Numpy实现机器学习交叉验证的数据划分
Numpy实现K折交叉验证的数据划分
本实例使用Numpy的数组切片语法,实现了K折交叉验证的数据划分
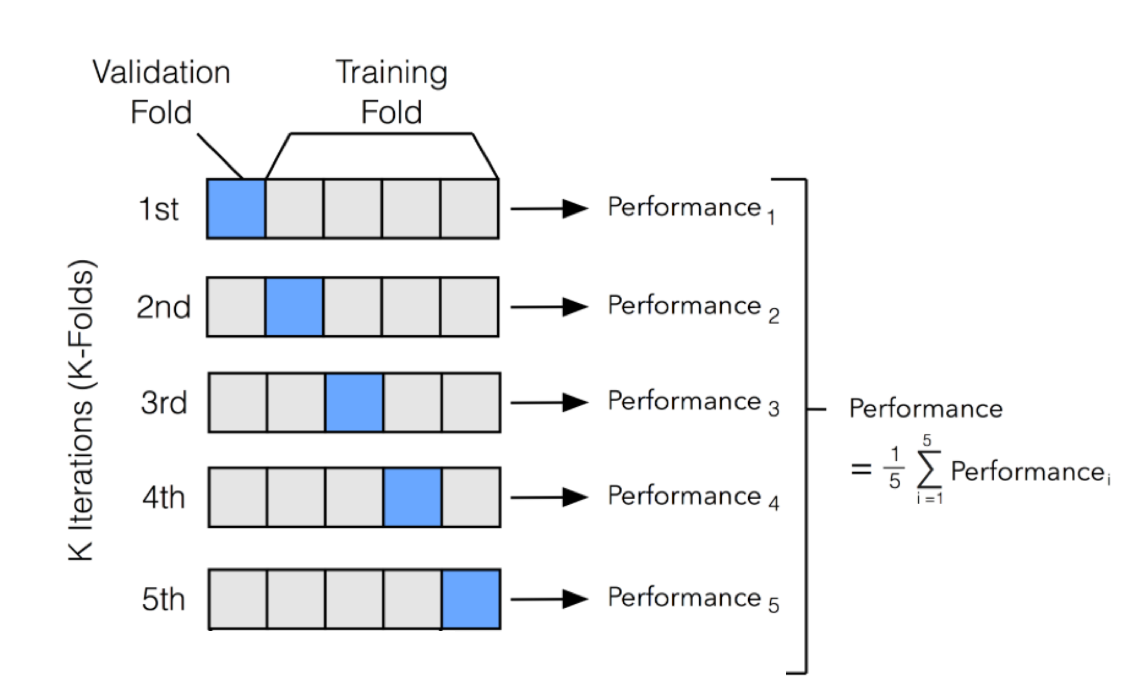
背景:K折交叉验证
为什么需要这个?
在机器学习中,因为如下原因,使用K折交叉验证能更好评估模型效果:
- 样本量不充足,划分了训练集和测试集后,训练数据更少;
- 训练集和测试集的不同划分,可能会导致不同的模型性能结果;
K折验证是什么
K折验证(K-fold validtion)将数据划分为大小相同的K个分区。
对每个分区i,在剩余的K-1个分区上训练模型,然后在分区i上评估模型。
最终分数等于K个分数的平均值,使用平均值来消除训练集和测试集的划分影响;
1. 模拟构造样本集合
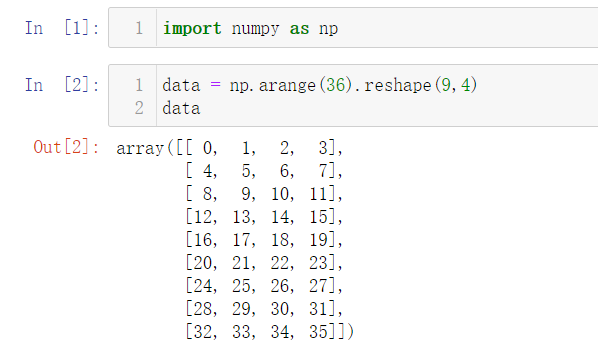
用样本的角度解释下data数组:
- 这是一个二维矩阵,行代表每个样本,列代表每个特征
- 这里有9个样本,每个样本有4个特征
这是scikit-learn模型训练输入的标准格式
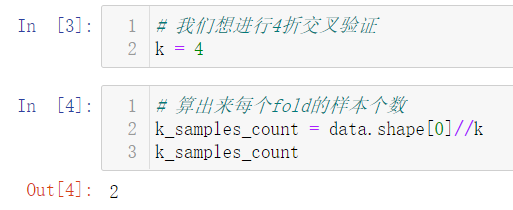
2. 使用Numpy实现K次划分
for fold in range(k):
validation_begin = k_samples_count*fold
validation_end = k_samples_count*(fold+1) validation_data = data[validation_begin:validation_end] # np.vstack,沿着垂直的方向堆叠数组
train_data = np.vstack([
data[:validation_begin],
data[validation_end:]
]) print()
print(f"#####第{fold}折#####")
print("验证集:\n", validation_data)
print("训练集:\n", train_data)
结果:
#####第0折#####
验证集:
[[0 1 2 3]
[4 5 6 7]]
训练集:
[[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]
[32 33 34 35]] #####第1折#####
验证集:
[[ 8 9 10 11]
[12 13 14 15]]
训练集:
[[ 0 1 2 3]
[ 4 5 6 7]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]
[32 33 34 35]] #####第2折#####
验证集:
[[16 17 18 19]
[20 21 22 23]]
训练集:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[24 25 26 27]
[28 29 30 31]
[32 33 34 35]] #####第3折#####
验证集:
[[24 25 26 27]
[28 29 30 31]]
训练集:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[32 33 34 35]]
如果使用scikit-learn,已经有封装好的实现:
from sklearn.model_selection import cross_val_score
Numpy实现机器学习交叉验证的数据划分的更多相关文章
- 机器学习——交叉验证,GridSearchCV,岭回归
0.交叉验证 交叉验证的基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set) ...
- 机器学习 - 案例 - 样本不均衡数据分析 - 信用卡诈骗 ( 标准化处理, 数据不均处理, 交叉验证, 评估, Recall值, 混淆矩阵, 阈值 )
案例背景 银行评判用户的信用考量规避信用卡诈骗 ▒ 数据 数据共有 31 个特征, 为了安全起见数据已经向了模糊化处理无法读出真实信息目标 其中数据中的 class 特征标识为是否正常用户 (0 代表 ...
- 机器学习中的train valid test以及交叉验证
转自 https://www.cnblogs.com/rainsoul/p/6373385.html 在以前的网络训练中,有关于验证集一直比较疑惑,在一些机器学习的教程中,都会提到,将数据集分为三部分 ...
- 机器学习基础:(Python)训练集测试集分割与交叉验证
在上一篇关于Python中的线性回归的文章之后,我想再写一篇关于训练测试分割和交叉验证的文章.在数据科学和数据分析领域中,这两个概念经常被用作防止或最小化过度拟合的工具.我会解释当使用统计模型时,通常 ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | model selection and training/validation/test sets(模型选择以及训练集、交叉验证集和测试集的概念)
怎样选用正确的特征构造学习算法或者如何选择学习算法中的正则化参数lambda?这些问题我们称之为模型选择问题. 在对于这一问题的讨论中,我们不仅将数据分为:训练集和测试集,而是将数据分为三个数据组:也 ...
- Spark机器学习——模型选择与参数调优之交叉验证
spark 模型选择与超参调优 机器学习可以简单的归纳为 通过数据训练y = f(x) 的过程,因此定义完训练模型之后,就需要考虑如何选择最终我们认为最优的模型. 如何选择最优的模型,就是本篇的主要内 ...
- Spark2.0机器学习系列之2:基于Pipeline、交叉验证、ParamMap的模型选择和超参数调优
Spark中的CrossValidation Spark中采用是k折交叉验证 (k-fold cross validation).举个例子,例如10折交叉验证(10-fold cross valida ...
- 机器学习--K折交叉验证和非负矩阵分解
1.交叉验证 交叉验证(Cross validation),交叉验证用于防止模型过于复杂而引起的过拟合.有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法. 于是可以先在一个子集上做 ...
- 机器学习 数据量不足问题----1 做好特征工程 2 不要用太多的特征 3 做好交叉验证 使用线性svm
来自:https://www.zhihu.com/question/35649122 其实这里所说的数据量不足,可以换一种方式去理解:在维度高的情况下,数据相对少.举一个特例,比如只有一维,和1万个数 ...
随机推荐
- AcWing 207. 球形空间产生器
传送门 思路: 设球心坐标为(x1,x2,...,xn),有 ,由此我们可以列出N+1个二次方程,我们可以对前后两个方程做差,来得到N个一次方程,同时可以消掉常数C,第i个方程即 那么我们就可以直接采 ...
- 《Selenium+Pytest Web自动化实战》随到随学在线课程,零基础也能学!
课程介绍 课程主题:<Selenium+Pytest Web自动化实战> 适合人群: 1.功能测试转型自动化测试 2.web自动化零基础的小白 3.对python 和 selenium 有 ...
- WPS:想让一个新标题后总跟着一种特定样式的文字
只需在这个后续段落样式中修改为你想要的那个样式即可
- Scrapy(六):Spider
总结自:Spiders - Scrapy 2.5.0 documentation Spider 1.综述 ①在回调函数Parse及其他自写的回调函数中,必须返回Item对象.Request对象.或前两 ...
- webstorm安装vue插件及安装过程出现的问题
想要编辑器识别vue文件需要安装vue插件 1. 安装方法: File--> setting --> plugin ,点击plugin,在内容部分的左侧输入框输入vue,会出现1个关于 ...
- 禁用所有控制台console.log()打印
在前端dev的环境下,经常会用到console.log()进行调试,以方便开发, 而在产品release的版本中,又不合适在浏览器的console中输出那么多的调试信息. 但是会经常因为没有删除这些开 ...
- mysql通过mysqldunp命令重做从库详细操作步骤
mysql通过mysqldunp命令重做从库详细操作步骤 背景 生产环境上的主从复制集群,因为一些异常或人为原因,在从库做了一些操作,导致主从同步失败.一般修复起来比较麻烦,通过重做mysql从库的方 ...
- ElasticSearch 文档(document)内部机制详解
1.数据路由 1.1 文档存储怎么路由到相应分片? 一个文档,最终会落在主分片的一个分片上,到底应该在哪一个分片?这就是数据路由. 1.2 路由算法 shard = hash(routing) % n ...
- petite-vue源码剖析-双向绑定`v-model`的工作原理
前言 双向绑定v-model不仅仅是对可编辑HTML元素(select, input, textarea和附带[contenteditable=true])同时附加v-bind和v-on,而且还能利用 ...
- think php 7天免登录
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...