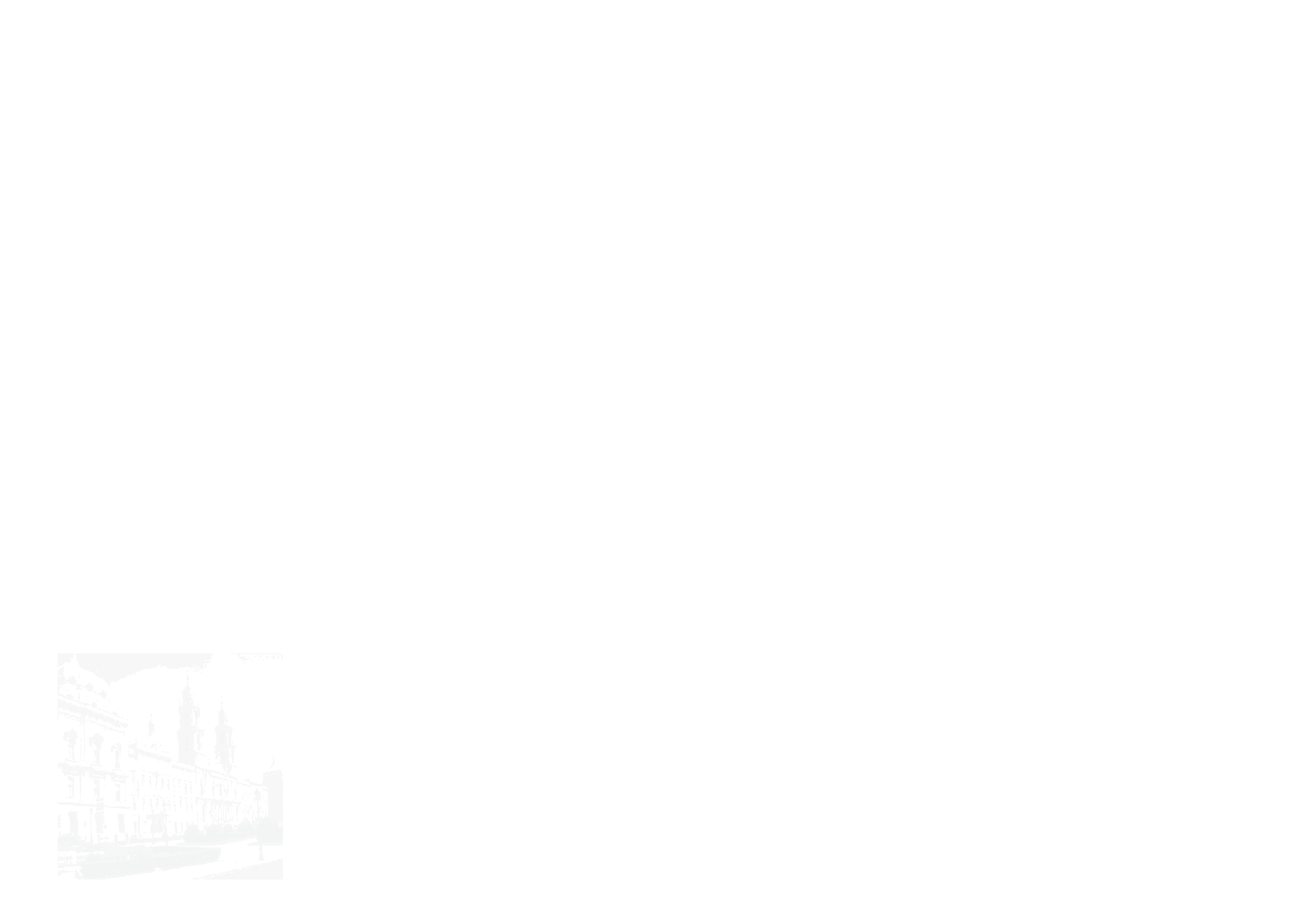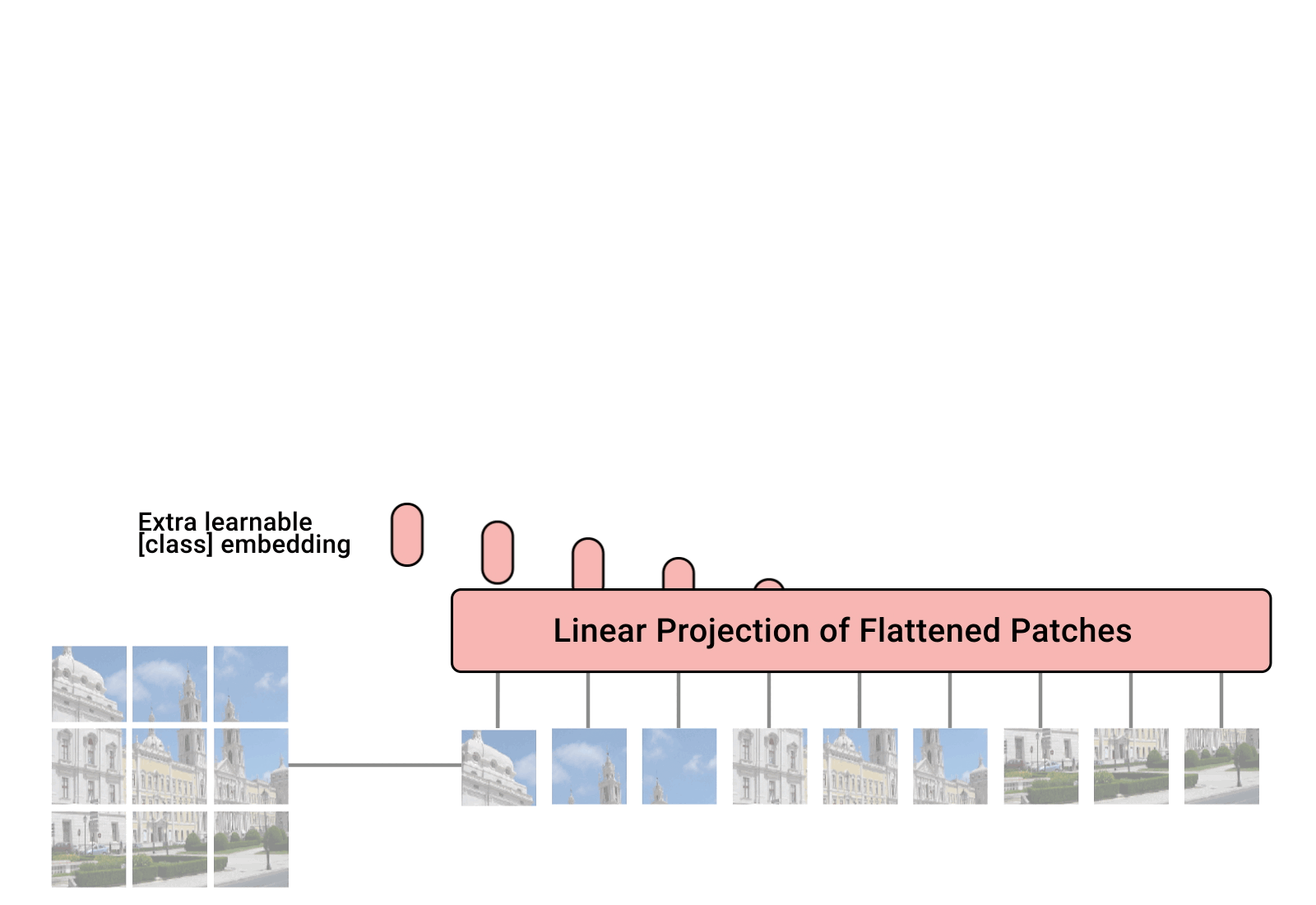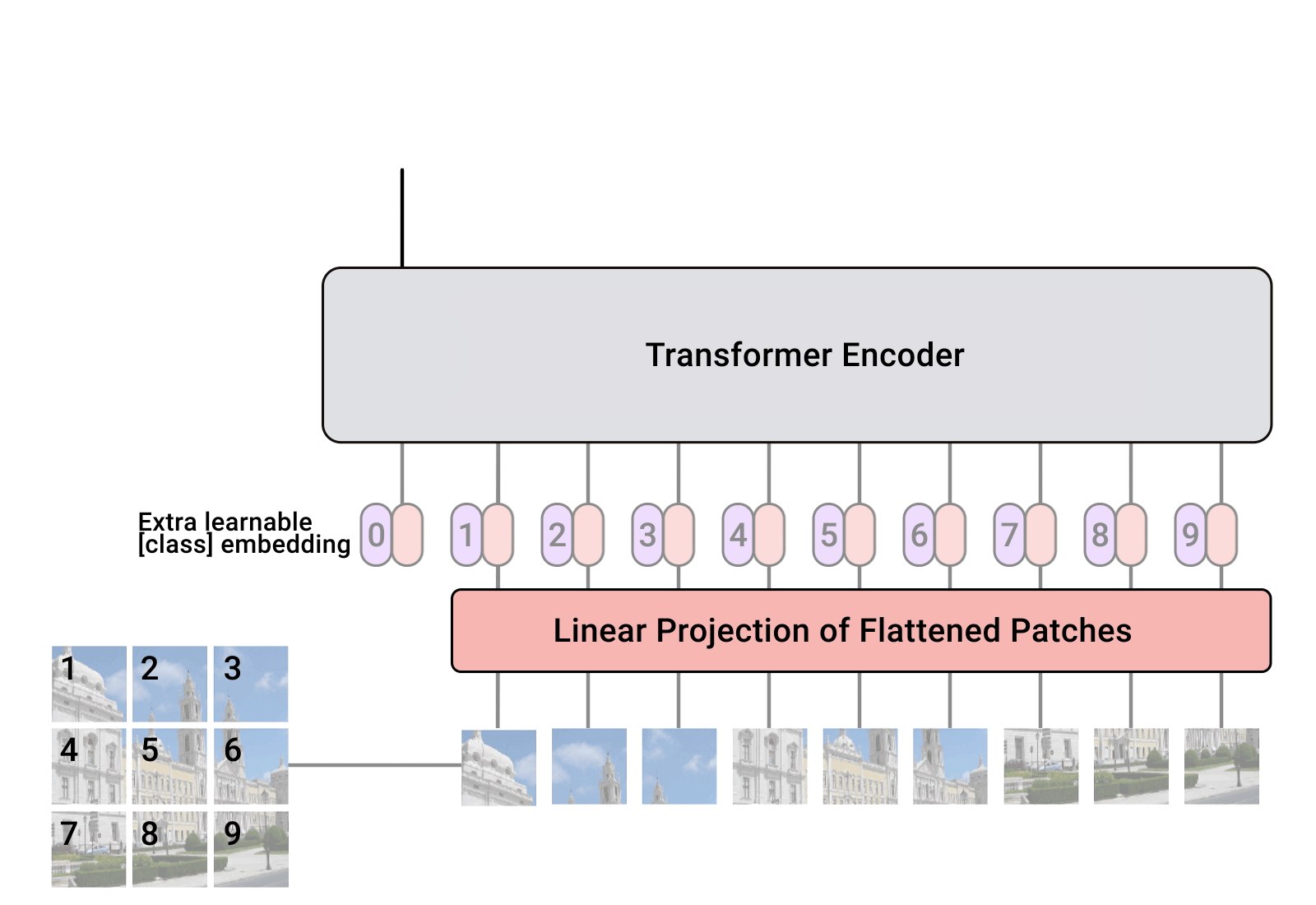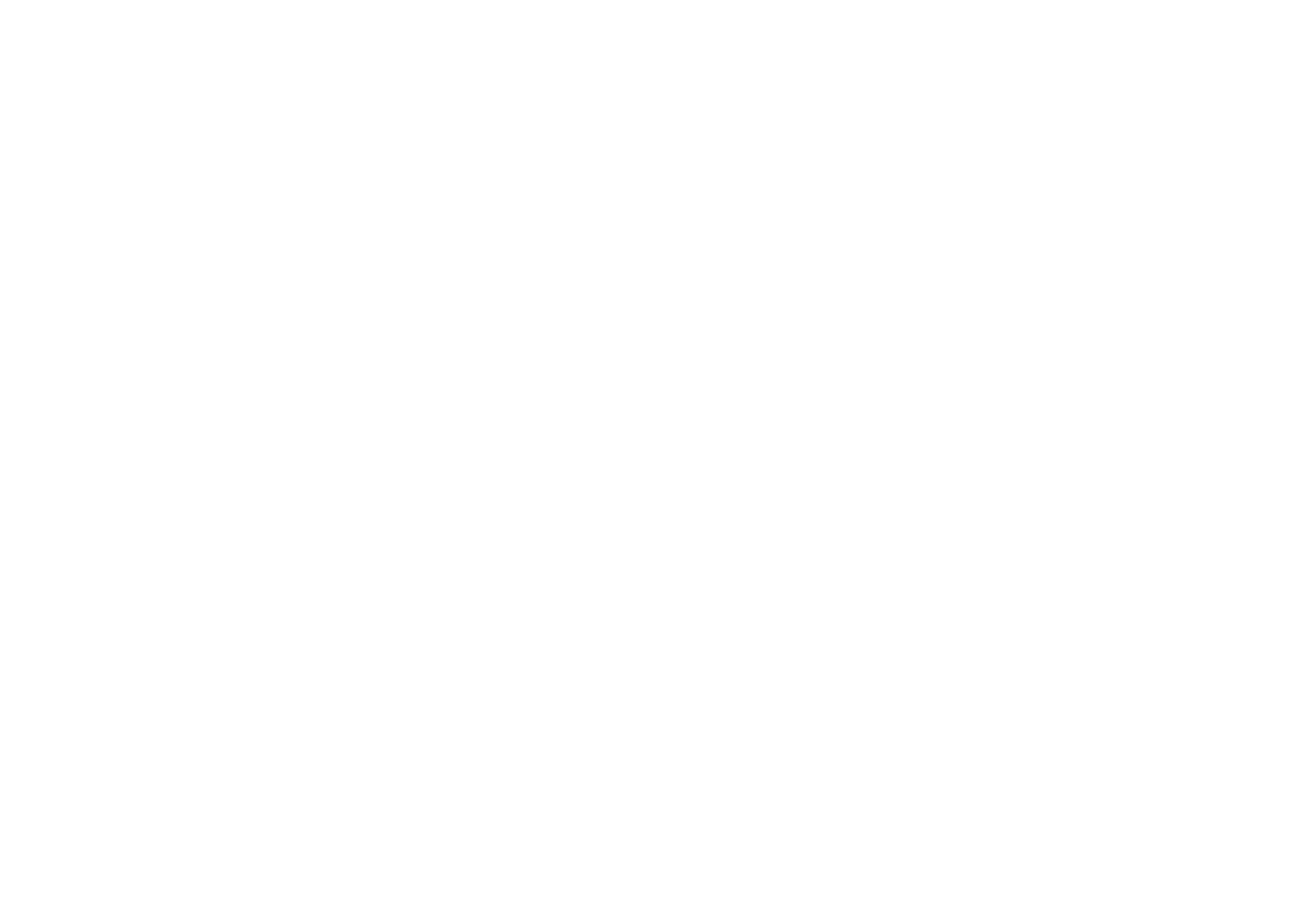
谷歌在 2021 年推出了 ALIGN,它是一种基于“嘈杂”文本–图像数据训练的视觉语言模型,可用于各种视觉和跨模态任务,如文本 - 图像检索。ALIGN 采用简单的双编码器架构,通过对比损失函数学习图像和文本对,ALIGN 的“嘈杂”训练语料特点包括用语料规模弥补其噪音以及强大的鲁棒性。之前的视觉语言表示学习都是在手动标注的大规模数据集上进行训练,这就需要大量的预先处理和成本。ALIGN 的语料库使用 HTML 文本 (alt-text) 数据作为图像的描述,导致数据集不可避免地嘈杂,但更大的数据量 (18 亿对) 使 ALIGN 能够在各种任务上表现出 SoTA 水平。Kakao Brain 的模型是第一个 ALIGN 开源版本,它在 COYO 数据集上训练,表现比谷歌的结果更好。

如何使用 COYO 数据集
我们可以使用 Hugging Face 数据集库的一行代码方便地下载 COYO 数据集。要预览 COYO 数据集并了解数据处理过程和包含的元属性,请前往 Hub 数据集页面。
开始前,请安装 Hugging Face 数据集库: pip install datasets,然后下载数据集。
from datasets import load_dataset
dataset = load_dataset('kakaobrain/coyo-700m')
dataset
由于 COYO 数据集非常庞大,包含 747M 个图像 - 文本对,您可能无法在本地下载整个数据集。或者可能只需要下载和使用数据集的子集。为此,可以简单地将 streaming=True 参数传递给 load_dataset()方法,以创建可迭代数据集,并在需要时下载数据实例。
from datasets import load_dataset
dataset = load_dataset('kakaobrain/coyo-700m', streaming=True)
print(next(iter(dataset['train'])))
{'id': 2680060225205, 'url': 'https://cdn.shopify.com/s/files/1/0286/3900/2698/products/TVN_Huile-olive-infuse-et-s-227x300_e9a90ffd-b6d2-4118-95a1-29a5c7a05a49_800x.jpg?v=1616684087', 'text': 'Olive oil infused with Tuscany herbs', 'width': 227, 'height': 300, 'image_phash': '9f91e133b1924e4e', 'text_length': 36, 'word_count': 6, 'num_tokens_bert': 6, 'num_tokens_gpt': 9, 'num_faces': 0, 'clip_similarity_vitb32': 0.19921875, 'clip_similarity_vitl14': 0.147216796875, 'nsfw_score_opennsfw2': 0.0058441162109375, 'nsfw_score_gantman': 0.018961310386657715, 'watermark_score': 0.11015450954437256, 'aesthetic_score_laion_v2': 4.871710777282715}
如何使用 Hub 中的 ViT 和 ALIGN
让我们尝试一下新的 ViT 和 ALIGN 模型。由于 ALIGN 是新加入 Hugging Face Transformers 的,我们先安装最新版本的库: pip install -q git+https://github.com/huggingface/transformers.git然后导入我们将要使用的模块和库,开始使用 ViT 进行图像分类。请注意,新添加的 ALIGN 模型将会包含到下一版 PyPI 包。
import requests
from PIL import Image
import torch
from transformers import ViTImageProcessor, ViTForImageClassification
接下来,我们将从 COCO 数据集中随机下载一张有沙发图像,上边有两只猫和一个遥控器,并对图像进行预处理为模型所期望的输入格式,我们可以方便地使用相应的预处理器类 (ViTProcessor) 实现这一步。初始化模型和预处理器,可以使用 Hub 中 Kakao Brain ViT repos 之一。请注意使用 Hub 中的库预处理器,确保预处理后的图像符合特定预训练模型所需的格式。
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('kakaobrain/vit-large-patch16-384')
model = ViTForImageClassification.from_pretrained('kakaobrain/vit-large-patch16-384')
接下来将图像预处理并将其输入到模型,实现检索类别标签。Kakao Brain ViT 图像分类模型是在 ImageNet 标签上训练的,输出形状为 batch_size×1000 维度的类别 (logits)。
# preprocess image or list of images
inputs = processor(images=image, return_tensors="pt")
# inference
with torch.no_grad():
outputs = model(**inputs)
# apply SoftMax to logits to compute the probability of each class
preds = torch.nn.functional.softmax(outputs.logits, dim=-1)
# print the top 5 class predictions and their probabilities
top_class_preds = torch.argsort(preds, descending=True)[0, :5]
for c in top_class_preds:
print(f"{model.config.id2label[c.item()]} with probability {round(preds[0, c.item()].item(), 4)}")
到这里就完成了!为了更加简单和简洁,还可以使用图像分类管道 (pipeline) 并将 Kakao Brain ViT 仓库名称作为目标模型传递给初始化管道。然后,我们可以传入图像的 URL 或本地路径,或 Pillow 图像,可选“top_k”参数表述返回前 k 个预测。让我们继续对猫和遥控器图片获取前 5 个预测结果。
from transformers import pipeline
classifier = pipeline(task='image-classification', model='kakaobrain/vit-large-patch16-384')
classifier('http://images.cocodataset.org/val2017/000000039769.jpg', top_k=5)
如果您想更多地尝试 Kakao Brain ViT 模型,请前往 Hub 中心的项目空间。
我们开始实验 ALIGN,它可用于检索文本或图像的多模态嵌入或执行零样本图像分类。ALIGN 的 Transformer 实现和用法类似于 CLIP。首先,下载预训练模型和其处理器 (processor),处理器预处理图像和文本,使它们符合 ALIGN 的预期格式,以便将其输入到视觉和文本编码器中。这步导入了我们将要使用的模块并初始化预处理器和模型。
import requests
from PIL import Image
import torch
from transformers import AlignProcessor, AlignModel
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignModel.from_pretrained('kakaobrain/align-base')
先从零样本图像分类开始。为此,我们将提供候选标签 (自由格式文本),并使用 AlignModel 找出更好地描述图像的表述。我们将首先预处理图像和文本输入,并将预处理后的输入送到 AlignModel 中。
candidate_labels = ['an image of a cat', 'an image of a dog']
inputs = processor(images=image, text=candidate_labels, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# this is the image-text similarity score
logits_per_image = outputs.logits_per_image
# we can take the softmax to get the label probabilities
probs = logits_per_image.softmax(dim=1)
print(probs)
完成了,就这么简单。要进一步尝试 Kakao Brain ALIGN 模型进行零样本图像分类,只需前往 Hugging Face Hub 上的 demo 演示。请注意, AlignModel 的输出包括 text_embeds 和 image_embeds (参阅 ALIGN 的 文档)。如果不需要计算用于零样本分类的每个图像和每个文本的逻辑 (logits),可以使用 AlignModel 类中的 get_image_features() 和 get_text_features() 方法便捷地检索视觉和文本嵌入。
text_embeds = model.get_text_features(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
token_type_ids=inputs['token_type_ids'],
)
image_embeds = model.get_image_features(
pixel_values=inputs['pixel_values'],
)
或者,我们可以使用 ALIGN 的独立视觉和文本编码器获取多模态嵌入。然后可以使用这些嵌入用于各种下游任务的模型训练,例如目标检测、图像分割和图像字幕生成。让我们看看如何使用 AlignTextModel 和 AlignVisionModel 获取这些嵌入。请注意,我们可以使用便捷的 AlignProcessor 类分别对文本和图像进行预处理。
from transformers import AlignTextModel
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignTextModel.from_pretrained('kakaobrain/align-base')
# get embeddings of two text queries
inputs = processor(['an image of a cat', 'an image of a dog'], return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# get the last hidden state and the final pooled output
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_output
我们也可以在推理过程中设置 output_hidden_states 和 output_attentions 参数为 True,以返回所有隐藏状态和注意力值。
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True, output_attentions=True)
# print what information is returned
for key, value in outputs.items():
print(key)
在 AlignVisionModel 中执行相同的操作,获取图像的多模态嵌入。
from transformers import AlignVisionModel
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignVisionModel.from_pretrained('kakaobrain/align-base')
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# print the last hidden state and the final pooled output
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_output
与 ViT 类似,使用零样本图像分类管道 (pipeline) 可以让过程更加轻松。以下实现了如何使用此流程使用自由文本候选标签在野外执行图像分类。
from transformers import pipeline
classifier = pipeline(task='zero-shot-image-classification', model='kakaobrain/align-base')
classifier(
'https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png',
candidate_labels=['animals', 'humans', 'landscape'],
)
classifier(
'https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png',
candidate_labels=['black and white', 'photorealist', 'painting'],
)
结论
近年来,多模态取得了令人难以置信的进展,例如 CLIP 和 ALIGN 等模型赋能了各种下游任务,例如图像描述、零样本图像分类和开放世界目标检测。本博客,我们介绍了由 Kakao Brain 贡献的最新开源代码 ViT 和 ALIGN 模型,以及新的 COYO 文本 - 图像数据集。展示了如何使用这些模型执行各种任务,只需几行代码即可单独使用或作为 Transformers pipeline 的一部分使用。
我们正在继续整合最有影响力的计算机视觉和多模型模型,并乐于听取您的反馈。要了解计算机视觉和多模态研究的最新消息,作者及 Twitter: @adirik、@a_e_roberts、@NielsRogge、@RisingSayak 和 @huggingface。
英文原文: https://huggingface.co/blog/vit-align
作者: Alara Dirik、Unso Eun Seo Jo、Minwoo Byeon、sungjunlee
译者: Cony Zhang (张聪聪)
审校、排版: zhongdongy (阿东)
Kakao Brain 的开源 ViT、ALIGN 和 COYO 文字-图片数据集的更多相关文章
- [开源]基于WPF实现的Gif图片分割器,提取GIf图片中的每一帧
不知不觉又半个月没有更新博客了,今天终于抽出点时间,来分享一下前段时间的成果. 在网上,我们经常看到各种各样的图片,尤其是GIF图片的动态效果,让整个网站更加富有表现力!有时候,我们看到一些比较好看的 ...
- Seafile开源私有云自定义首页Logo图片
Seafile是一个开源.专业.可靠的云存储平台:解决文件集中存储.共享和跨平台访问等问题,由北京海文互知网络有限公司开发,发布于2012年10月:除了一般网盘所提供的云存储以及共享功能外,Seafi ...
- Excel催化剂开源第40波-Excel插入图片做到极致的效果
不知道是开发人员的自我要求不高还是用户的使用宽容度足够大,在众多Excel插入图片的版本中,都没有考虑到许多的可大幅度提升用户体验的细节处理. Excel催化剂虽然开发水平有限,但也在有限的能力下,尽 ...
- Excel催化剂开源第9波-VSTO开发图片插入功能,图片带事件
图片插入功能,这个是Excel插件的一大刚需,但目前在VBA接口里开发,如果用Shapes.AddPicture方法插入的图片,没法对其添加事件,且图片插入后需等比例调整纵横比例特别麻烦,特别是对于插 ...
- [js开源组件开发]js轮播图片支持手机滑动切换
js轮播图片支持手机滑动切换 carousel-image 轮播图片,支持触摸滑动. 例子见DEMO http://www.lovewebgames.com/jsmodule/carousel-ima ...
- Android开源库--Universal Image Loader通用图片加载器
如果说我比别人看得更远些,那是因为我站在了巨人的肩上. github地址:https://github.com/nostra13/Android-Universal-Image-Loader 介绍 ...
- 好用的开源库(二)——uCrop 图片裁剪
最近想要实现图片裁剪的功能,在Github上找到了这个uCrop,star的人挺多的,便是决定入坑,结果长达一个小时的看资料+摸索,终于是在项目中实现了图片裁剪的功能,今天便是来介绍一下uCrop的使 ...
- 使用开源库 SDWebImage 异步下载缓存图片(持续更新)
source https://github.com/rs/SDWebImage APIdoc http://hackemist.com/SDWebImage/doc Asynchronous im ...
- Android 开源框架Universal-Image-Loader加载https图片
解决方案就是 需要 android https HttpsURLConnection 这个类忽略证书 1,找到 Universal-Image-Loader的library依赖包下面com.nostr ...
- 机器学习开源项目精选TOP30
本文共图文结合,建议阅读5分钟. 本文为大家带来了30个广受好评的机器学习开源项目. 640?wx_fmt=jpeg&wxfrom=5&wx_lazy=1 最近,Mybridge发布了 ...
随机推荐
- centos7编译安装LNMP服务架构
CentOS7.4 源码编译安装LNMP 1.基于CentOS7.4源码编译安装得lnmp 系统环境CentOS 7.4 系统最小化安装,只安装了一些常用包(vim.lirzs.gcc*.wget. ...
- vim 基础
光标移动(命令模式的上下左右):k,j,h,l 保存/退出 仅保存::w 退出::q(如果有修改要先保存) 保存并退出::wq(x效果一致) 强制退出::q! 模式 命令模式:esc(当前需要处于插入 ...
- 替代学习物联网-云服务-01百度云MQTT
1.登录百度智能云 2.进入 物联网接入 https://console.bce.baidu.com/iot2/core/core/list https://iotcore-dev-tool.gz ...
- ZSTUOJ平台刷题③:Problem A.--打印金字塔
Problem A: 打印金字塔 Time Limit: 1 Sec Memory Limit: 64 MBSubmit: 10011 Solved: 6227 Description 请编写程序 ...
- WebStore 破解
前提 你需要首先安装该软件,并下载补丁,不过这些已经为你打包好了. WebStore 2020.1 , jetbrains-agent.jar , resources_zh_CN_WebStorm_2 ...
- FATAL Exited too quickly (process log may have details)的解决方案
作为一个混混的开发,不会啥容器操作.所以一般都是用supervisor来管理一些运行的进程 用了一段时间还是比较好用的,这个软件也是用的Python开发. 但在使用的过程中,status时会出现 FA ...
- powerbi 模板网站
微软网站 https://community.powerbi.com/t5/Themes-Gallery/bd-p/ThemesGallery 中国区powerbi比赛网站 http://www.ch ...
- uniapp 移动端渲染富文本时图片超宽解决方法
使用replace替换富文本中的图片属性 let reg = new RegExp('<img','gi'); this.info = this.info.replace(reg,'<im ...
- pandas的groupby.apply和直接apply效果是不一样的
GroupBy.apply(func, *args, **kwargs)[source] Apply function func group-wise and combine the results ...
- vim多行缩进
1.首先设置vim缩进空格 vim /etc/vim/vimrc 或者vim /etc/vimrc,添加一下文字 set smartindent set shiftwidth=4 # 缩进四个空格 # ...