Vicinity Vision Transformer概述
0.前言
1.针对的问题
视觉transformer计算复杂度和内存占用都是二次的,这主要是softmax归一化导致的,这使其无法处理高分辨率图像或细粒度图像patch。
2.主要贡献
(1)提出了一种新的线性视觉自注意模型,该模型在线性视觉transformer中引入了基于二维曼哈顿距离的局部性偏差。
(2)提出了一种新的多头自注意模块——邻近注意块,以实现邻近注意所需的假设。该算法包含特征缩减注意力(feature reduction attention, FRA)模块和特征保持连接(feature preserving connection, FPC)模块,以控制计算开销和提高特征提取能力。
(3)构造了邻近视觉Transformer(Vicinity Vision Transformer, VVT),它作为通用的视觉骨干,易于应用于视觉任务。大量的实验验证了VVT在各种计算机视觉基准上的有效性。
3.方法
1.将softmax替换成一个与序列长度N成线性关系的函数,具体来说就是把相似度函数softmax换成一个可分解的相似度函数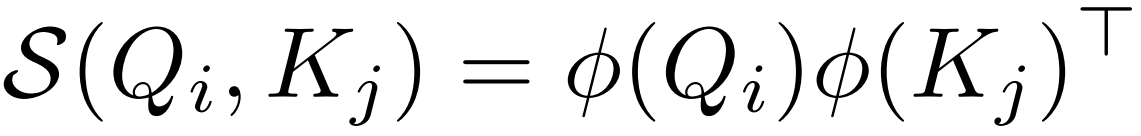 ,找到一个核函数φ(ReLU),使得先算注意力矩阵A=
,找到一个核函数φ(ReLU),使得先算注意力矩阵A=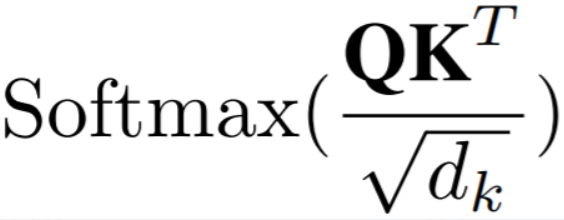 ∈RN×N变为先算φ(K)TV∈Rd×d。2.使序列长度N远大于特征维数。3.利用曼哈顿距离加入局部性偏置。
∈RN×N变为先算φ(K)TV∈Rd×d。2.使序列长度N远大于特征维数。3.利用曼哈顿距离加入局部性偏置。
在NLP领域出现了很多将自注意力进行分解以将其计算复杂度降低为线性的方法,但是这些方法在视觉领域效果不好,作者经过研究认为局部性偏置对于视觉来说是一个很重要的性质,所以作者提出基于相邻图像块测量的二维曼哈顿距离,对每个图像块调整其注意力权重,在这种情况下,相邻的patch会比距离较远的patch获得更强的注意力。也就是论文中的re-weighting机制。
线性化可以通过选取一个可分解的相似函数S(·)来满足来实现,其中φ(·)为核函数。给定这样一个核函数,可以将self-attention模块的输出写为:
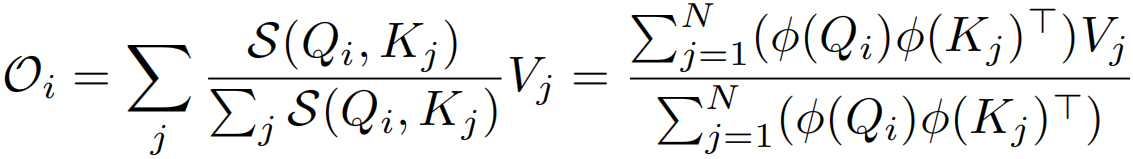
标准自注意力中相似度函数S(·)是softmax函数,输出O=Att(x)=AV,A∈RN×N,时空复杂度关于N都是二次,现在不计算注意力矩阵A∈RN×N,而是先计算φ(K)TV∈Rd×d,即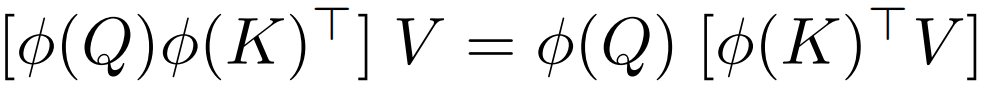 ,使O(N2d)运算转换为O(Nd2)运算
,使O(N2d)运算转换为O(Nd2)运算
softmax归一化是自注意力算法二次复杂度的根源。线性化的关键在于用另一个相似度函数代替标准的softmax操作。
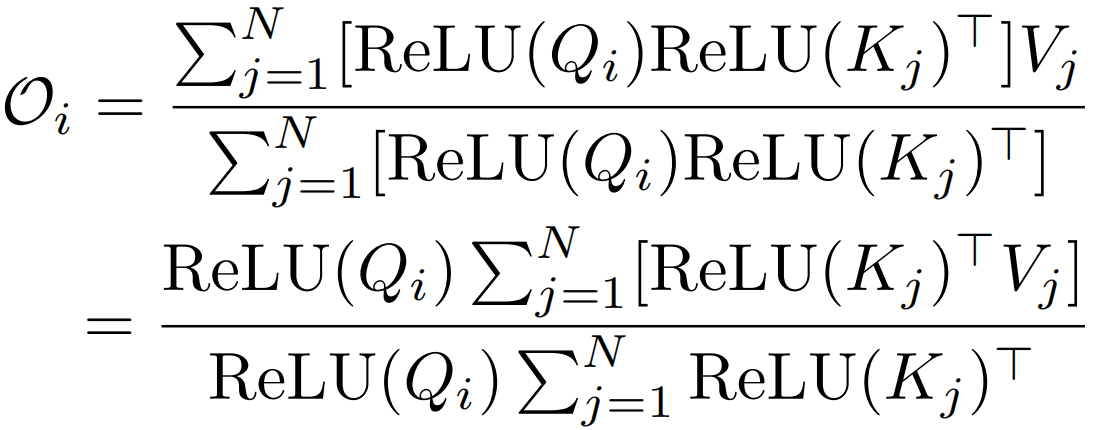
这种方法与序列长度N成线性关系。且保留了标准自注意的两个重要特性:(1)它始终是正的,避免了负相关信息的聚集。(2)所有元素都位于[0,1]之间。
此外,还需要加入局部性偏置,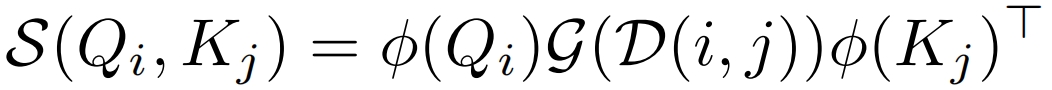 ,G生产距离权重。这里的G不能直接使用欧几里得距离
,G生产距离权重。这里的G不能直接使用欧几里得距离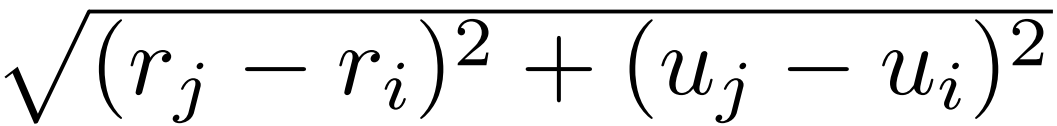 ,因为其不能分解为关于i和j的两项,这里用qi和kj分别代表来自Q和K的一个token,u表示在2D特征图的第几行,r代表列。2D曼哈顿距离虽然可以很容易地解耦到两个方向,
,因为其不能分解为关于i和j的两项,这里用qi和kj分别代表来自Q和K的一个token,u表示在2D特征图的第几行,r代表列。2D曼哈顿距离虽然可以很容易地解耦到两个方向,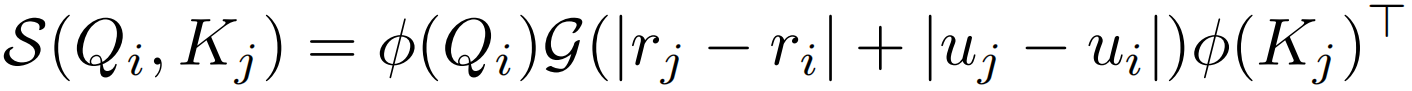 但是绝对值操作依旧无法分解。这里作者假设给定大小为m×n的特征图,通过下面两个等式得到一个可分解的相似度函数S(Qi,Kj)。
但是绝对值操作依旧无法分解。这里作者假设给定大小为m×n的特征图,通过下面两个等式得到一个可分解的相似度函数S(Qi,Kj)。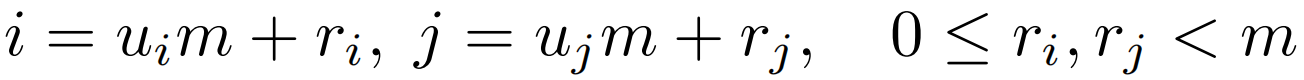
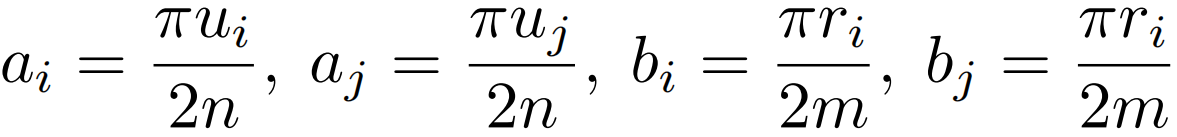
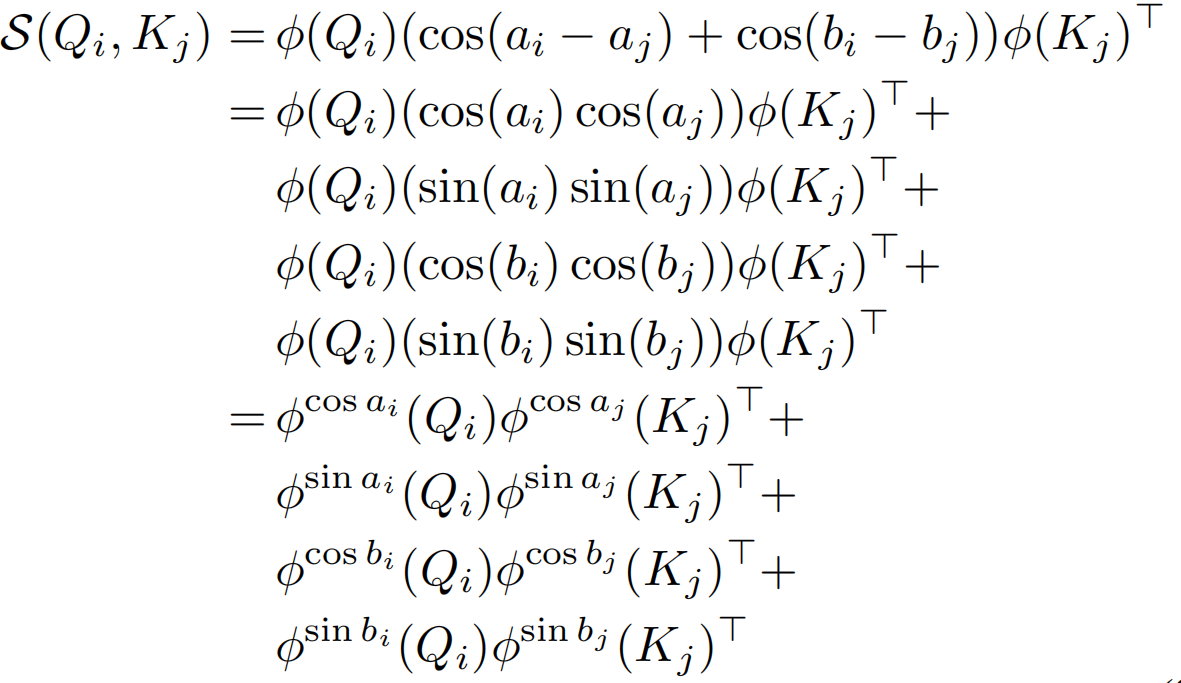
标准自注意力与线性自注意力对比如下:
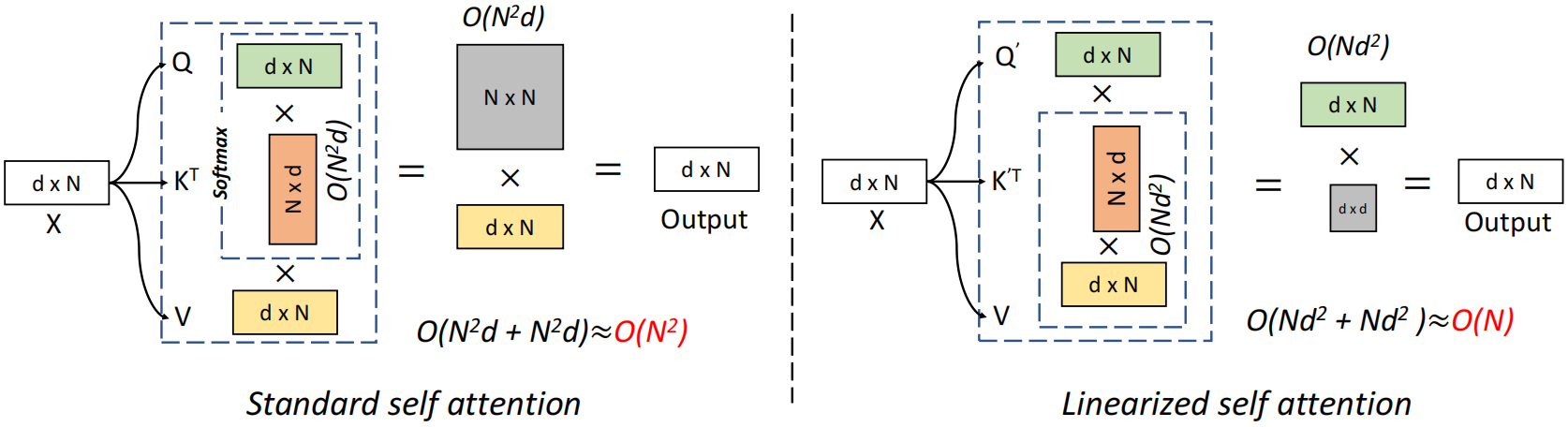
此外,与基于vanilla transformer的方法相比,当序列长度远大于特征维数时,邻近注意力算法表现出效率优势。为了满足这一要求,本文提出了一种新的邻近注意力块,在不牺牲性能的前提下降低了特征维数。包括一个特征缩减注意力(Feature Reduction Attention, RFA)模块和一个特征保持连接(Feature Preserving Connection, FRC)模块,RFA模块将输入特征维数降低一半,FRC模块恢复原始特征分布并增强表示能力。最后采用金字塔结构的邻近注意力块构造了一个名为邻近视觉Transformer(Vicinity Vision Transformer, VVT)的骨干网络。
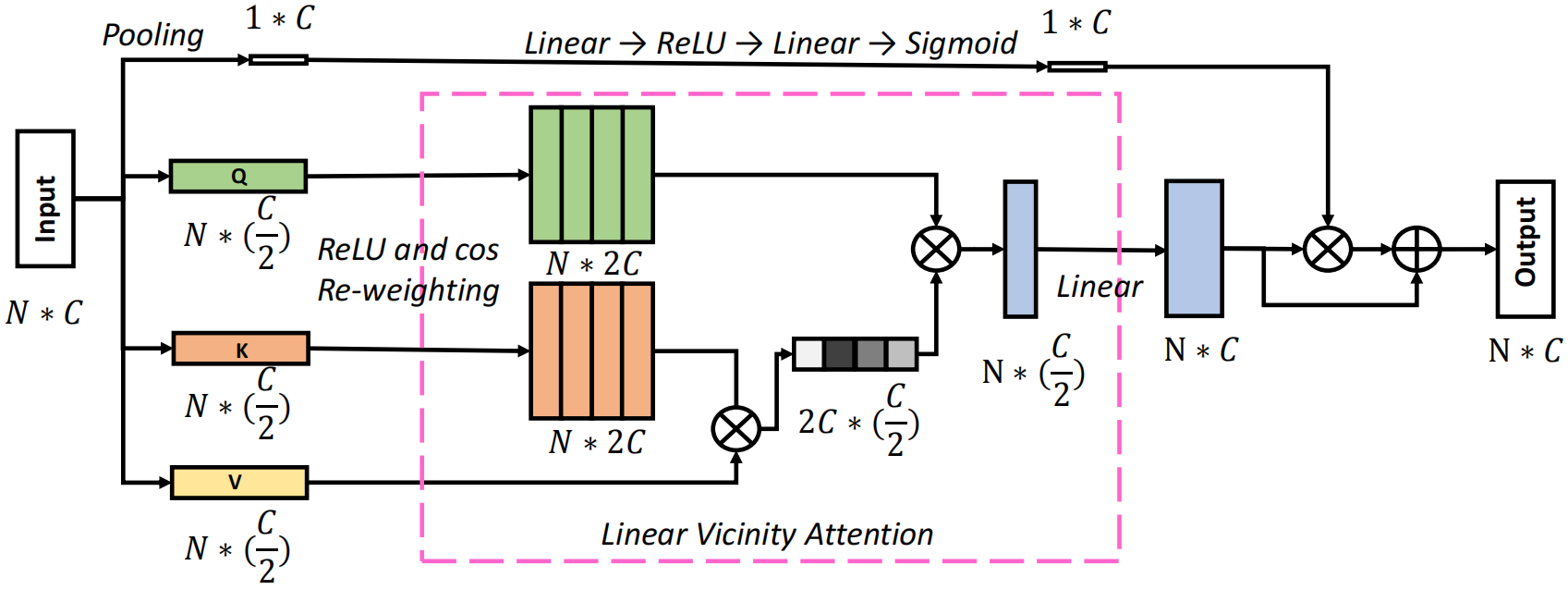
输入X∈RN×d,通过FRA模块将其投影成Q∈RN×d/2, K∈RN×2/d, V∈RN×2/d,并降低了特征维数。然后通过局部分解和re-weighting得到Q'∈ RN×2d, K'∈ RN×2d用于计算线性自注意力,由于自注意力是在更低的维度计算的,在上面添加了一个叫做FRC的跳跃连接,包括一个平均池化操作和两个线性层来保持原始特征分布并增强表示能力。
得到的最终骨干网络如下:
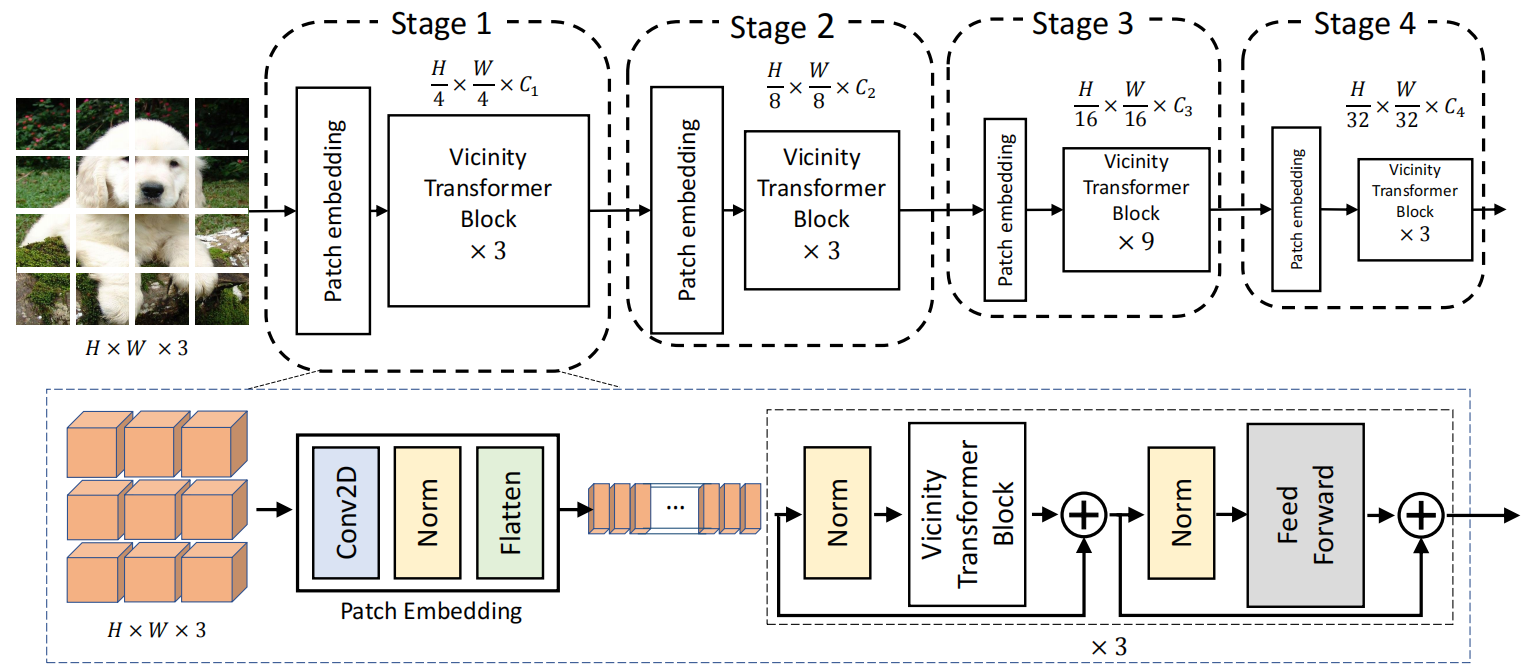
采用渐进式收缩金字塔结构,有四个阶段,生成不同的尺度的特征图。每个阶段包含一个patch embedding层和多个Vicinity Transformer块。
Vicinity Vision Transformer概述的更多相关文章
- ICCV2021 | Vision Transformer中相对位置编码的反思与改进
前言 在计算机视觉中,相对位置编码的有效性还没有得到很好的研究,甚至仍然存在争议,本文分析了相对位置编码中的几个关键因素,提出了一种新的针对2D图像的相对位置编码方法,称为图像RPE(IRPE). ...
- ICCV2021 | 渐进采样式Vision Transformer
前言 ViT通过简单地将图像分割成固定长度的tokens,并使用transformer来学习这些tokens之间的关系.tokens化可能会破坏对象结构,将网格分配给背景等不感兴趣的区域,并引 ...
- ICCV2021 | Tokens-to-Token ViT:在ImageNet上从零训练Vision Transformer
前言 本文介绍一种新的tokens-to-token Vision Transformer(T2T-ViT),T2T-ViT将原始ViT的参数数量和MAC减少了一半,同时在ImageNet上从 ...
- VIT Vision Transformer | 先从PyTorch代码了解
文章原创自:微信公众号「机器学习炼丹术」 作者:炼丹兄 联系方式:微信cyx645016617 代码来自github [前言]:看代码的时候,也许会不理解VIT中各种组件的含义,但是这个文章的目的是了 ...
- vision transformer
VIT 总览 Step1 Step2
- ICCV2021 | TransFER:使用Transformer学习关系感知的面部表情表征
前言 人脸表情识别(FER)在计算机视觉领域受到越来越多的关注.本文介绍了一篇在人脸表情识别方向上使用Transformer来学习关系感知的ICCV2021论文,论文提出了一个TransFER ...
- ICCV2021 | PnP-DETR:用Transformer进行高效的视觉分析
前言 DETR首创了使用transformer解决视觉任务的方法,它直接将图像特征图转化为目标检测结果.尽管很有效,但由于在某些区域(如背景)上进行冗余计算,输入完整的feature maps ...
- ICCV2021 | Swin Transformer: 使用移位窗口的分层视觉Transformer
前言 本文解读的论文是ICCV2021中的最佳论文,在短短几个月内,google scholar上有388引用次数,github上有6.1k star. 本文来自公众号CV技术指南的论文分享系 ...
- ICCV2021 | SOTR:使用transformer分割物体
前言 本文介绍了现有实例分割方法的一些缺陷,以及transformer用于实例分割的困难,提出了一个基于transformer的高质量实例分割模型SOTR. 经实验表明,SOTR不仅为实例分割提供了 ...
- ICCV2021 | 用于视觉跟踪的学习时空型transformer
前言 本文介绍了一个端到端的用于视觉跟踪的transformer模型,它能够捕获视频序列中空间和时间信息的全局特征依赖关系.在五个具有挑战性的短期和长期基准上实现了SOTA性能,具有实时性,比 ...
随机推荐
- “喜提”一个P2级故障—CMSGC太频繁,你知道这是什么鬼?
大家好,我是陶朱公Boy. 背景 今天跟大家分享一个前几天在线上碰到的一个GC故障- "CMSGC太频繁". 不知道大家看到这条告警内容后,是什么感触?我当时是一脸懵逼的,一万个为 ...
- Python实验报告(第2章)
实验2:Python语言基础 一.实验目的和要求 1.了解Python的编写规范要求: 2.了解Python的基本数据类型: 3.学会使用Python的五种运算符: 4.掌握Python的基本输入和输 ...
- 万字长文解析Scaled YOLOv4模型(YOLO变体模型)
一,Scaled YOLOv4 摘要 1,介绍 2,相关工作 2.1,模型缩放 3,模型缩放原则 3.1,模型缩放的常规原则 3.2,为低端设备缩放的tiny模型 3.3,为高端设备缩放的Large模 ...
- Git操作不规范,战友提刀来相见!
年终奖都没了,还要扣我绩效,门都没有,哈哈. 这波骚Git操作我也是第一次用,担心闪了腰,所以不仅做了备份,也做了笔记,分享给大家. 文末留言,聊聊你的年终奖. 问题描述 小A和我在同时开发一个功能模 ...
- ABC238E Range Sums
简要题意 有一个长度为 \(N\) 的序列 \(a\),你知道 \(Q\) 个区间的和.求是否可以知道 \([1,n]\) 的和. \(1 \leq N,Q \leq 2 \times 10^5\) ...
- angular11 报错 ERROR Error: If ngModel is used within a form tag, either the name attribute must be set or the form
angular 报错 ERROR Error: If ngModel is used within a form tag, either the name attribute must be set ...
- 在函数中设置input的multiple属性以及input的点击事件时,设置失效
1.在函数中先设置input文件可以多选,然后再设置input框的点击事件情况下,有时候这个多选设置会失效. 我们可以采用下面的方式去解决 <input ref="myInputRef ...
- python处理apiDoc转swagger
python处理apiDoc转swagger 需要转换的接口 现在我需要转换的接口全是nodejs写的数据,而且均为post传输的json格式接口 apiDoc格式 apiDoc代码中的格式如下: / ...
- 【随笔记】NDK 编译开源库 SQLite3
NDK 编译环境搭建请参考:[工作笔记]NDK 编译开源库 nghttp2/openssl/curl_lovemengx的博客-CSDN博客 一.下载源代码 wget https://github.c ...
- drf-序列化器、反序列化、反序列化校验
1.APIView执行流程 1.之前我们是基于django原生的View编写接口,drf提供给咱们的一个类APIView,以后使用drf写视图类,都是继承这个类及其子类,APIView本身就是继承了D ...