「学习笔记」重修 FHQ-treap
无旋 treap 的操作方式使得它天生支持维护序列、可持久化等特性。
无旋 treap 又称分裂合并 treap。它仅有两种核心操作,即为 分裂 与 合并。通过这两种操作,在很多情况下可以比旋转 treap 更方便的实现别的操作。
变量与宏定义
#define ls ch[u][0]
#define rs ch[u][1]
int cnt, rt, top;
int ch[N][2], siz[N], val[N], pai[N], rub[N];
ls: 左孩子;
rs: 右孩子;
cnt: 计数器;
rt: 根;
top: “垃圾桶”的栈顶
ch: 左右孩子,0 为左孩子,1 为右孩子;
siz: 子树大小;
val: 键值;
pai:随机的值,用于堆排序;
rub: 垃圾桶。
操作
按权值分裂
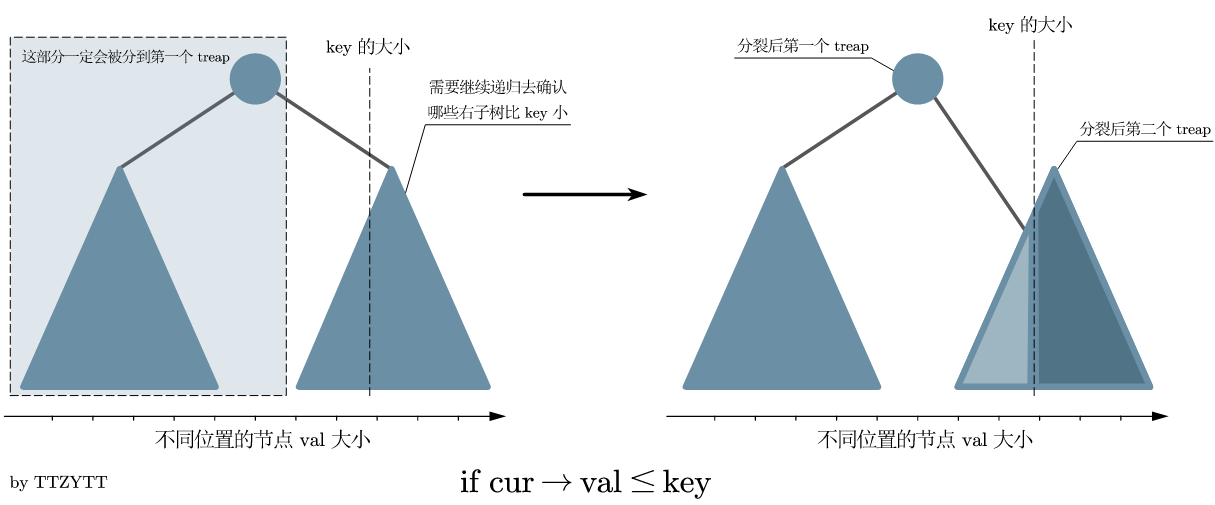
给定一个权值,小于等于该权值的分裂到左边,大于该权值的分裂到右边。
在分裂过程中也要维护二叉搜索树的性质,即当前节点左子树任意一个节点的 val 都小于等于当前节点的 val,右子树任意一个节点的 val 都大于当前节点的 val。
void split1(int u, int c, int &x, int &y) { // 按照权值分裂
if (u == 0) {
x = y = 0;
return ;
}
if (val[u] <= c) {
x = u;
split1(rs, c, rs, y);
}
else {
y = u;
split1(ls, c, x, ls);
}
pushup(u);
}
u: 当前节点;
c: 给定分裂的权值;
x: 要分裂成的左树;
y: 要分裂成的右树。
if (val[u] <= v) {
x = u;
split1(rs, c, rs, y);
}
如果当前节点的 val 小于 \(c\),那么久把当前节点连带它的左子树一起放到 x 上,接下来向右子树搜索,若还有要接到 x 上的节点,就接到 x 的右子树上,以此来维护二叉搜索树的性质。如下图(图片来自 \(\text{OI wiki}\))。
pushup(u); 为更新函数,后面会写。
按子树大小分裂
将前 \(k\) 个节点分成一棵树,其他节点分成一棵树。
void split2(int u, int k, int &x, int &y) { // 按照子树大小分裂
if (u == 0) {
x = y = 0;
return ;
}
pushup(u);
if (siz[ls] + 1 <= k) {
x = u;
split2(rs, k - siz[ls] - 1, rs, y);
}
else {
y = u;
split2(ls, k, x, ls);
}
pushup(u);
}
if (siz[ls] + 1 <= k) {
x = u;
split2(rs, k - siz[ls] - 1, rs, y);
}
siz[ls] + 1 是当前的节点和它的左子树的总 siz,siz 小于 \(k\),放到左子树,x 变成 rs。
合并
两棵树合并,如果一棵树为空,则直接合并,否则,根据 pai 的大小来判断谁是父节点。
小根堆 pai 小的为父节点,大根堆 pai 大的为父节点。
int merge(int x, int y) {
if (!x || !y) {
return x + y;
}
if (pai[x] < pai[y]) {
ch[x][1] = merge(ch[x][1], y);
pushup(x);
return x;
}
else {
ch[y][0] = merge(x, ch[y][0]);
pushup(y);
return y;
}
}
注意,合并时 x 是左树,y 是右树,一定要保证左右顺序!
更新信息
void pushup(int u) {
siz[u] = siz[ls] + siz[rs] + 1;
return ;
}
删除节点
这里是删除已知权值的点,若存在多个则只删一个,删除的点将放进“垃圾桶”,当有些节点要创建时先从“垃圾桶”里找可用的点,节省空间。
void del(int c) {
int t1, t2, t3;
split1(rt, c, t1, t2);
split1(t1, c - 1, t1, t3);
rub[++ top] = t3;
t3 = merge(ch[t3][0], ch[t3][1]);
rt = merge(merge(t1, t3), t2);
}
t3 = merge(ch[t3][0], ch[t3][1]);
rt = merge(merge(t1, t3), t2);
由于相同权值的节点只删了一个,t3 可能不为空,所以还要再合并起来.
创建新节点
int New(int c) {
int u;
if (!top) {
u = ++ cnt;
}
else {
u = rub[top];
top --;
}
val[u] = c;
siz[u] = 1;
pai[u] = rand();
ls = 0, rs = 0;
return u;
}
if (!top) {
u = ++ cnt;
}
else {
u = rub[top];
top --;
}
如果“垃圾桶”里还有点,那就将这些点回收利用,否则就开新节点。
插入
先将树按照权值分裂,然后将新节点依次与左树和右树合并,merge 的顺序不要搞反了。
void insert(int c) {
int t1, t2;
split1(rt, c, t1, t2);
rt = merge(merge(t1, New(c)), t2);
}
查询排名
按照权值分裂,返回 siz[ls] + 1。
int ranking(int c) {
int t1, t2, k;
split1(rt, c - 1, t1, t2);
k = siz[t1] + 1;
rt = merge(t1, t2);
return k;
}
查询第 \(K\) 大
按照子树大小分裂即可
int K_th(int k) {
int t1, t2, t3, c;
split2(rt, k, t1, t2);
split2(t1, k - 1, t1, t3);
c = val[t3];
rt = merge(merge(t1, t3), t2);
return c;
}
查找前驱
int pre(int c) {
int t1, t2, t3, k;
split1(rt, c - 1, t1, t2);
split2(t1, siz[t1] - 1, t1, t3);
k = val[t3];
rt = merge(merge(t1, t3), t2);
return k;
}
查找后继
int nxt(int c) {
int t1, t2, t3, k;
split1(rt, c, t1, t2);
split2(t2, 1, t2, t3);
k = val[t2];
rt = merge(t1, merge(t2, t3));
return k;
}
由于 FHQ 的核心操作是分裂与合并,所以,不同于 treap,它可以方便的进行区间操作。
模板
struct FHQ {
int cnt, rt, top;
int ch[N][2], siz[N], val[N], pai[N], rub[N];
void pushup(int u) {
siz[u] = siz[ls] + siz[rs] + 1;
return ;
}
int New(int c) {
int u;
if (!top) {
u = ++ cnt;
}
else {
u = rub[top];
top --;
}
val[u] = c;
siz[u] = 1;
pai[u] = rand();
ls = 0, rs = 0;
return u;
}
void split1(int u, int c, int &x, int &y) { // 按照权值分裂
if (u == 0) {
x = y = 0;
return ;
}
if (val[u] <= c) {
x = u;
split1(rs, c, rs, y);
}
else {
y = u;
split1(ls, c, x, ls);
}
pushup(u);
}
void split2(int u, int k, int &x, int &y) { // 按照子树大小分裂
if (u == 0) {
x = y = 0;
return ;
}
pushup(u);
if (siz[ls] + 1 <= k) {
x = u;
split2(rs, k - siz[ls] - 1, rs, y);
}
else {
y = u;
split2(ls, k, x, ls);
}
pushup(u);
}
int merge(int x, int y) {
if (!x || !y) {
return x + y;
}
if (pai[x] < pai[y]) {
ch[x][1] = merge(ch[x][1], y);
pushup(x);
return x;
}
else {
ch[y][0] = merge(x, ch[y][0]);
pushup(y);
return y;
}
}
void insert(int c) {
int t1, t2;
split1(rt, c, t1, t2);
rt = merge(merge(t1, New(c)), t2);
}
void del(int c) {
int t1, t2, t3;
split1(rt, c, t1, t2);
split1(t1, c - 1, t1, t3);
rub[++ top] = t3;
t3 = merge(ch[t3][0], ch[t3][1]);
rt = merge(merge(t1, t3), t2);
}
int ranking(int c) {
int t1, t2, k;
split1(rt, c - 1, t1, t2);
k = siz[t1] + 1;
rt = merge(t1, t2);
return k;
}
int K_th(int k) {
int t1, t2, t3, c;
split2(rt, k, t1, t2);
split2(t1, k - 1, t1, t3);
c = val[t3];
rt = merge(merge(t1, t3), t2);
return c;
}
int pre(int c) {
int t1, t2, t3, k;
split1(rt, c - 1, t1, t2);
split2(t1, siz[t1] - 1, t1, t3);
k = val[t3];
rt = merge(merge(t1, t3), t2);
return k;
}
int nxt(int c) {
int t1, t2, t3, k;
split1(rt, c, t1, t2);
split2(t2, 1, t2, t3);
k = val[t2];
rt = merge(t1, merge(t2, t3));
return k;
}
};
「学习笔记」重修 FHQ-treap的更多相关文章
- 「学习笔记」Treap
「学习笔记」Treap 前言 什么是 Treap ? 二叉搜索树 (Binary Search Tree/Binary Sort Tree/BST) 基础定义 查找元素 插入元素 删除元素 查找后继 ...
- 「学习笔记」Min25筛
「学习笔记」Min25筛 前言 周指导今天模拟赛五分钟秒第一题,十分钟说第二题是 \(\text{Min25}\) 筛板子题,要不是第三题出题人数据范围给错了,周指导十五分钟就 \(\text{AK ...
- 「学习笔记」FFT 之优化——NTT
目录 「学习笔记」FFT 之优化--NTT 前言 引入 快速数论变换--NTT 一些引申问题及解决方法 三模数 NTT 拆系数 FFT (MTT) 「学习笔记」FFT 之优化--NTT 前言 \(NT ...
- 「学习笔记」FFT 快速傅里叶变换
目录 「学习笔记」FFT 快速傅里叶变换 啥是 FFT 呀?它可以干什么? 必备芝士 点值表示 复数 傅立叶正变换 傅里叶逆变换 FFT 的代码实现 还会有的 NTT 和三模数 NTT... 「学习笔 ...
- 「学习笔记」字符串基础:Hash,KMP与Trie
「学习笔记」字符串基础:Hash,KMP与Trie 点击查看目录 目录 「学习笔记」字符串基础:Hash,KMP与Trie Hash 算法 代码 KMP 算法 前置知识:\(\text{Border} ...
- 「学习笔记」 FHQ Treap
FHQ Treap FHQ Treap (%%%发明者范浩强年年NOI金牌)是一种神奇的数据结构,也叫非旋Treap,它不像Treap zig zag搞不清楚(所以叫非旋嘛),也不像Splay完全看不 ...
- 「学习笔记」wqs二分/dp凸优化
[学习笔记]wqs二分/DP凸优化 从一个经典问题谈起: 有一个长度为 \(n\) 的序列 \(a\),要求找出恰好 \(k\) 个不相交的连续子序列,使得这 \(k\) 个序列的和最大 \(1 \l ...
- 「学习笔记」珂朵莉树 ODT
珂朵莉树,也叫ODT(Old Driver Tree 老司机树) 从前有一天,珂朵莉出现了... 然后有一天,珂朵莉树出现了... 看看图片的地址 Codeforces可还行) 没错,珂朵莉树来自Co ...
- 「学习笔记」ST表
问题引入 先让我们看一个简单的问题,有N个元素,Q次操作,每次操作需要求出一段区间内的最大/小值. 这就是著名的RMQ问题. RMQ问题的解法有很多,如线段树.单调队列(某些情况下).ST表等.这里主 ...
- 「学习笔记」递推 & 递归
引入 假设我们想计算 \(f(x) = x!\).除了简单的 for 循环,我们也可以使用递归. 递归是什么意思呢?我们可以把 \(f(x)\) 用 \(f(x - 1)\) 表示,即 \(f(x) ...
随机推荐
- cvs 常见命令
一.cvs上传一个新的工程到server 假如上传目录test到xxxx_project下1. copy test到xxxx_project2. 删除test目录及子目录下的CVS目录3. 在xxxx ...
- java 进程排查
[admin@New-OperSys-01 ~]$ jstack $pid | grep -A 50 55e7 "GC task thread#1 (ParallelGC)" os ...
- Matlab:4维、单目标、约束、粒子群优化算法
% 主调用函数(求最大值) clc; clear; close all; % 初始化种群 N = 100; % 初始种群个数 D = 4; % 空间维数 iter = 50; % 迭代次数 x_lim ...
- loadrunner获取时间戳
web_save_timestamp_param("tStamp", LAST); //取时间戳
- pandas加速读取数据记录csv大文件处理
def readf(file): t0 = time.time() data=pd.read_csv(file,low_memory=False,encoding='gbk' #,nrows=100 ...
- MIUI 12.5稳定版关闭充电提示音的方法
手机开启开发中模式 将手机连接电脑 打开cmd, 输入命令:adb shell settings put global power_sounds_enabled 0,即可关闭充电时的提示音 输入命令: ...
- 实验五:开源控制器实践——POX
基本要求 1.tcpdump 验证Hub模块 h1 ping h2的tcpdump抓包结果截图 h1 ping h3的tcpdump抓包结果截图 2.tcpdump 验证Switch模块 h1 pin ...
- 错误:为仓库 'appstream' 下载元数据失败 : Cannot prepare internal mirrorlist: No URLs in mirrorlist
sudo sed -i -e "s|mirrorlist=|#mirrorlist=|g" /etc/yum.repos.d/CentOS-* sudo sed -i -e &qu ...
- LaTeX in 24 Hours - 2. Fonts Selection
文章目录 本章内容:字体 2.1 Text-Mode Fonts 2.2 Math-Mode Fonts 2.3 Emphasized Fonts 2.4 Colored Fonts 其他章节目录: ...
- django+ajax实现xlsx文件下载功能
前端代码 $("#id_pullout").click(function () { //发送ajax请求 $.ajax({ url: '/pullout/', //请求的url m ...