ShardingSphere-proxy-5.0.0建立mysql读写分离的连接(六)
一、修改配置文件config-sharding.yaml,并重启服务
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ######################################################################################################
#
# Here you can configure the rules for the proxy.
# This example is configuration of sharding rule.
#
######################################################################################################
#
#schemaName: sharding_db
#
#dataSources:
# ds_0:
# url: jdbc:postgresql://127.0.0.1:5432/demo_ds_0
# username: postgres
# password: postgres
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
# minPoolSize: 1
# ds_1:
# url: jdbc:postgresql://127.0.0.1:5432/demo_ds_1
# username: postgres
# password: postgres
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
# minPoolSize: 1
#
#rules:
#- !SHARDING
# tables:
# t_order:
# actualDataNodes: ds_${0..1}.t_order_${0..1}
# tableStrategy:
# standard:
# shardingColumn: order_id
# shardingAlgorithmName: t_order_inline
# keyGenerateStrategy:
# column: order_id
# keyGeneratorName: snowflake
# t_order_item:
# actualDataNodes: ds_${0..1}.t_order_item_${0..1}
# tableStrategy:
# standard:
# shardingColumn: order_id
# shardingAlgorithmName: t_order_item_inline
# keyGenerateStrategy:
# column: order_item_id
# keyGeneratorName: snowflake
# bindingTables:
# - t_order,t_order_item
# defaultDatabaseStrategy:
# standard:
# shardingColumn: user_id
# shardingAlgorithmName: database_inline
# defaultTableStrategy:
# none:
#
# shardingAlgorithms:
# database_inline:
# type: INLINE
# props:
# algorithm-expression: ds_${user_id % 2}
# t_order_inline:
# type: INLINE
# props:
# algorithm-expression: t_order_${order_id % 2}
# t_order_item_inline:
# type: INLINE
# props:
# algorithm-expression: t_order_item_${order_id % 2}
#
# keyGenerators:
# snowflake:
# type: SNOWFLAKE
# props:
# worker-id: 123 ######################################################################################################
#
# If you want to connect to MySQL, you should manually copy MySQL driver to lib directory.
#
###################################################################################################### # 连接mysql所使用的数据库名
schemaName: MyDb dataSources:
ds_0: # 主库
url: jdbc:mysql://127.0.0.1:3306/MyDb?serverTimezone=UTC&useSSL=false
username: root # 数据库用户名
password: mysql123 # 登录密码
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_0_read0: # 从库
url: jdbc:mysql://192.168.140.132:3306/MyDb?serverTimezone=UTC&useSSL=false
username: root # 数据库用户名
password: Xiaohemiao_123 # 登录密码
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1 # ds_1:
# url: jdbc:mysql://127.0.0.1:3306/demo_ds_1?serverTimezone=UTC&useSSL=false
# username: root
# password:
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
# minPoolSize: 1
#
# 规则
rules:
- !READWRITE_SPLITTING #读写分离规则
dataSources:
pr_ds:
writeDataSourceName: ds_0
readDataSourceNames:
- ds_0_read0 - !SHARDING
tables:
t_product: #需要进行分表的表名
actualDataNodes: ds_0.t_product_${0..1} # 表达式,将表分为t_product_0 , t_product_1
tableStrategy:
standard:
shardingColumn: product_id # 字段名
shardingAlgorithmName: t_product_VOLUME_RANGE
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake #雪花算法
# t_order_item:
# actualDataNodes: ds_${0..1}.t_order_item_${0..1}
# tableStrategy:
# standard:
# shardingColumn: order_id
# shardingAlgorithmName: t_order_item_inline
# keyGenerateStrategy:
# column: order_item_id
# keyGeneratorName: snowflake
# bindingTables:
# - t_order,t_order_item
# defaultDatabaseStrategy:
# standard:
# shardingColumn: user_id
# shardingAlgorithmName: database_inline
# defaultTableStrategy:
# none:
#
shardingAlgorithms:
t_product_VOLUME_RANGE: # 取模名称,可自定义
type: VOLUME_RANGE # 取模算法
props:
range-lower: '5' # 最小容量为5条数据,仅方便测试
range-upper: '10' #最大容量为10条数据,仅方便测试
sharding-volume: '5' #分片的区间的数据的间隔
# t_order_inline:
# type: INLINE
# props:
# algorithm-expression: t_order_${order_id % 2}
# t_order_item_inline:
# type: INLINE
# props:
# algorithm-expression: t_order_item_${order_id % 2}
#
keyGenerators:
snowflake: # 雪花算法名称,自定义名称
type: SNOWFLAKE
props:
worker-id: 123
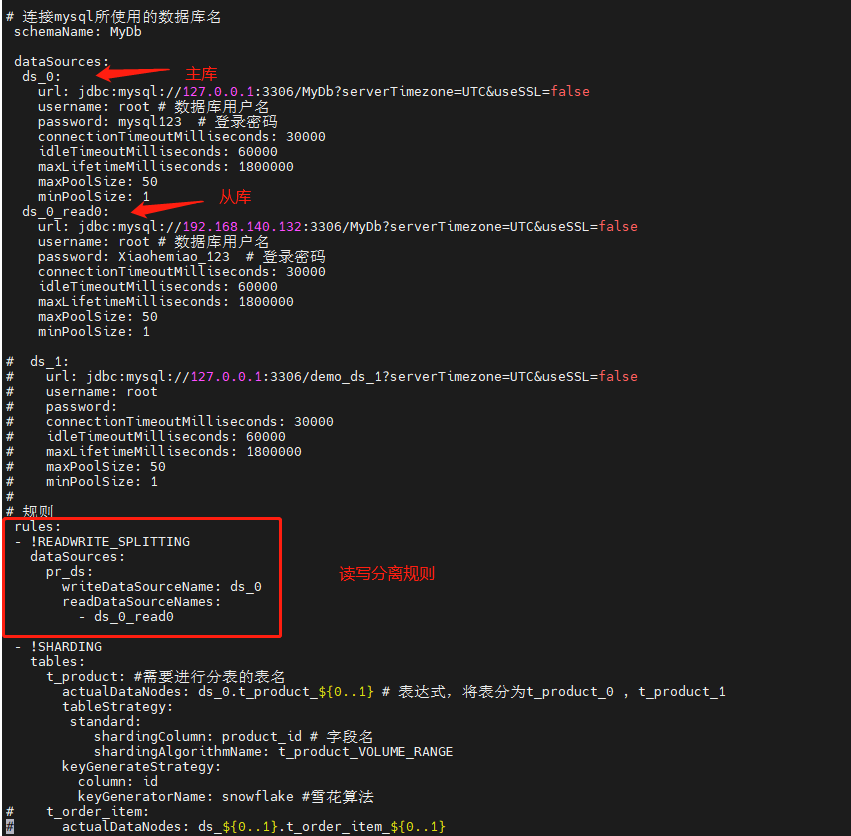
上述配置是同时有做容量范围分片
二、数据准备
在中间件中ShardingSphere中创建MyDb数据库,并创建相关表和插入数据
-- 创建表
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0; -- ----------------------------
-- Table structure for t_product
-- ----------------------------
DROP TABLE IF EXISTS `t_product`;
CREATE TABLE `t_product` (
`id` varchar(225) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`product_id` int(11) NOT NULL,
`product_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
PRIMARY KEY (`id`, `product_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1; -- 插入表数据
INSERT INTO t_product(product_id,product_name) VALUES(1,'one');
INSERT INTO t_product(product_id,product_name) VALUES(2,'two');
INSERT INTO t_product(product_id,product_name) VALUES(3,'three');
INSERT INTO t_product(product_id,product_name) VALUES(4,'four');
INSERT INTO t_product(product_id,product_name) VALUES(5,'five');
INSERT INTO t_product(product_id,product_name) VALUES(6,'six');
INSERT INTO t_product(product_id,product_name) VALUES(7,'seven');
三、查看数据

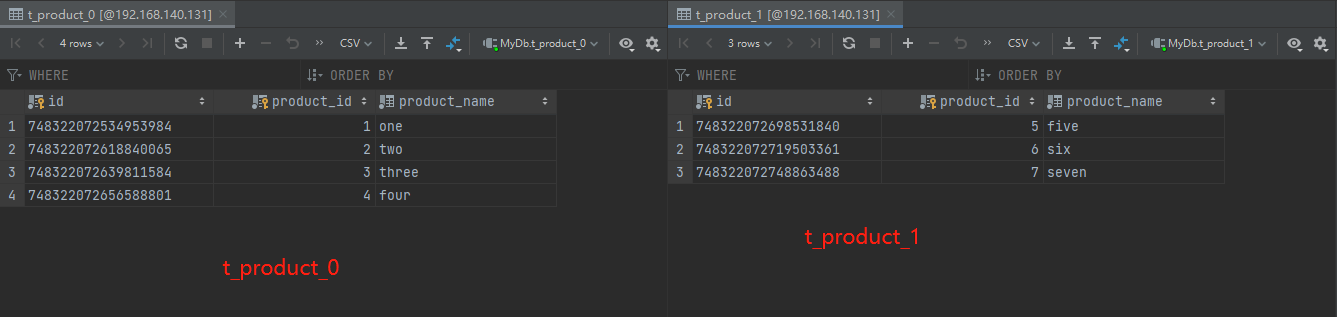
1、查看shardingsphere中间件t_product表数据

2、主库192.168.140.131数据
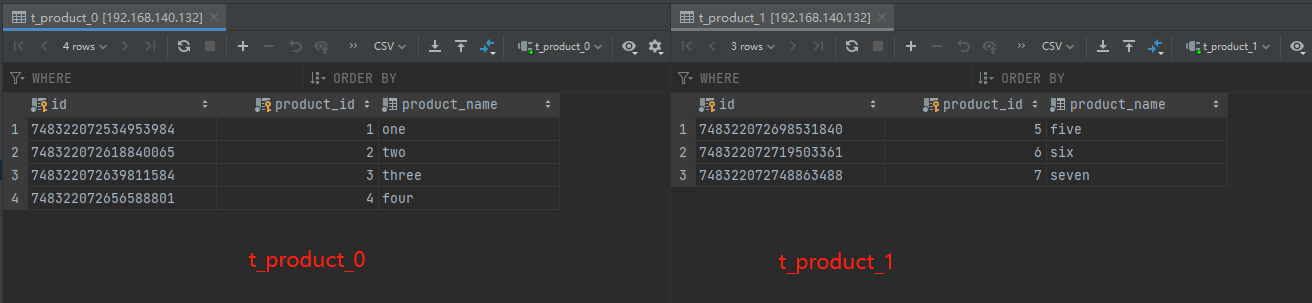
3、主库192.168.140.132数据
ShardingSphere-proxy-5.0.0建立mysql读写分离的连接(六)的更多相关文章
- Mysql读写分离-Amoeba Proxy
参考:http://www.linuxidc.com/Linux/2015-10/124115.htm 一个完整的MySQL读写分离环境包括以下几个部分: 应用程序client database pr ...
- MySQL读写分离技术
1.简介 当今MySQL使用相当广泛,随着用户的增多以及数据量的增大,高并发随之而来.然而我们有很多办法可以缓解数据库的压力.分布式数据库.负载均衡.读写分离.增加缓存服务器等等.这里我们将采用读写分 ...
- Mysql-Proxy实现mysql读写分离、负载均衡 (转)
在mysql中实现读写分离.负载均衡,用Mysql-Proxy是很容易的事,不过大型处理对于性能方面还有待提高,主要配置步骤如下: 1.1. mysql-proxy安装 MySQL Proxy就是这么 ...
- Database基础(六):实现MySQL读写分离、MySQL性能调优
一.实现MySQL读写分离 目标: 本案例要求配置2台MySQL服务器+1台代理服务器,实现MySQL代理的读写分离: 用户只需要访问MySQL代理服务器,而实际的SQL查询.写入操作交给后台的2台M ...
- [mysql]linux mysql 读写分离
[mysql]linux mysql 读写分离 作者:flymaster qq:908601287 blog:http://www.cnblogs.com/flymaster500/ 1.简介 当今M ...
- amoeba实现MySQL读写分离
amoeba实现MySQL读写分离 准备环境:主机A和主机B作主从配置,IP地址为192.168.131.129和192.168.131.130,主机C作为中间件,也就是作为代理服务器,IP地址为19 ...
- php实现MySQL读写分离
MySQL读写分离有好几种方式 MySQL中间件 MySQL驱动层 代码控制 关于 中间件 和 驱动层的方式这里不做深究 暂且简单介绍下 如何通过PHP代码来控制MySQL读写分离 我们都知道 &q ...
- mysql读写分离——中间件ProxySQL的简介与配置
mysql实现读写分离的方式 mysql 实现读写分离的方式有以下几种: 程序修改mysql操作,直接和数据库通信,简单快捷的读写分离和随机的方式实现的负载均衡,权限独立分配,需要开发人员协助. am ...
- ProxySQL实现Mysql读写分离 - 部署手册
ProxySQL是一个高性能的MySQL中间件,拥有强大的规则引擎.ProxySQL是用C++语言开发的,也是percona推的一款中间件,虽然也是一个轻量级产品,但性能很好(据测试,能处理千亿级的数 ...
随机推荐
- CF #781 (Div. 2), (C) Tree Infection
Problem - C - Codeforces Example input 5 7 1 1 1 2 2 4 5 5 5 1 4 2 1 3 3 1 6 1 1 1 1 1 output 4 4 2 ...
- redis在物理机部署模式下如何进行资源[cpu、网卡]隔离
上周末晚上运营做直播,业务代码不规范,访问1个redis竟然把1台服务器的网卡打满了,这台服务器上的其他redis服务都受到了影响.之前没有做这方面的预案,当时又没有空闲的机器可以迁移,在当时一点办法 ...
- vue动态绑定属性--基本用法及动态绑定class
动态绑定属性v-bind:,语法糖形式:省略v-bind,仅写一个冒号. 一.动态绑定基本属性 1 <body> 2 <!-- v-bind 动态绑定属性-基本用法 --> 3 ...
- 20202127 实验一《Python程序设计》实验报告
20202127 2022-2022-2 <Python程序设计>实验一报告课程:<Python程序设计>班级: 2021姓名: 马艺洲学号:20202127实验教师:王志强实 ...
- 小米手机简单 ROOT教程(百分百成功)
大家都知道啊,由于小米自带的换机软件不支持一些应用数据的还原,所以需要使用钛备份来还原应用和数据.但是钛备份需要root才能用,因为有些机器刚出没多久,第三方的recovery也没有,所以需要找到一种 ...
- prometheus监控预警之AlertManager邮箱报警
Alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,例如邮件.微信.钉钉.Slack 等常用沟通工具,而且很容易做到告警信息进行去重,降噪,分组等, ...
- .NET性能优化-你应该为集合类型设置初始大小
前言 计划开一个新的系列,来讲一讲在工作中经常用到的性能优化手段.思路和如何发现性能瓶颈,后续有时间的话应该会整理一系列的博文出来. 今天要谈的一个性能优化的Tips是一个老生常谈的点,但是也是很多人 ...
- CSS预编译器
零.CSS预编译器 CSS预处理器是指对生成CSS前的某一语法的处理.CSS预处理器用一种专门的编程语言,进行Web页面样式设计,然后再编译成正常的CSS文件,供项目使用 CSS预处理器为CSS增加一 ...
- Java多线程——实现
"java多线程的实现--几乎都要和java.lang.Thread打交道" 方式一:继承于Thread类 1.创建一个继承于Thread类的子类 2.重写Thread类的run( ...
- 一文带你读懂zookeeper在大数据生态的应用
一个执着于技术的公众号 一.简述 在一群动物掌管的世界中,动物没有人类聪明的思想,为了保持动物世界的生态平衡,这时,动物管理员-zookeeper诞生了. 打开Apache zookeeper的官网, ...