Numpy实现机器学习交叉验证的数据划分
Numpy实现K折交叉验证的数据划分
本实例使用Numpy的数组切片语法,实现了K折交叉验证的数据划分
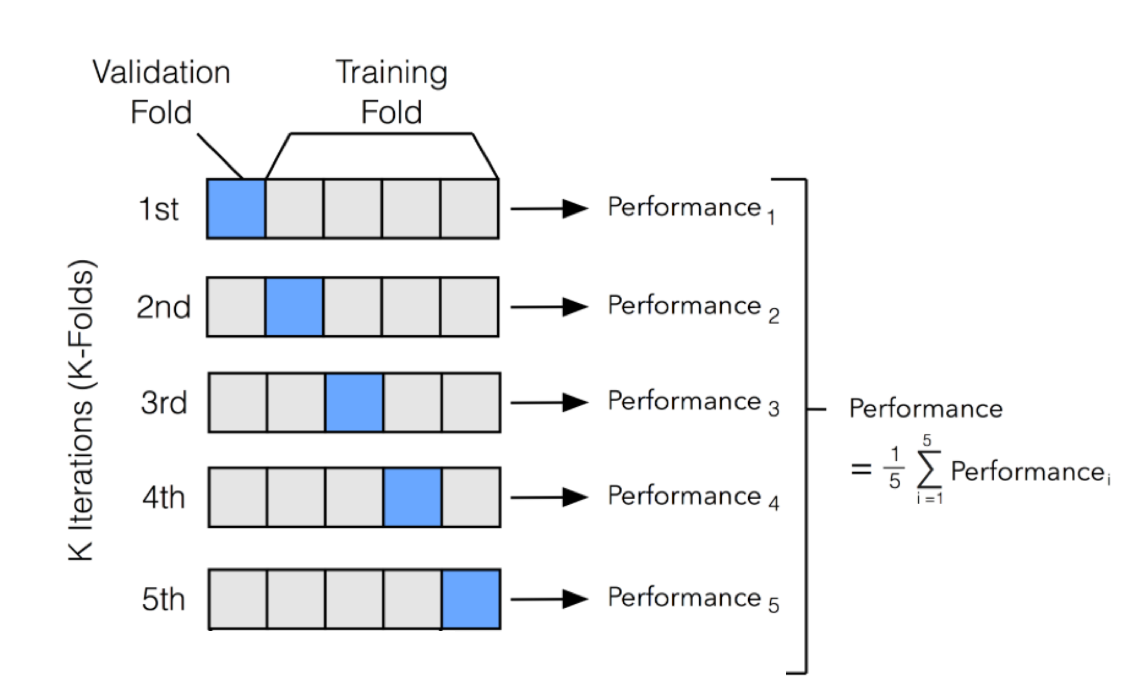
背景:K折交叉验证
为什么需要这个?
在机器学习中,因为如下原因,使用K折交叉验证能更好评估模型效果:
- 样本量不充足,划分了训练集和测试集后,训练数据更少;
- 训练集和测试集的不同划分,可能会导致不同的模型性能结果;
K折验证是什么
K折验证(K-fold validtion)将数据划分为大小相同的K个分区。
对每个分区i,在剩余的K-1个分区上训练模型,然后在分区i上评估模型。
最终分数等于K个分数的平均值,使用平均值来消除训练集和测试集的划分影响;
1. 模拟构造样本集合
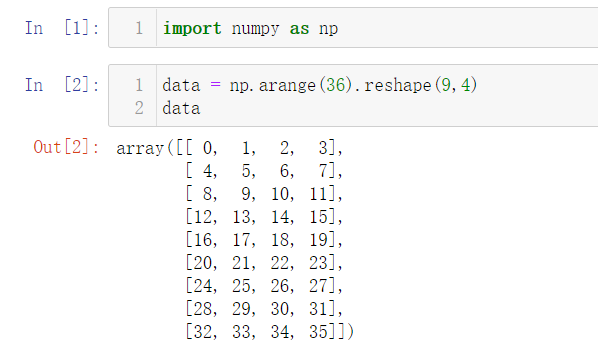
用样本的角度解释下data数组:
- 这是一个二维矩阵,行代表每个样本,列代表每个特征
- 这里有9个样本,每个样本有4个特征
这是scikit-learn模型训练输入的标准格式
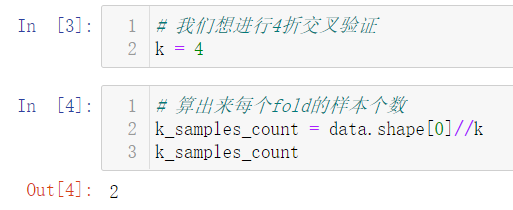
2. 使用Numpy实现K次划分
for fold in range(k):
validation_begin = k_samples_count*fold
validation_end = k_samples_count*(fold+1) validation_data = data[validation_begin:validation_end] # np.vstack,沿着垂直的方向堆叠数组
train_data = np.vstack([
data[:validation_begin],
data[validation_end:]
]) print()
print(f"#####第{fold}折#####")
print("验证集:\n", validation_data)
print("训练集:\n", train_data)
结果:
#####第0折#####
验证集:
[[0 1 2 3]
[4 5 6 7]]
训练集:
[[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]
[32 33 34 35]] #####第1折#####
验证集:
[[ 8 9 10 11]
[12 13 14 15]]
训练集:
[[ 0 1 2 3]
[ 4 5 6 7]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]
[32 33 34 35]] #####第2折#####
验证集:
[[16 17 18 19]
[20 21 22 23]]
训练集:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[24 25 26 27]
[28 29 30 31]
[32 33 34 35]] #####第3折#####
验证集:
[[24 25 26 27]
[28 29 30 31]]
训练集:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[32 33 34 35]]
如果使用scikit-learn,已经有封装好的实现:
from sklearn.model_selection import cross_val_score
Numpy实现机器学习交叉验证的数据划分的更多相关文章
- 机器学习——交叉验证,GridSearchCV,岭回归
0.交叉验证 交叉验证的基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set) ...
- 机器学习 - 案例 - 样本不均衡数据分析 - 信用卡诈骗 ( 标准化处理, 数据不均处理, 交叉验证, 评估, Recall值, 混淆矩阵, 阈值 )
案例背景 银行评判用户的信用考量规避信用卡诈骗 ▒ 数据 数据共有 31 个特征, 为了安全起见数据已经向了模糊化处理无法读出真实信息目标 其中数据中的 class 特征标识为是否正常用户 (0 代表 ...
- 机器学习中的train valid test以及交叉验证
转自 https://www.cnblogs.com/rainsoul/p/6373385.html 在以前的网络训练中,有关于验证集一直比较疑惑,在一些机器学习的教程中,都会提到,将数据集分为三部分 ...
- 机器学习基础:(Python)训练集测试集分割与交叉验证
在上一篇关于Python中的线性回归的文章之后,我想再写一篇关于训练测试分割和交叉验证的文章.在数据科学和数据分析领域中,这两个概念经常被用作防止或最小化过度拟合的工具.我会解释当使用统计模型时,通常 ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | model selection and training/validation/test sets(模型选择以及训练集、交叉验证集和测试集的概念)
怎样选用正确的特征构造学习算法或者如何选择学习算法中的正则化参数lambda?这些问题我们称之为模型选择问题. 在对于这一问题的讨论中,我们不仅将数据分为:训练集和测试集,而是将数据分为三个数据组:也 ...
- Spark机器学习——模型选择与参数调优之交叉验证
spark 模型选择与超参调优 机器学习可以简单的归纳为 通过数据训练y = f(x) 的过程,因此定义完训练模型之后,就需要考虑如何选择最终我们认为最优的模型. 如何选择最优的模型,就是本篇的主要内 ...
- Spark2.0机器学习系列之2:基于Pipeline、交叉验证、ParamMap的模型选择和超参数调优
Spark中的CrossValidation Spark中采用是k折交叉验证 (k-fold cross validation).举个例子,例如10折交叉验证(10-fold cross valida ...
- 机器学习--K折交叉验证和非负矩阵分解
1.交叉验证 交叉验证(Cross validation),交叉验证用于防止模型过于复杂而引起的过拟合.有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法. 于是可以先在一个子集上做 ...
- 机器学习 数据量不足问题----1 做好特征工程 2 不要用太多的特征 3 做好交叉验证 使用线性svm
来自:https://www.zhihu.com/question/35649122 其实这里所说的数据量不足,可以换一种方式去理解:在维度高的情况下,数据相对少.举一个特例,比如只有一维,和1万个数 ...
随机推荐
- Linux实时查看日志的四种命令详解
转至:https://blog.csdn.net/qq_33223299/article/details/93773989 如何在Linux中实时查看日志文件的内容?那么有很多实用程序可以帮助用户在文 ...
- python面试_总结04_字符串练习题
完成下列列表相关的编程题,先运行下列的test函数,在完成每道题之后,都可以通过调用test函数检测所写函数对错 def test(got, expected): if got == expected ...
- rocketmq常见问题
rocketmq常见问题 以下是关于RocketMQ项目的常见问题 使用 「新创建的Consumer ID从哪里开始消费消息?」 1)如果发送的消息在三天之内,那么消费者会从服务器中保存的第一条消息开 ...
- VirtualBox虚拟机--桥接模式
问题概述:VirtualBox虚拟机设置桥接模式,与宿主机互相ping通. 注:如果按照以下方式设置了还是ping不通,查看虚拟机防火墙是否已关. 公司电脑拿去维修了,在自己家里电脑上部署项目开发环境 ...
- [k8s] k8s基于csi使用rbd存储
描述 ceph-csi扩展各种存储类型的卷的管理能力,实现第三方存储ceph的各种操作能力与k8s存储系统的结合.通过 ceph-csi 使用 ceph rbd块设备,它动态地提供rbd以支持 Kub ...
- winform中更新UI控件的方案介绍
这是一个古老的话题...直入主题吧! 对winfrom的控件来说,多线程操作非常容易导致复杂且严重的bug,比如不同线程可能会因场景需要强制设置控件为不同的状态,进而引起并发.加锁.死锁.阻塞等问题. ...
- Kendo UI Grid 批量编辑使用总结
项目中使用Kendo UI Grid控件实现批量编辑,现在将用到的功能总结一下. 批量编辑基本设置 Kendo Grid的设置方法如下: $("#grid").kendoGrid( ...
- 基于AE的基础的GIS系统的开发
一个GIS系统需要的基本功能的代码 一些基本的拖拽操作就不讲了,直接上代码吧. 1. 打开.mxd文件 基本思路:判断mxd路径存在→打开mxd文件 string filename = Appli ...
- django处理跨域
django处理Ajax跨域访问时使用javascript进行ajax访问的时候,出现如下错误 出错原因:javascript处于安全考虑,不允许跨域访问.下图是对跨域访问的解释: 概念: 这里说的j ...
- Pyinstaller打包Pytorch框架所遇到的问题
目录 前言 基本流程 一.安装Pyinstaller 和 测试Hello World 二.打包整个项目,在本机上调试生成exe 三.在新电脑上测试 参考资料 前言 第一次尝试用Pyinstalle ...