python爬虫之protobuf协议介绍
前言
在你学习爬虫的知识过程中是否遇到下面的类型。如果有兴趣学习一下或者了解相关知识的,且不嫌在下才疏学浅,可以参考一下。欢迎各位网友的指正。
首先叙述一下问题的会出现的式样。
你可能会在请求参数中看到如下乱码的行为:

接着你会发现content-type数据类型为x-protobuf类型,那么可能你可能需要学习一下protobuf协议才能继续你的爬虫。

那么接下来我们叙述一下为什么会出现这个问题呢?
我不知道这样说下是否正确,仅供参考吧,可以提供一种思路。先说一个正常数据的content-type数据类型为

情况下。网页根据utf-8编码对数据进行解码。但如果content-type数据类型为x-protobuf时,他不能根据protobuf协议去解析,所以会出现乱码的行为。
接下来就进行到我们的正题吧。
首先本文会向你介绍protobuf协议的定义方式和解析方法,使你可以更深入的了解protobuf协议,在下节会介绍在爬虫中遇到protobuf
协议如何解决的实践操作。
一、什么是protobuf协议?
protobuf (protocol buffer) 是谷歌内部的混合语言数据标准。通过将结构化的数据进行序列化(串行化),用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
- 序列化:将结构数据或者对象转换成能够用于存储和传输的格式。
- 反序列化:在其他的计算环境中,将序列化后的数据还原为结构数据和对象。
1.1 序列化与反序列化的关系
如图所示程序员编写好proto文件的程序,然后编程成适应编程语言的包。这个过程可以通过下载下方链接。(后续会叙述这个过程)
https://github.com/protocolbuffers/protobuf/releases/
将proto文件编成你所需要的包。你需要做的是写出proto文件的内容。
然后通过编译成的包可以将数据和二进制之间进行转换被称为序列化和反序列化。

二、编写proto文件
2.1 为什么要编写proto文件
可能有人好奇,我们只是想把一个乱码的转换为我们能看懂的数据为什么要学习编写这个文件。那么你可以先看再看一下上方的图,如果你请求数据中携带参数是乱码的,你要造出这种乱码的数据那么就需要去学习如何通过proto编译出来的包(由于本文叙述是python语言那么这个是py文件),来将数据转换为二进制文件。以此来正常请求数据。
2.2 proto文件编写过程
首先先写一个简单的proto文件
查看代码
syntax = "proto3";
message Panda {
int32 id = 1;
string name = 2;
}
第一行确定proto使用的协议,现在大部分使用proto3而不是proto2
然后定义一个消息体里面存放一些你需要的数据字段,
其中每个数据字段都有一种类型,一个名字和一个值构成。这个值不是你的数据中的值,而是查找定义这个数据字段的类型的识别符。我没有尝试过使用非数字的情况。具体的书写格式可根据下方这个图中proto的格式进行书写。你可以根据自身的情况定义你需要的数据类型。

写完成之后将文件名称保存为xxx.proto文件。至此我们完成了编写proto的过程,接下来我们需要将写完的proto文件编译成我们程序使用的包需要,下载https://github.com/protocolbuffers/protobuf/releases/
网址中的文件,下载windows版本

设置环境变量

运行cmd,找到proto文件处

编译成python文件

至此我们就已经完成proto文件的编译了。
接下来我们开始将数据序列化为二进制
你需要安装protobuf==3.20 google以及反序列化库blackboxprotobuf

至此你已经可以完成proto文件的编写,下面是一个稍微复杂一丢丢的代码,你可以根据上方数据类型的表来看代码。下方代码可以很好的为你解析一些proto中嵌套数据的关系
代码展示
syntax = "proto3";
message Message
{
int32 id_2 = 2;
int32 id_3 = 3;
Info id_5 = 5;
message Info
{
string id_1 = 1;
repeated int32 id_2 = 2 [packed=false];
int32 id_3 = 3;
Number id_5 = 5;
message Number
{
int32 id_2 = 2;
}
repeated int32 id_8 = 8 [packed=false];
int32 id_6 = 6;
int32 id_7 = 7;
int32 id_9 = 9;
int32 id_11 = 11;
}
string id_6 = 6;
}
调用结果展示
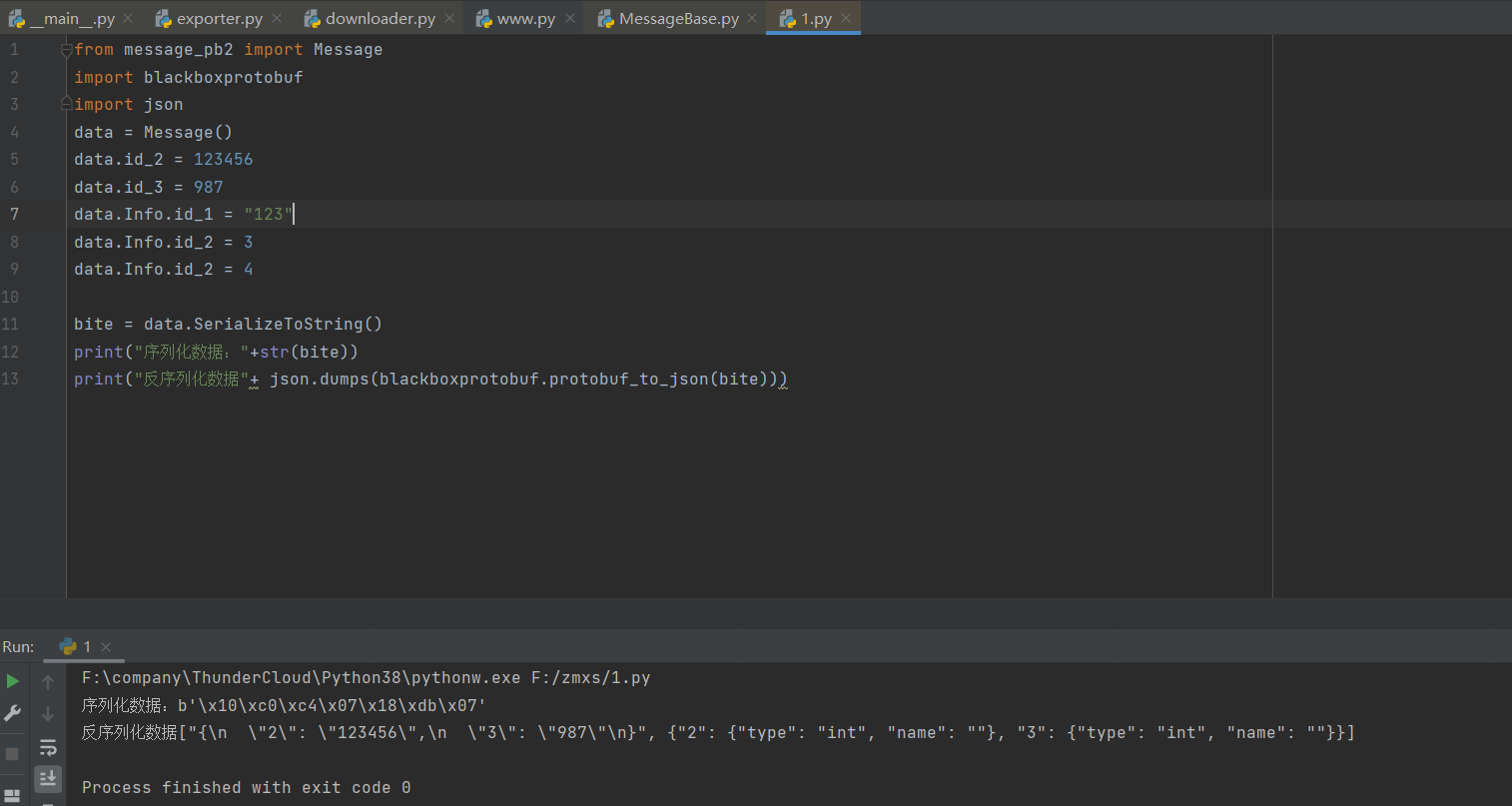
好了,上述描述为你解释了如何编写proto的过程,下面将会告诉你如何解析二进制proto的文件。先休息一下吧。
三、Protobuf数据格式解析
参考博客 https://www.cxymm.net/article/mine_song/76691817
首先我们要了解Varints编码,然后通过Varints编码了解protobuf的解码过程
3.1 Varints编码
Varint 是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。
Varint 中的每个字节(最后一个字节除外)都设置了最高有效位(msb),这一位表示还会有更多字节出现。每个字节的低 7 位用于以 7 位组的形式存储数字的二进制补码表示,最低有效组首位。
如果用不到 1 个字节,那么最高有效位设为 0 ,如下面这个例子,1 用一个字节就可以表示,所以 msb 为 0.
0000 0001
如果需要多个字节表示,msb 就应该设置为 1 。例如 300,如果用 Varint 表示的话:
1010 1100 0000 0010
如果按照正常的二进制计算的话,这个表示的是 88068 (65536 + 16384 + 4096 + 2048 + 4)。
但是如果按照 Varint 编码的方式,首先看第一个字节:10101100,最高位是 1,剩下的是 0101100,msb 为 1,表示还有剩下的字节要读取,第二个字节 00000010,最高位是 0,剩下的是 0000010,msb 为 0,表示后面没有字节了。将两个 7 为二进制数合在一起,就是目标值
0000010 0101100 => 4 + 8 + 32 + 256 = 300
这里是小端模式,低位在前,先读出来,高位在后,后读出来。所以 0000010 要放在后面计算。
3.2 protobuf解析
首先我们先写一个简单的protobuf编码,如图所示

然后将赋值

所以获得二进制位
08 01 12 04 74 65 73 74
解析叙述我们解码过程,在分析解码的过程中,我们需要了解Wire Type,每一个消息项前面都会有对应的tag,才能解析对应的数据类型,表示tag的数据类型也是Varint。
tag的计算方式: (field_number << 3) | wire_type
每种数据类型都有对应的wire_type:
| Wire Type | Meaning Used For |
|---|---|
| 0 | Varint int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit fixed64, sfixed64, double |
| 2 | Length-delimited string, bytes, embedded messages, packed repeated fields |
| 3 | Start group groups (deprecated) |
| 4 | End group groups (deprecated) |
| 5 | 32-bit fixed32, sfixed32, float |
所以wire_type最多只能支持8种,目前有6种。
所以08 对应的二进制为 :

补位之后是
0 0001 000
为什么这样写?
首先后三位是wire_type的类型 0 ,就代表是int32与我们上面定义的一致

id 在protobuf中是不显示的,只显示后面标识符1
即如下图所示:

然后由于是int32类型所以我们直接取值为 01,这个是我们赋值的值,即

这样开始分析字符串

分割0 0010 010
即标识符为2 类型Wire Type为Length-delimited string。
接下来跟着的值为字符串的长度为04那么接下来的四个数据就是字符串的数据
即74 65 73 74 ASCII转为为test至此编码的过程就完成了。
你可以尝试去学一下难度较高的解码过程,下节,我们叙述如何在爬虫中使用。
python爬虫之protobuf协议介绍的更多相关文章
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python 爬虫与HTTP协议简介
爬虫的实际例子: 搜索引擎(百度.谷歌.360搜索等). 伯乐在线. 惠惠购物助手. 数据分析与研究(数据冰山知乎专栏). 抢票软件等. 什么是网络爬虫: 通俗理解:爬虫是一个模拟人类请求网站行为的程 ...
- python爬虫之requests库介绍(二)
一.requests基于cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们 ...
- python爬虫之urllib库介绍
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- Python爬虫:HTTP协议、Requests库(爬虫学习第一天)
HTTP协议: HTTP(Hypertext Transfer Protocol):即超文本传输协议.URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源. HTTP协议 ...
- python爬虫之scrapy框架介绍
一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等) ...
- python爬虫基础01-HTTP协议
深入浅出了解HTTP协议 HTTP(HyperText Transfer Protocol,超文本传输协议)是互联网上应用最为广泛的一种网络协议.目前使用最普遍的一个版本是HTTP 1.1. HTTP ...
- Python爬虫:HTTP协议、Requests库
HTTP协议: HTTP(Hypertext Transfer Protocol):即超文本传输协议.URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源. HTTP协议 ...
- Python爬虫之requests库介绍(一)
一:Requests: 让 HTTP 服务人类 虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 ...
随机推荐
- 【2021 ICPC Asia Jinan 区域赛】 C Optimal Strategy推公式-组合数-逆元快速幂
题目链接 题目详情 (pintia.cn) 题目 题意 有n个物品在他们面前,编号从1自n.两人轮流移走物品.在移动中,玩家选择未被拿走的物品并将其拿走.当所有物品被拿走时,游戏就结束了.任何一个玩家 ...
- 【洛谷】P4555 [国家集训队]最长双回文串
P4555 [国家集训队]最长双回文串 题源:https://www.luogu.com.cn/problem/P4555 原理:Manacher 还真比KMP好理解 解决最长回文串问题 转化为长度为 ...
- 2021.11.14 CF1583E Moment of Bloom(LCA+图上构造)
2021.11.14 CF1583E Moment of Bloom(LCA+图上构造) https://www.luogu.com.cn/problem/CF1583E 题意: She does h ...
- Find the Maximum - 题解【思维,贪心】
题面 这是2022年ICPC昆明站的F题.在赛场上,我一开始敲了个贪心,但是出锅了,改敲树形DP,但是时间来不及了.在队友的提醒下补过了这个题,知道解法的我发现我就是个纯纯的老坛-- 原题链接在牛客网 ...
- Go 语言字符串常见操作
@ 目录 1. 字节数组 2. 头尾处理 3. 位置索引 4. 替换 5. 统计次数 6. 重复 7. 大小写 8. 去除字符 9. 字符串切片处理 10. 数值处理 1. 字节数组 字节与字符的区别 ...
- 睡前聊一聊"spring bean 生命周期"
spring bean 生命周期=实属初销+2个常见接口+3个Aware型接口+2个生命周期接口 实属初销:spring bean生命周期只有四个阶段,即实例化->属性赋值->初始化-&g ...
- java高级用法之:JNA中的Memory和Pointer
目录 简介 Pointer 特殊的Pointer:Opaque Memory 总结 简介 我们知道在native的代码中有很多指针,这些指针在JNA中被映射成为Pointer.除了Pointer之外, ...
- join方法原理
join()方法--原理同wait方法 如果不知道保护性暂停是啥的可以参考一下上一篇文章 https://www.cnblogs.com/duizhangz/p/16222854.html join方 ...
- 1903021121-刘明伟-java第七周作业-客户类测试
项目 内容 课程班级博客链接 19信计班(本) 作业要求链接 作业要求链接 博客名称 1903021121-刘明伟-java第七周作业-客户类测试 要求 每道题要有题目,代码,截图 第一部分: 创建客 ...
- 一、全新安装搭建redis主从集群
前言· 这里分为三篇文章来写我是如何重新搭建redis主从集群和哨兵集群的及原本服务器上有单redis如何通过升级脚本来实现redis集群.(redis结构:主-从(备)-从(备)) 至于为什么要搭建 ...