logging日志模块详细,日志模块的配置字典,第三方模块的下载与使用
logging日志模块详细
简介
用Python写代码的时候,在想看的地方写个print xx 就能在控制台上显示打印信息,这样子就能知道它是什么
了,但是当我需要看大量的地方或者在一个文件中查看的时候,这时候print就不大方便了,所以Python引入了
logging模块来记录我想要的信息。
print也可以输入日志,logging相对print来说更好控制输出在哪个地方,怎么输出及控制消息级别来过滤掉
那些不需要的信息。
日志级别
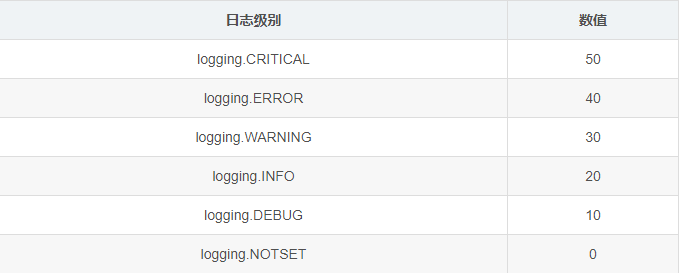
级别排序:CRITICAL > ERROR > WARNING > INFO > DEBUG
debug : 打印全部的日志,详细的信息,通常只出现在诊断问题上
info : 打印info,warning,error,critical级别的日志,确认一切按预期运行
warning : 打印warning,error,critical级别的日志,一个迹象表明,一些意想不到的事情发生了,或表
明一些问题在不久的将来(例如。磁盘空间低”),这个软件还能按预期工作
error : 打印error,critical级别的日志,更严重的问题,软件没能执行一些功能
critical : 打印critical级别,一个严重的错误,这表明程序本身可能无法继续运行
日志级别(默认值为logging.WARNING),系统内置的级别有六种:DEBUG、INFO、WARNING、ERROR以及
CRITICAL,系统会输出到控制台或者保存到日志文件的日志信息一定是等于或者高于当前等级的信息,例如
当level=logging.WARNING时,只会输出或者保存WARNING、ERROR和CRITICAL级别的信息,其他级别的
日志信息不会显示或保存,这也是level这个参数控制输出的意义所在。
名词解释
Logging.Formatter:这个类配置了日志的格式, 在里面自定义设置日期和时间,输出日志的时候将会按照设置的格式显示内容。
Logging.Logger:Logger是Logging模块的主体,进行以下三项工作:
1. 为程序提供记录日志的接口
2. 判断日志所处级别,并判断是否要过滤
3. 根据其日志级别将该条日志分发给不同handler
常用函数有:
Logger.setLevel() 设置日志级别
Logger.addHandler() 和 Logger.removeHandler() 添加和删除一个Handler
Logger.addFilter() 添加一个Filter,过滤作用
Logging.Handler:Handler基于日志级别对日志进行分发,如设置为WARNING级别的Handler只会处理WARNING及以上级别的日志。
常用函数有:
setLevel() 设置级别
setFormatter() 设置Formatter
基本使用
import logging
# 1.logger对象:产生日志 (无包装的产品)
logger = logging.getLogger('用户名')
# 2.filter对象:过滤日志 (剔除不良品)
# 针对过滤功能完全可以不看 因为handler自带了基本的过滤操作
# 3.handler对象:控制日志的输出位置(文件、终端...) (产品分类)
hd1 = logging.FileHandler('a1.log',encoding='utf-8') # 输出到文件中
# 4.format对象:控制日志的格式 (包装)
fm1 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
fm2 = logging.Formatter(
fmt='%(asctime)s - %(name)s: %(message)s',
datefmt='%Y-%m-%d',
)
# 5.给logger对象绑定handler对象
logger.addHandler(hd1)
# 6.给handler绑定formmate对象
hd1.setFormatter(fm1)
# 7.设置日志等级
logger.setLevel(10) # debug
# 8.记录日志
logger.debug('春游去动物园')
配置字典(必须的会修改配置,使用时可以复制)
'''
Python 3.2中引入的一种新的配置日志记录的方法--用字典来保存logging配置信息。这相对于上面所
讲的基于配置文件来保存logging配置信息的方式来说,功能更加强大,也更加灵活,因为我们可把很多的
数据转换成字典。
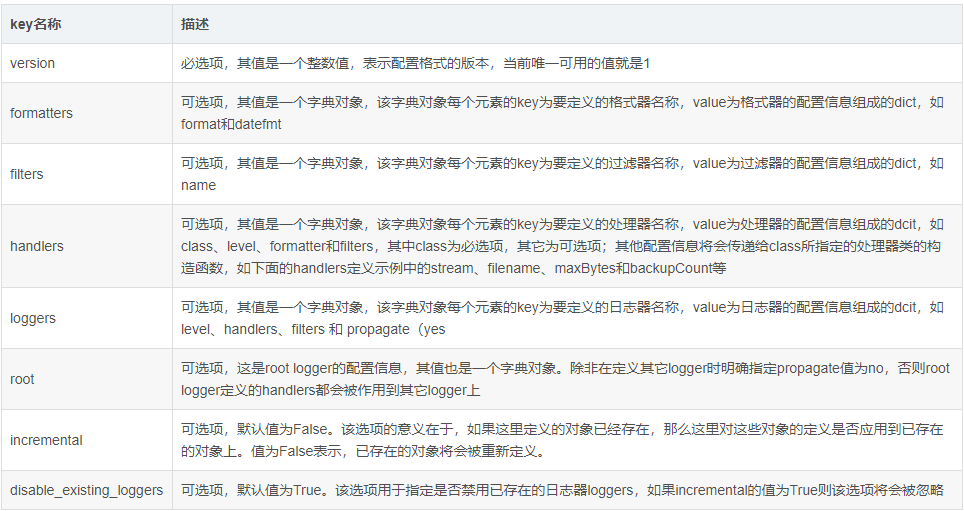
传递给dictConfig()函数的字典对象只能包含下面这些keys,其中version是必须指定的key,其它key
都是可选项:
'''
'''基本使用'''
import logging
import logging.config
# 定义日志输出格式 开始
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
# 定义日志输出格式 结束
# 自定义文件路径
logfile_path = 'a1.log'
# log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
# '注册记录': {
# 'handlers': ['console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
# 'level': 'WARNING',
# 'propagate': True, # 向上(更高level的logger)传递
# }, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
},
}
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
logger1 = logging.getLogger('注册功能')
'''loggers配置中使用空字符串作为字典的键 兼容性最好!!!'''
logger1.debug('春游去动物园')
配置字典再项目中的使用
def get_logger(msg):
# 记录日志
logging.config.dictConfig(settings.LOGGING_DIC) # 自动加载字典中的配置
# settings.LOGGING_DIC为配置文件中的一个配置字典
logger1 = logging.getLogger(msg)
# logger1.debug(f'{username}注册成功') # 这里让用户自己写更好
return logger1 #返回一个logger1对象
第三方库或模块
第三方库安装
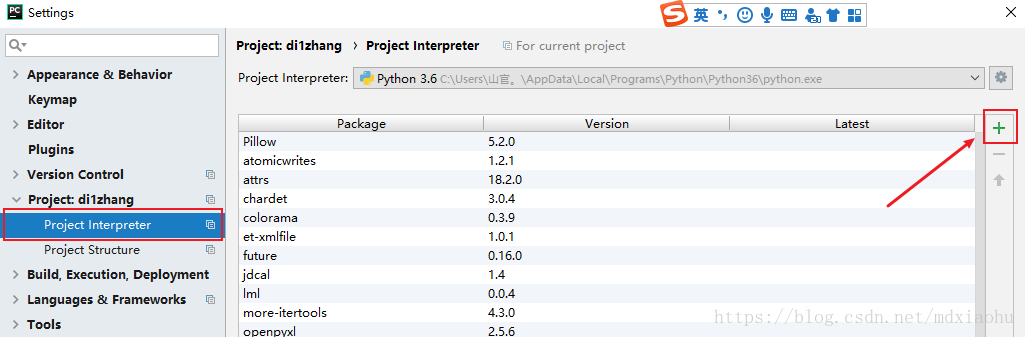
通过Pycharm的设置安装第三方模块
File(文件)--> Settings(设置)--> Project:项目名字 --> Project Interpreter
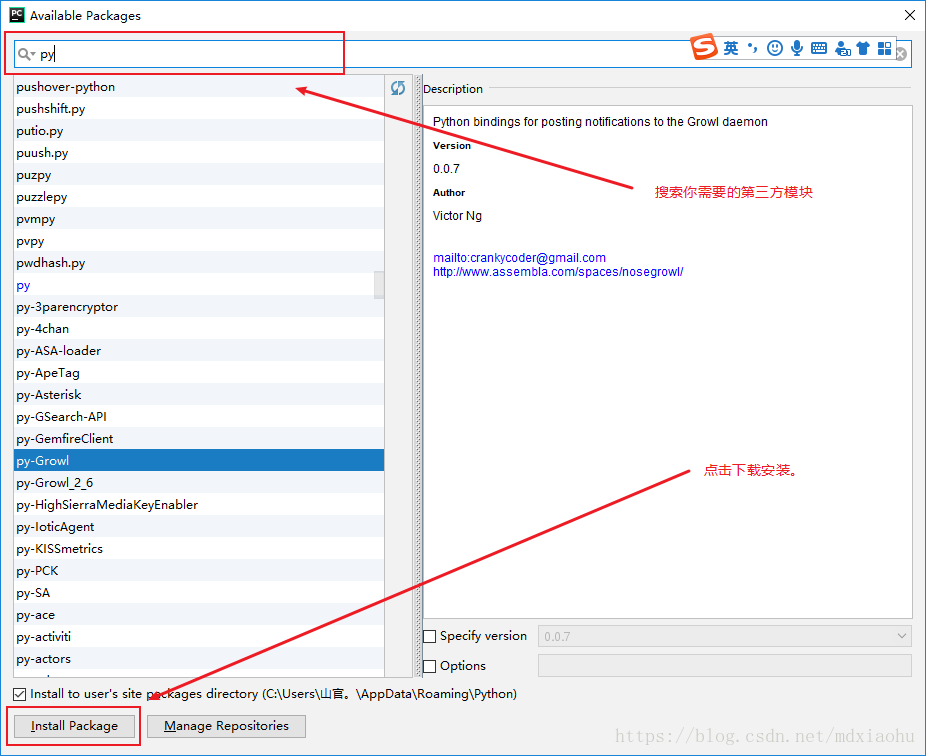
在终端使用pip安装
pip3 install 模块名 '''该方式默认下载的是最新版本'''
pip3 install 模块名==版本号 '''自定义下载版本号'''
ps:pip工具默认是从国外的仓库下载模块 速度会比较慢 可以修改
pip3 install 模块名 -i 仓库地址 # 命令行临时修改地址
"""
针对仓库地址 直接百度搜索pip源即可获得
(1)阿里云http://mirrors.aliyun.com/pypi/simple/
(2)豆瓣http://pypi.douban.com/simple/
(3)清华大学https://pypi.tuna.tsinghua.edu.cn/simple/
(4)中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
(5)华中科技大学http://pypi.hustunique.com/
"""
openpyxl模块
简介
pip3 install openpyxl 安装
"""
excel文件的版本及后缀
2003版本之前 excel的文件后缀是xls
2003版本之后 excel的文件后缀是xlsx、csv
在python中能够处理excel文件的模块有很多 其中最出名的有
xlrd、xlwt分别控制excel文件的读写 能够兼容所有版本的文件
openpyxl针对03版本之前的兼容性可能不好 但是功能更加强大
"""
excel文档的基本定义
(1) 工作薄(workbook):一个EXCEL文件就称为一个工作薄,一个工作薄中可以包含若干张工作表。
(2) 工作表(sheet):工作薄中的每一张表格称为工作表,每张工作表都有一个标签,默认为sheet1\sheet2\sheet3来命名,(一个工作 薄默认为由3个工作表组成)
(3) 活动表(active sheet):指当前正在操作的工作表
(4) 行(row): 工作表中的每一行行首数字(1、2、3、)称为行标题;一张工作表最多有65536行
(5) 列(column): 列标题:工作表中每一列列首的字母(A、B、C)称为列标题;一张工作表最多有256列
(6)单元格(cell): 工作表的每一个格称为单元格
openpyxl基本用法
1.创建excel文件
from openpyxl import Workbook
wb = Workbook() # 创建excel文件
wb1 = wb.create_sheet('Book1')
wb2 = wb.create_sheet('Book2', 0) # 还可以指定工作簿位置
wb1.title = 'Book3' # 修改Book1的表名
wb.save('Book1.xlsx') # 保存excel文件
2.添加数据
# 写普通数据方式1
wb1['A3'] = 666
# 写普通数据方式2
wb1.cell(row=3, column=4, value=999)
# 批量写普通数据
wb1.append(['id','username','password'])
# 写公式数据(也可以在python代码中处理完毕以普通数据写入)
wb1['A6'] = '=sum(A4:A5)'
3.读取数据
from openpyxl import load_workbook
'''
sheetnames:获取工作簿中的表(列表)
active:获取当前活跃的Worksheet
worksheets:以列表的形式返回所有的Worksheet(表格)
read_only:判断是否以read_only模式打开Excel文档
encoding:获取文档的字符集编码
properties:获取文档的元数据,如标题,创建者,创建日期等
'''
print(wb.sheetnames)
print(wb.active)
print(wb.worksheets)
print(wb.read_only)
print(wb.encoding)
print(wb.properties)
4.Worksheet,Cell对象(工作表操作,单元格)
Worksheet:
title:表格的标题
max_row:表格的最大行
min_row:表格的最小行
max_column:表格的最大列
min_column:表格的最小列
rows:按行获取单元格(Cell对象) - 生成器
columns:按列获取单元格(Cell对象) - 生成器
values:按行获取表格的内容(数据) - 生成器
Cell:
row:单元格所在的行
column:单元格坐在的列
value:单元格的值
coordinate:单元格的坐标
print(wb1['A3'].value) # 不是结果 需要再点value
print(wb1['A6'].value) # 获取用函数统计的数据,发生无法取到值
print(wb1.cell(row=3,column=4).value) # 第二种取值方式
# 获取一行行的数据
for row in wb1.rows: # 拿到每一行的数据
for data in row: # 拿到一行行数据里面每一个单元格的数据
print(data.value)
# 获取一列列的数据(如果想获取 必须把readonly去掉)
for column in wb1.columns: # 拿到每一列的数据
for r in column: # 拿到一列列数据里面每一个单元格的数据
print(r.value)
# 获取最大的行数和列数
print(wb1.max_row)
print(wb1.max_column)
logging日志模块详细,日志模块的配置字典,第三方模块的下载与使用的更多相关文章
- syslog-ng日志收集分析服务搭建及配置
syslog-ng日志收集分析服务搭建及配置:1.网上下载eventlog_0.2.12.tar.gz.libol-0.3.18.tar.gz.syslog-ng_3.3.5.tar.gz三个软件: ...
- python 常用第三方模块
除了内建的模块外,Python还有大量的第三方模块. 基本上,所有的第三方模块都会在https://pypi.python.org/pypi上注册,只要找到对应的模块名字,即可用pip安装. 本章介绍 ...
- nw.js node-webkit系列(15)如何使用内部模块和第三方模块进行开发
原文链接:http://blog.csdn.net/zeping891103/article/details/50786259 原谅原版链接:https://github.com/nwjs/nw.js ...
- [转] Python 常用第三方模块 及PIL介绍
原文地址 除了内建的模块外,Python还有大量的第三方模块. 基本上,所有的第三方模块都会在PyPI - the Python Package Index上注册,只要找到对应的模块名字,即可用pip ...
- nginx增加第三方模块
增加第三方模块 ============================================================ 一.概述nginx文件非常小但是性能非常的高效,这方面完胜ap ...
- Python学习手册之__main__ 模块,常用第三方模块和打包发布
在上一篇文章中,我们介绍了 Python 的 元组拆包.三元运算符和对 Python 的 else 语句进行了深入讲解,现在我们介绍 Python 的 __main__ 模块.常用第三方模块和打包发布 ...
- Anaconda安装第三方模块
Anaconda安装第三方模块 普通安装: 进去\Anaconda\Scripts目录,conda install 模块名 源码安装: 进去第三方模块目录,python install setup.p ...
- 5.pycharm中导入第三方模块的方法
最近刚入门学习python,网上查找了一些资料,发现python编程用的软件pycharm还是比较多的,于是就跟随大众,学习使用pycharm,在学习的过程中,想要导入第三方模块pyperclip,但 ...
- node 中第三方模块的加载过程原理
node 中第三方模块的加载过程原理 凡是第三方模块都必须通过 npm 来下载 使用的时候就可以通过require('包名') 的方式来进行加载才可以使用 不可能有任何一个第三方包和核心模块的名字是一 ...
随机推荐
- 学习zabbix(十)
Zabbix 3.0 基础介绍 [一] 一.Zabbix介绍 zabbix 简介 Zabbix 是一个高度集成的网络监控解决方案,可以提供企业级的开源分布式监控解决方案,由一个国外的团队持续维护更 ...
- 数据库学习之"清理表内所有数据"
今天在写定时任务的时候表内的数据都出现了问题,所以用了 1 truncate table 表名 来清空表内的数据
- java中finally有什么意义呢,在现实中?举例
马克-to-win: finally有什么意义呢,在现实中?比如你开了一个流处理文件,可能没开成功,或开成功了,但后面的操作失败了,但不管你怎么样,你必须在一个地儿把它关闭,那就是finally块儿. ...
- java读取xml文件并转换成对象,并进行修改
1.首先要写工具类,处理读取和写入xml文件使用的工具.XMLUtil.javaimport java.io.FileInputStream; import java.io.FileWriter; i ...
- VUE3 之 全局 Mixin 与 自定义属性合并策略 - 这个系列的教程通俗易懂,适合新手
1. 概述 老话说的好:心态决定命运,好心态才能有好的命运. 言归正传,今天我们来聊聊 VUE 中的全局 Mixin 与 自定义属性合并策略. 2. Mixin 的使用 2.1 全局 Mixin 之前 ...
- C# 将PDF转为Excel
通常,PDF格式的文档能支持的编辑功能不如office文档多,针对PDF文档里面有表格数据的,如果想要编辑表格里面的数据,可以将该PDF文档转为Excel格式,然后编辑.本文,将以C#代码为例,介绍如 ...
- spring原始注解(value)-03
本博客依据是是spring原始注解-02的代码 注入普通数据类型:@Value注解的使用 1.添加driver属性,使用value注解 @Service("userService" ...
- ssm整合-ssmbuild
目录 项目结构 导入相关的pom依赖 Maven资源过滤设置 建立基本结构和配置框架 Mybatis层编写 Spring层 Spring整合service层 SpringMVC层 Controller ...
- 导出带标签的tar包(docker)-解决导出不带标签的麻烦
需求:在docker的本地镜像库中导出tar包给其他节点使用. 如果使用:docker save -o package.tar e82656a6fc 这样形式导出的tar包,安装之后标签会消失解决办法 ...
- uniapp-uni.setNavigationBarColor 动态修改顶部背景颜色
uni.setNavigationBarColor({ frontColor: '#ffffff', backgroundColor: "#3583ff" })