Vicinity Vision Transformer概述
0.前言
1.针对的问题
视觉transformer计算复杂度和内存占用都是二次的,这主要是softmax归一化导致的,这使其无法处理高分辨率图像或细粒度图像patch。
2.主要贡献
(1)提出了一种新的线性视觉自注意模型,该模型在线性视觉transformer中引入了基于二维曼哈顿距离的局部性偏差。
(2)提出了一种新的多头自注意模块——邻近注意块,以实现邻近注意所需的假设。该算法包含特征缩减注意力(feature reduction attention, FRA)模块和特征保持连接(feature preserving connection, FPC)模块,以控制计算开销和提高特征提取能力。
(3)构造了邻近视觉Transformer(Vicinity Vision Transformer, VVT),它作为通用的视觉骨干,易于应用于视觉任务。大量的实验验证了VVT在各种计算机视觉基准上的有效性。
3.方法
1.将softmax替换成一个与序列长度N成线性关系的函数,具体来说就是把相似度函数softmax换成一个可分解的相似度函数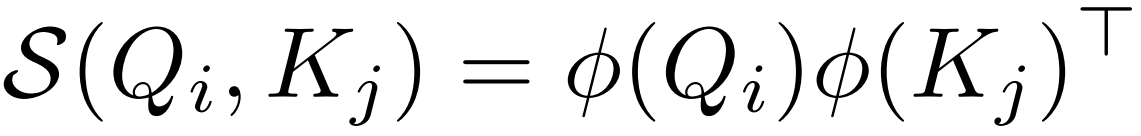 ,找到一个核函数φ(ReLU),使得先算注意力矩阵A=
,找到一个核函数φ(ReLU),使得先算注意力矩阵A=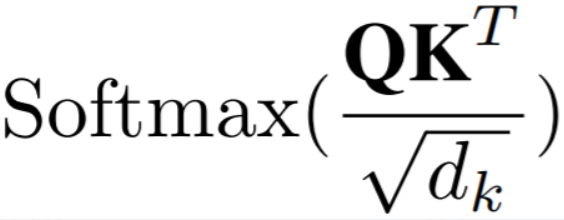 ∈RN×N变为先算φ(K)TV∈Rd×d。2.使序列长度N远大于特征维数。3.利用曼哈顿距离加入局部性偏置。
∈RN×N变为先算φ(K)TV∈Rd×d。2.使序列长度N远大于特征维数。3.利用曼哈顿距离加入局部性偏置。
在NLP领域出现了很多将自注意力进行分解以将其计算复杂度降低为线性的方法,但是这些方法在视觉领域效果不好,作者经过研究认为局部性偏置对于视觉来说是一个很重要的性质,所以作者提出基于相邻图像块测量的二维曼哈顿距离,对每个图像块调整其注意力权重,在这种情况下,相邻的patch会比距离较远的patch获得更强的注意力。也就是论文中的re-weighting机制。
线性化可以通过选取一个可分解的相似函数S(·)来满足来实现,其中φ(·)为核函数。给定这样一个核函数,可以将self-attention模块的输出写为:
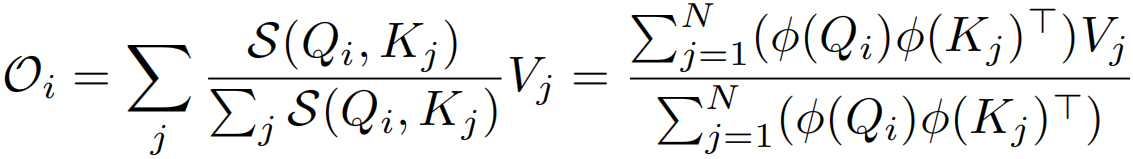
标准自注意力中相似度函数S(·)是softmax函数,输出O=Att(x)=AV,A∈RN×N,时空复杂度关于N都是二次,现在不计算注意力矩阵A∈RN×N,而是先计算φ(K)TV∈Rd×d,即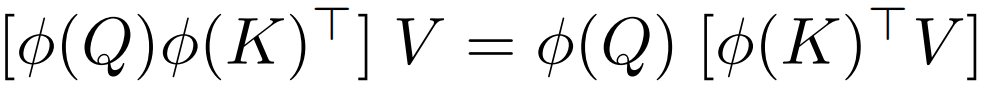 ,使O(N2d)运算转换为O(Nd2)运算
,使O(N2d)运算转换为O(Nd2)运算
softmax归一化是自注意力算法二次复杂度的根源。线性化的关键在于用另一个相似度函数代替标准的softmax操作。
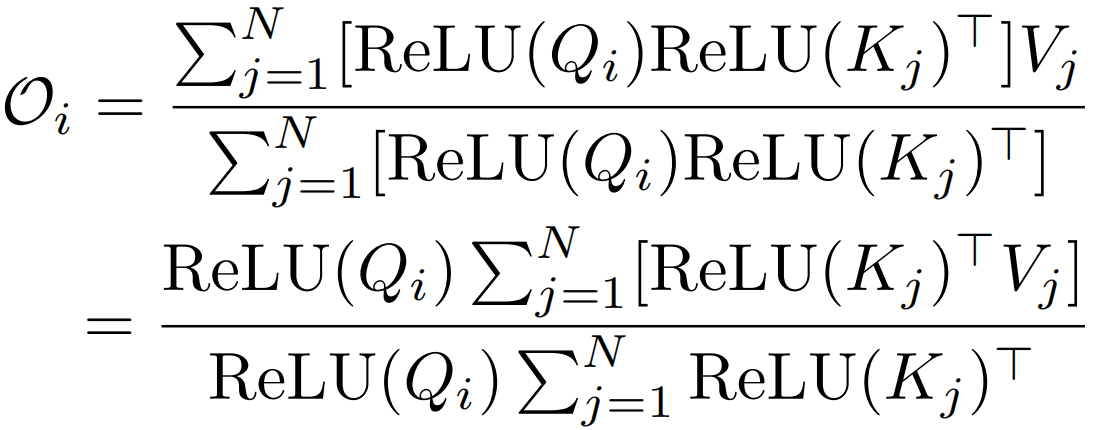
这种方法与序列长度N成线性关系。且保留了标准自注意的两个重要特性:(1)它始终是正的,避免了负相关信息的聚集。(2)所有元素都位于[0,1]之间。
此外,还需要加入局部性偏置,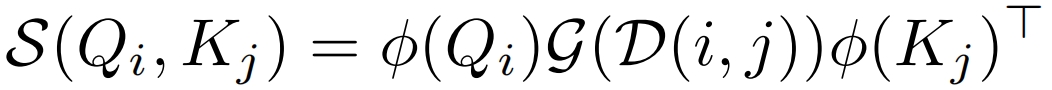 ,G生产距离权重。这里的G不能直接使用欧几里得距离
,G生产距离权重。这里的G不能直接使用欧几里得距离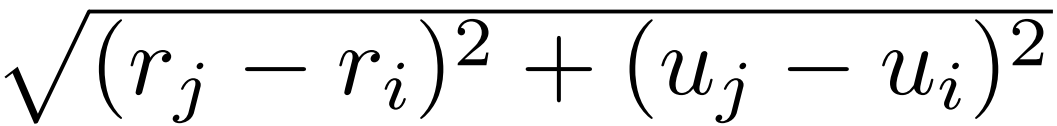 ,因为其不能分解为关于i和j的两项,这里用qi和kj分别代表来自Q和K的一个token,u表示在2D特征图的第几行,r代表列。2D曼哈顿距离虽然可以很容易地解耦到两个方向,
,因为其不能分解为关于i和j的两项,这里用qi和kj分别代表来自Q和K的一个token,u表示在2D特征图的第几行,r代表列。2D曼哈顿距离虽然可以很容易地解耦到两个方向,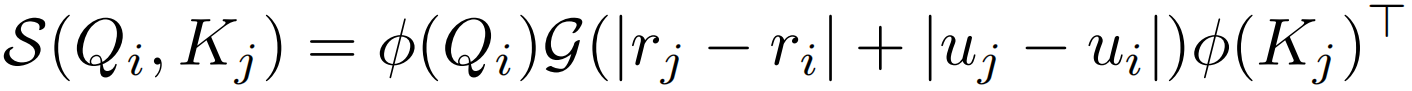 但是绝对值操作依旧无法分解。这里作者假设给定大小为m×n的特征图,通过下面两个等式得到一个可分解的相似度函数S(Qi,Kj)。
但是绝对值操作依旧无法分解。这里作者假设给定大小为m×n的特征图,通过下面两个等式得到一个可分解的相似度函数S(Qi,Kj)。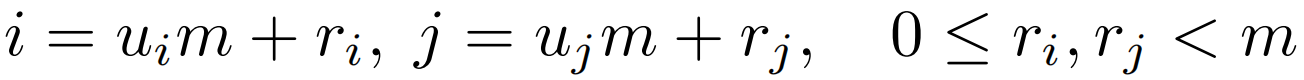
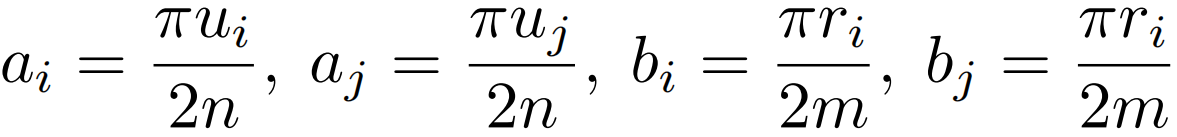
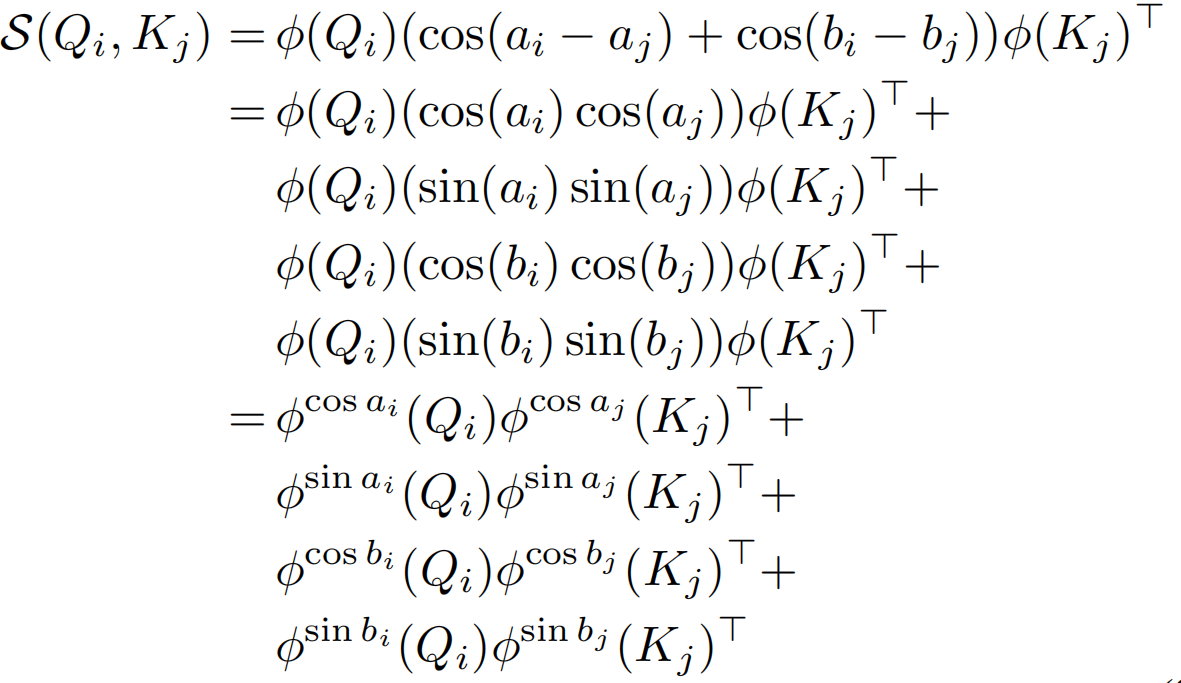
标准自注意力与线性自注意力对比如下:
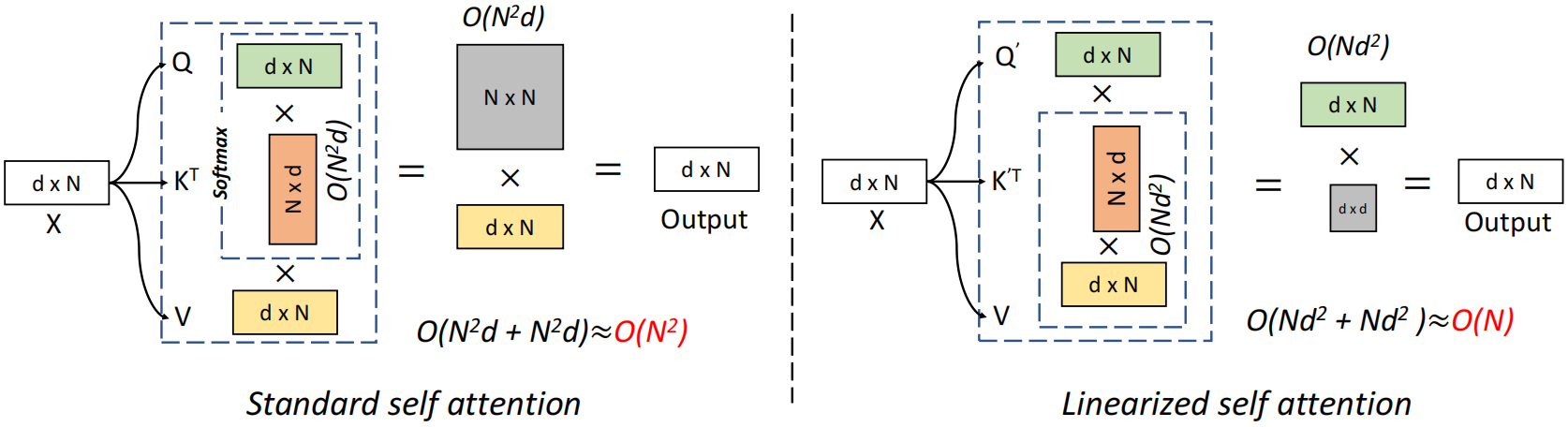
此外,与基于vanilla transformer的方法相比,当序列长度远大于特征维数时,邻近注意力算法表现出效率优势。为了满足这一要求,本文提出了一种新的邻近注意力块,在不牺牲性能的前提下降低了特征维数。包括一个特征缩减注意力(Feature Reduction Attention, RFA)模块和一个特征保持连接(Feature Preserving Connection, FRC)模块,RFA模块将输入特征维数降低一半,FRC模块恢复原始特征分布并增强表示能力。最后采用金字塔结构的邻近注意力块构造了一个名为邻近视觉Transformer(Vicinity Vision Transformer, VVT)的骨干网络。
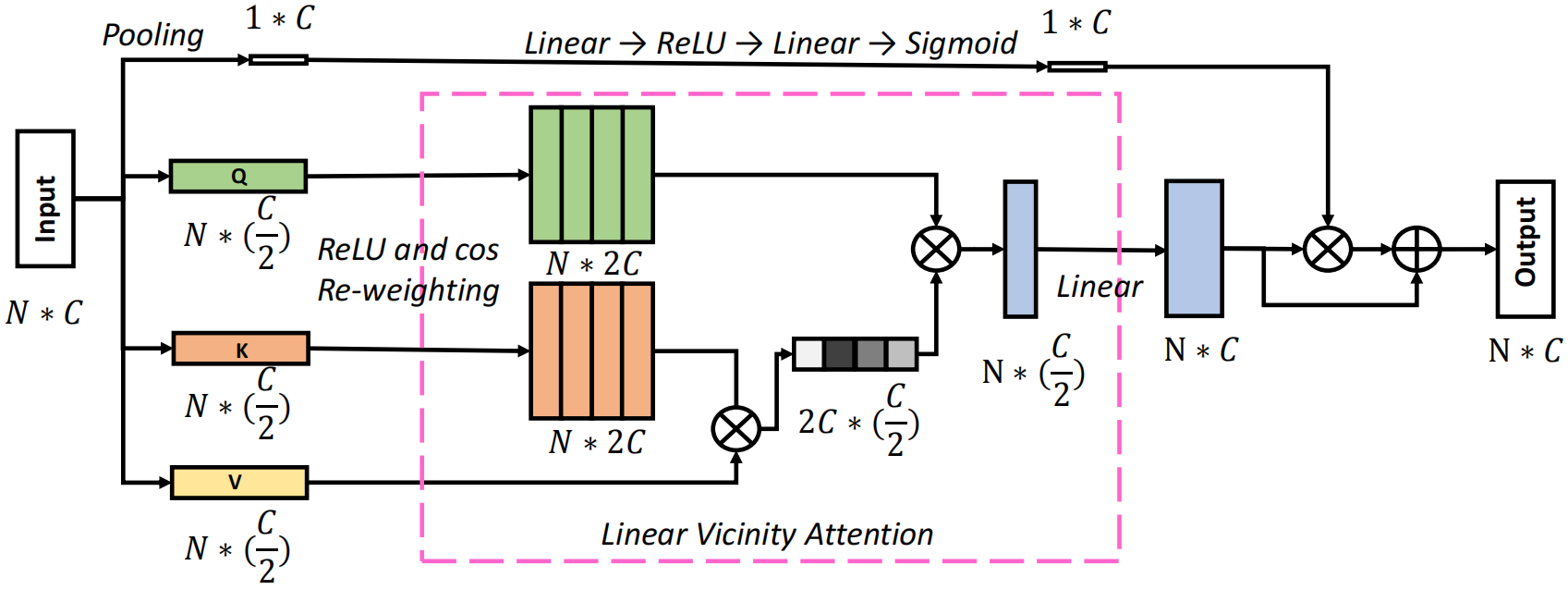
输入X∈RN×d,通过FRA模块将其投影成Q∈RN×d/2, K∈RN×2/d, V∈RN×2/d,并降低了特征维数。然后通过局部分解和re-weighting得到Q'∈ RN×2d, K'∈ RN×2d用于计算线性自注意力,由于自注意力是在更低的维度计算的,在上面添加了一个叫做FRC的跳跃连接,包括一个平均池化操作和两个线性层来保持原始特征分布并增强表示能力。
得到的最终骨干网络如下:
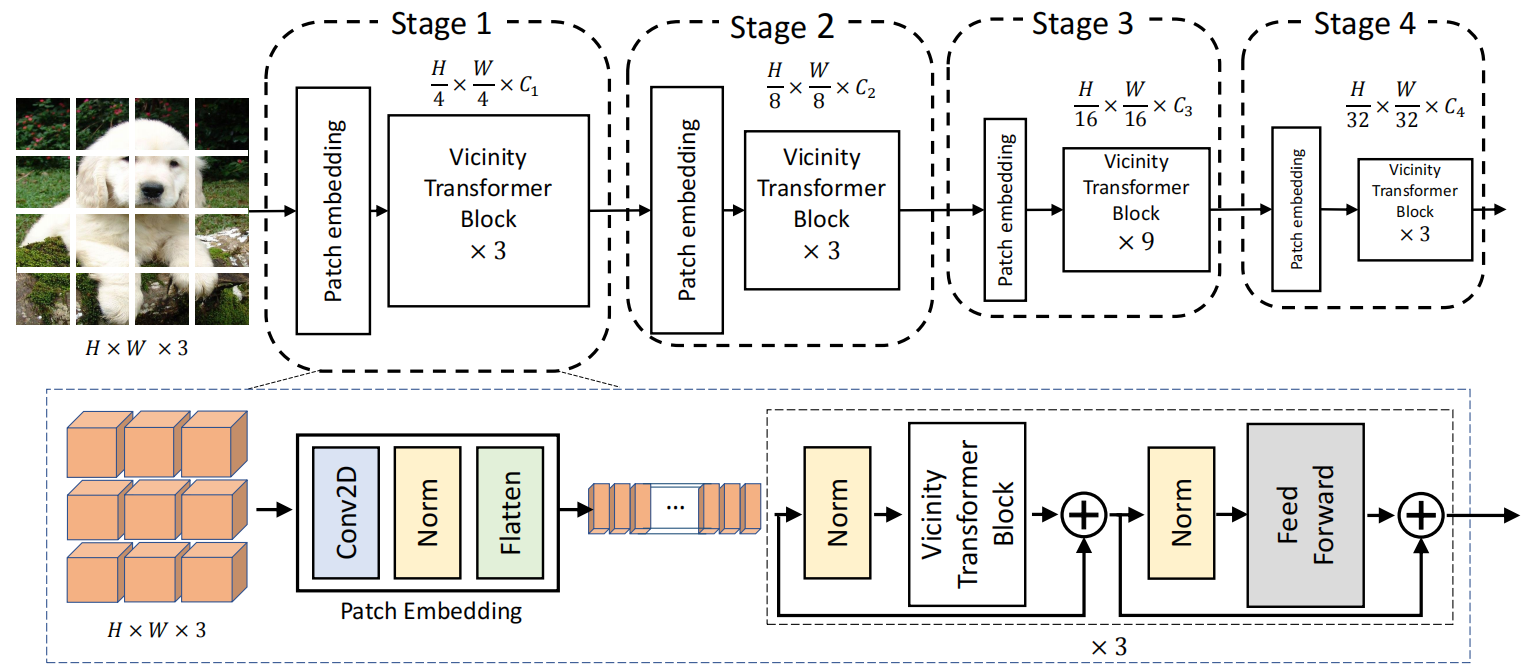
采用渐进式收缩金字塔结构,有四个阶段,生成不同的尺度的特征图。每个阶段包含一个patch embedding层和多个Vicinity Transformer块。
Vicinity Vision Transformer概述的更多相关文章
- ICCV2021 | Vision Transformer中相对位置编码的反思与改进
前言 在计算机视觉中,相对位置编码的有效性还没有得到很好的研究,甚至仍然存在争议,本文分析了相对位置编码中的几个关键因素,提出了一种新的针对2D图像的相对位置编码方法,称为图像RPE(IRPE). ...
- ICCV2021 | 渐进采样式Vision Transformer
前言 ViT通过简单地将图像分割成固定长度的tokens,并使用transformer来学习这些tokens之间的关系.tokens化可能会破坏对象结构,将网格分配给背景等不感兴趣的区域,并引 ...
- ICCV2021 | Tokens-to-Token ViT:在ImageNet上从零训练Vision Transformer
前言 本文介绍一种新的tokens-to-token Vision Transformer(T2T-ViT),T2T-ViT将原始ViT的参数数量和MAC减少了一半,同时在ImageNet上从 ...
- VIT Vision Transformer | 先从PyTorch代码了解
文章原创自:微信公众号「机器学习炼丹术」 作者:炼丹兄 联系方式:微信cyx645016617 代码来自github [前言]:看代码的时候,也许会不理解VIT中各种组件的含义,但是这个文章的目的是了 ...
- vision transformer
VIT 总览 Step1 Step2
- ICCV2021 | TransFER:使用Transformer学习关系感知的面部表情表征
前言 人脸表情识别(FER)在计算机视觉领域受到越来越多的关注.本文介绍了一篇在人脸表情识别方向上使用Transformer来学习关系感知的ICCV2021论文,论文提出了一个TransFER ...
- ICCV2021 | PnP-DETR:用Transformer进行高效的视觉分析
前言 DETR首创了使用transformer解决视觉任务的方法,它直接将图像特征图转化为目标检测结果.尽管很有效,但由于在某些区域(如背景)上进行冗余计算,输入完整的feature maps ...
- ICCV2021 | Swin Transformer: 使用移位窗口的分层视觉Transformer
前言 本文解读的论文是ICCV2021中的最佳论文,在短短几个月内,google scholar上有388引用次数,github上有6.1k star. 本文来自公众号CV技术指南的论文分享系 ...
- ICCV2021 | SOTR:使用transformer分割物体
前言 本文介绍了现有实例分割方法的一些缺陷,以及transformer用于实例分割的困难,提出了一个基于transformer的高质量实例分割模型SOTR. 经实验表明,SOTR不仅为实例分割提供了 ...
- ICCV2021 | 用于视觉跟踪的学习时空型transformer
前言 本文介绍了一个端到端的用于视觉跟踪的transformer模型,它能够捕获视频序列中空间和时间信息的全局特征依赖关系.在五个具有挑战性的短期和长期基准上实现了SOTA性能,具有实时性,比 ...
随机推荐
- uniapp微信小程序返回上一页并刷新数据
根据要求:详情页返回列表页时,要刷新列表页的数据,操作如下 @click="goBack" goBack{ let pages = getCurrentPages(); // 当前 ...
- Vue前后端分离实现登录的一个简单demo
1.建立一个Maven项目,并添加Spring相关依赖 2.编写Controller类相应的接口和配置类 LoginController类,编写接口的业务逻辑 package com.springbo ...
- CVE-2022-26923 Windows域提权漏洞
前言 Active Directory 域服务,是一种目录服务,提供了存储目录数据信息以及用户相关的一些密码,电话号码等等一些数据信息,且可让用户和管理员使用这些数据,有利于域管理员对用户的数据信息进 ...
- [剑指Offer]3.数组中重复的数字
题目 找出数组中重复的数字. 在一个长度为n的数组中的所有数字都在0~n-1的范围内.数组中某些数字是重复的,但是不知道有几个数字重复了,也不知道每个数字重复了几次.请找出数组中任意一个重复的数组.例 ...
- ResourceQuota与LimitRange区别
ResourceQuota与LimitRange区别 ResourceQuota ResourceQuota 用来限制 namespace 中所有的 Pod 占用的总的资源 request 和 lim ...
- Django推导流程,Django模块的下载和基本使用、Django的应用和目录结构讲解、Django三板斧
今日内容 纯手撸web框架 1.web框架的本质: 理解1:连接前端与数据库的中间介质 理解2:socket服务端 2.手写web框架: 1.编写socket服务端代码 import socket s ...
- Codeforces Round #846 (Div. 2) A-E
比赛链接 A 题意 给 \(n\) 个正整数,找到三个数,使得他们的和为奇数,输出他们的下标. 题解 知识点:贪心. 找到三个奇数或者一个奇数两个偶数即可,其他情况无解. 时间复杂度 \(O(n)\) ...
- Java 进阶P-3.5+P-3.6
对象数组的for-each循环 for-each是用于遍历数组的另一种形式的for循环.for-each循环显着减少了代码,并且循环中没有使用索引或计数器. 句法: For(<数组/列表的数据类 ...
- 行为型模式 - 责任链模式Chain of Responsibility
我就想知道我又哪里有广告植入了,告诉我. 学习而来,代码是自己敲的.也有些自己的理解在里边,有问题希望大家指出. 模式的定义与特点 责任链(Chain of Responsibility)模式的定义: ...
- git 拉取github项目失败(超时)
问题 通过git拉取GitHub上的项目失败报错信息如下 fetch-pack: unexpected disconnect while reading sideband packet fatal: ...