python爬取快手小姐姐视频
流程分析
一、导入需要的三方库
import re #正则表表达式文字匹配
import requests #指定url,获取网页数据
import json #转化json格式
import os #创建文件
二、确定目标地址
快手的目标地址需要在https://www.kuaishou.com网站截取请求,需要在控制台network截取,找到真正的地址https://www.kuaishou.com/graphql
url = "https://www.kuaishou.com/graphql" #目标网站url
三、确定数据位置
通过在network中搜索网页中显示的特定数据来确定data数据包,可以发现数据在data中。
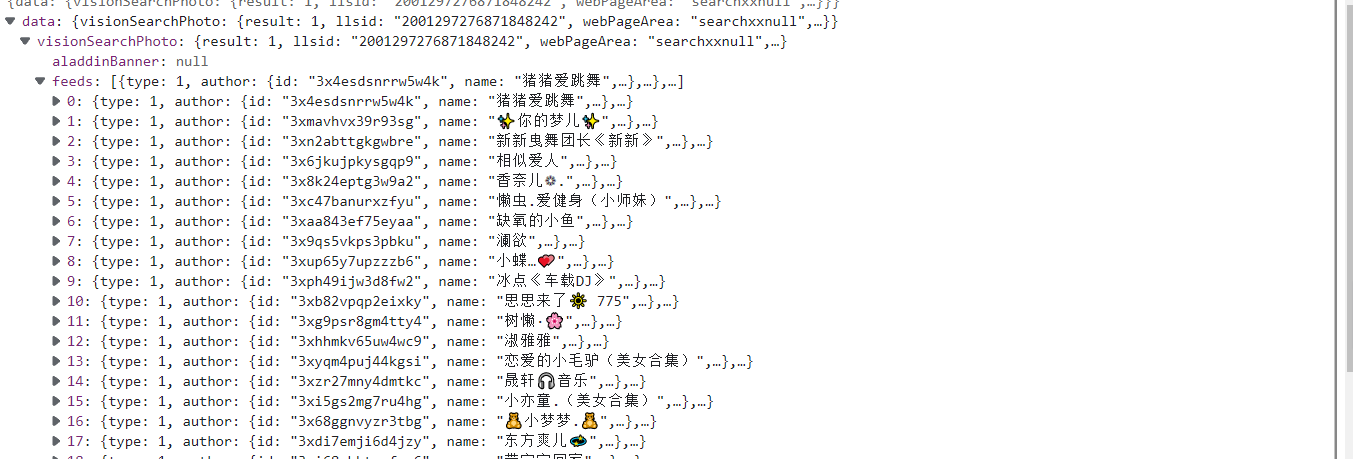
四、伪装请求头、复制data数据
在控制台找到headers,复制里面的信息并手动转换成键值对的形式
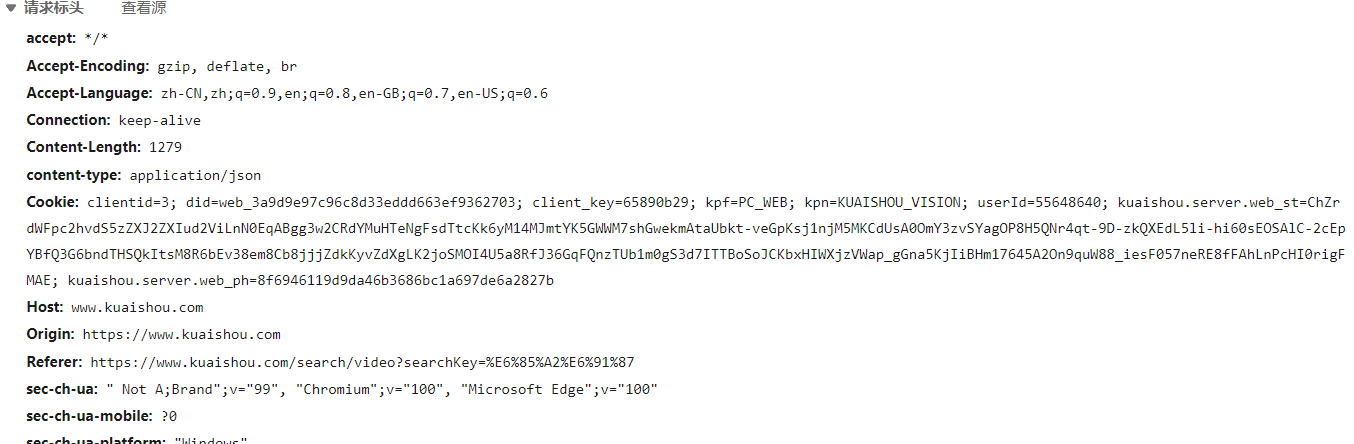
在负载中找到以下信息,并封装到data里用于post请求

data = { #封装data数据
'operationName': "visionSearchPhoto",
'query': "fragment photoContent on PhotoEntity {\n id\n duration\n caption\n likeCount\n viewCount\n realLikeCount\n coverUrl\n photoUrl\n photoH265Url\n manifest\n manifestH265\n videoResource\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n profileUserTopPhoto\n __typename\n}\n\nfragment feedContent on Feed {\n type\n author {\n id\n name\n headerUrl\n following\n headerUrls {\n url\n __typename\n }\n __typename\n }\n photo {\n ...photoContent\n __typename\n }\n canAddComment\n llsid\n status\n currentPcursor\n __typename\n}\n\nquery visionSearchPhoto($keyword: String, $pcursor: String, $searchSessionId: String, $page: String, $webPageArea: String) {\n visionSearchPhoto(keyword: $keyword, pcursor: $pcursor, searchSessionId: $searchSessionId, page: $page, webPageArea: $webPageArea) {\n result\n llsid\n webPageArea\n feeds {\n ...feedContent\n __typename\n }\n searchSessionId\n pcursor\n aladdinBanner {\n imgUrl\n link\n __typename\n }\n __typename\n }\n}\n",
'variables': {'keyword': keyword,'pcursor': str(page),'page':"search",'searchSessionId':"MTRfNTU2NDg2NDBfMTY1MTE0Njk1MTk5OV_mhaLmkYdfNjA0NQ"}
}
data = json.dumps(data) #将字典数据data转换成需要的json
headers = { #伪装请求头,模拟浏览器访问
'accept': "*/*",
'Accept-Encoding' : "gzip,deflate,br",
'Accept-Language': "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
'Connection': "keep-alive",
'Content-Length': "1279",
'content-type': "application/json",
'Cookie': "clientid=3; did=web_3a9d9e97c96c8d33eddd663ef9362703; client_key=65890b29; kpf=PC_WEB; kpn=KUAISHOU_VISION; userId=55648640; kuaishou.server.web_st=ChZrdWFpc2hvdS5zZXJ2ZXIud2ViLnN0EqABVSIs0T2ccYTa7qgMDgpAdRiErWNJyU1r87iKEYuIWEo_oJSNGq4aTBB5sq0bA7iLeCMOoX0grrEbBkpPmehOVWEs_tC-cDytf6dxSLnrE9-tRQaVcHziopazhh5rroA2XZmHEjHAe6z9-AHD0ZTxV9nJPHeI0-k0wfn9DHvDcj8ZUgQexbGwXDeH2wBV_WSuzutsd3d5oLNmN-90a33TXhoS6uws2LN-siMyPVYdMaXTUH7FIiBd27-7kiEEP6BHgx67BTXhdNPtfA88SZZL4Q_uQ09AuCgFMAE; kuaishou.server.web_ph=b0d04539ad2d77e13d866a70f9e56371c4a6",
'Host' : "www.kuaishou.com",
'Origin': "https://www.kuaishou.com",
'Referer': "https://www.kuaishou.com/search/video?searchKey=%E6%85%A2%E6%91%87",
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="100", "Microsoft Edge";v="100"',
'sec-ch-ua-mobile' : "?0",
'sec-ch-ua-platform': '" "Windows" "',
'Sec-Fetch-Dest': "empty",
'Sec-Fetch-Mode':"cors",
'Sec-Fetch-Site': "same-origin",
"User-Agent": "Mozilla / 5.0(Linux;Android6.0;Nexus5 Build / MRA58N) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 99.0.4844.51Mobile Safari / 537.36"
}
五、发出请求
向网站发起请求,需要用到第三方requests库,进行访问。
response = requests.post(url=url,headers=headers,data=data) #向目标网站发出请求
六、数据解析
通过re库和xpath进行数据解析,解析到需要的数据封装到列表中。
json_data = response.json() #转换json数据
#print(json_data)
feed_list = json_data['data']['visionSearchPhoto']['feeds'] #在标签中找出每一项的列表
#print(feed_list) for feeds in feed_list: #循环每一项
title = feeds['photo']['caption'] #在网页中找出标题
new_title = re.sub(r'[\/:*?"<>\n]','_',title) #去除标题中的特殊字符
photoUrl = feeds['photo']['photoUrl'] #找到视频的url地址
mp4_data = requests.get(photoUrl).content #转换视频二进制形式
七、保存数据
创建文件夹,并将数据保存到文件夹中。需要用到os库。
def mkdir(path): #创建文件夹
# 引入模块
import os #引入第三方库 # 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path + ' 目录已存在')
return False
with open(keyword+'/'+ new_title +'.mp4',mode="wb") as f: #设定保存数据路径
f.write(mp4_data) #保存数据
print("保存成功!",new_title)
完整源代码
# -*- coding = utf-8 -*-
# @Time : 2022/4/28 10:48
# @Author :王敬博
# @File : 快手小姐姐.py
# @Software: PyCharm
import re #正则表表达式文字匹配
import requests #指定url,获取网页数据
import json #转化json格式 def mkdir(path): #创建文件夹
# 引入模块
import os #引入第三方库 # 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path + ' 目录已存在')
return False url = "https://www.kuaishou.com/graphql" #目标网站url keyword = input("请输入想要搜索的关键词") #搜索关键字
mkpath = "d:\\pywork\\demo02\\"+keyword #创建的文件路径
mkdir(mkpath) #调用函数,创建文件夹 for page in range(1,5): #爬取4页
print("==================第%d页================="%page) #打印爬取的页数
data = { #封装data数据
'operationName': "visionSearchPhoto",
'query': "fragment photoContent on PhotoEntity {\n id\n duration\n caption\n likeCount\n viewCount\n realLikeCount\n coverUrl\n photoUrl\n photoH265Url\n manifest\n manifestH265\n videoResource\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n profileUserTopPhoto\n __typename\n}\n\nfragment feedContent on Feed {\n type\n author {\n id\n name\n headerUrl\n following\n headerUrls {\n url\n __typename\n }\n __typename\n }\n photo {\n ...photoContent\n __typename\n }\n canAddComment\n llsid\n status\n currentPcursor\n __typename\n}\n\nquery visionSearchPhoto($keyword: String, $pcursor: String, $searchSessionId: String, $page: String, $webPageArea: String) {\n visionSearchPhoto(keyword: $keyword, pcursor: $pcursor, searchSessionId: $searchSessionId, page: $page, webPageArea: $webPageArea) {\n result\n llsid\n webPageArea\n feeds {\n ...feedContent\n __typename\n }\n searchSessionId\n pcursor\n aladdinBanner {\n imgUrl\n link\n __typename\n }\n __typename\n }\n}\n",
'variables': {'keyword': keyword,'pcursor': str(page),'page':"search",'searchSessionId':"MTRfNTU2NDg2NDBfMTY1MTE0Njk1MTk5OV_mhaLmkYdfNjA0NQ"}
} data = json.dumps(data) #将字典数据data转换成需要的json headers = { #伪装请求头,模拟浏览器访问
'accept': "*/*",
'Accept-Encoding' : "gzip,deflate,br",
'Accept-Language': "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
'Connection': "keep-alive",
'Content-Length': "1279",
'content-type': "application/json",
'Cookie': "clientid=3; did=web_3a9d9e97c96c8d33eddd663ef9362703; client_key=65890b29; kpf=PC_WEB; kpn=KUAISHOU_VISION; userId=55648640; kuaishou.server.web_st=ChZrdWFpc2hvdS5zZXJ2ZXIud2ViLnN0EqABVSIs0T2ccYTa7qgMDgpAdRiErWNJyU1r87iKEYuIWEo_oJSNGq4aTBB5sq0bA7iLeCMOoX0grrEbBkpPmehOVWEs_tC-cDytf6dxSLnrE9-tRQaVcHziopazhh5rroA2XZmHEjHAe6z9-AHD0ZTxV9nJPHeI0-k0wfn9DHvDcj8ZUgQexbGwXDeH2wBV_WSuzutsd3d5oLNmN-90a33TXhoS6uws2LN-siMyPVYdMaXTUH7FIiBd27-7kiEEP6BHgx67BTXhdNPtfA88SZZL4Q_uQ09AuCgFMAE; kuaishou.server.web_ph=b0d04539ad2d77e13d866a70f9e56371c4a6",
'Host' : "www.kuaishou.com",
'Origin': "https://www.kuaishou.com",
'Referer': "https://www.kuaishou.com/search/video?searchKey=%E6%85%A2%E6%91%87",
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="100", "Microsoft Edge";v="100"',
'sec-ch-ua-mobile' : "?0",
'sec-ch-ua-platform': '" "Windows" "',
'Sec-Fetch-Dest': "empty",
'Sec-Fetch-Mode':"cors",
'Sec-Fetch-Site': "same-origin",
"User-Agent": "Mozilla / 5.0(Linux;Android6.0;Nexus5 Build / MRA58N) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 99.0.4844.51Mobile Safari / 537.36"
} response = requests.post(url=url,headers=headers,data=data) #向目标网站发出请求
json_data = response.json() #转换json数据
#print(json_data)
feed_list = json_data['data']['visionSearchPhoto']['feeds'] #在标签中找出每一项的列表
#print(feed_list) for feeds in feed_list: #循环每一项
title = feeds['photo']['caption'] #在网页中找出标题
new_title = re.sub(r'[\/:*?"<>\n]','_',title) #去除标题中的特殊字符
photoUrl = feeds['photo']['photoUrl'] #找到视频的url地址
mp4_data = requests.get(photoUrl).content #转换视频二进制形式
with open(keyword+'/'+ new_title +'.mp4',mode="wb") as f: #设定保存数据路径
f.write(mp4_data) #保存数据
print("保存成功!",new_title)
效果展示
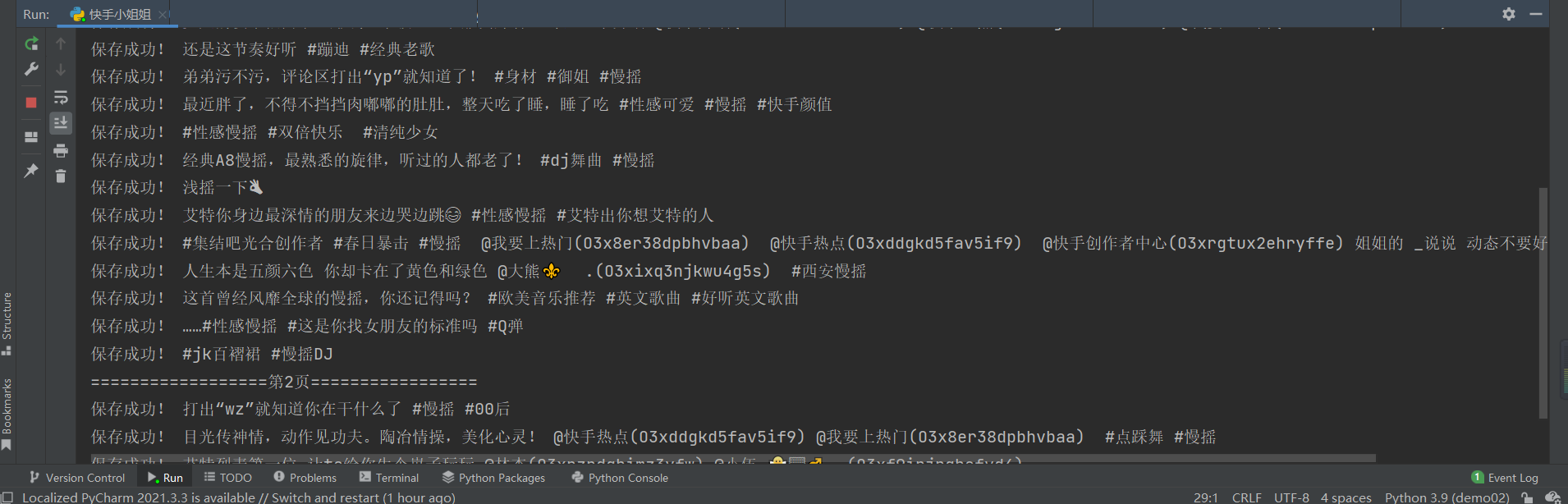
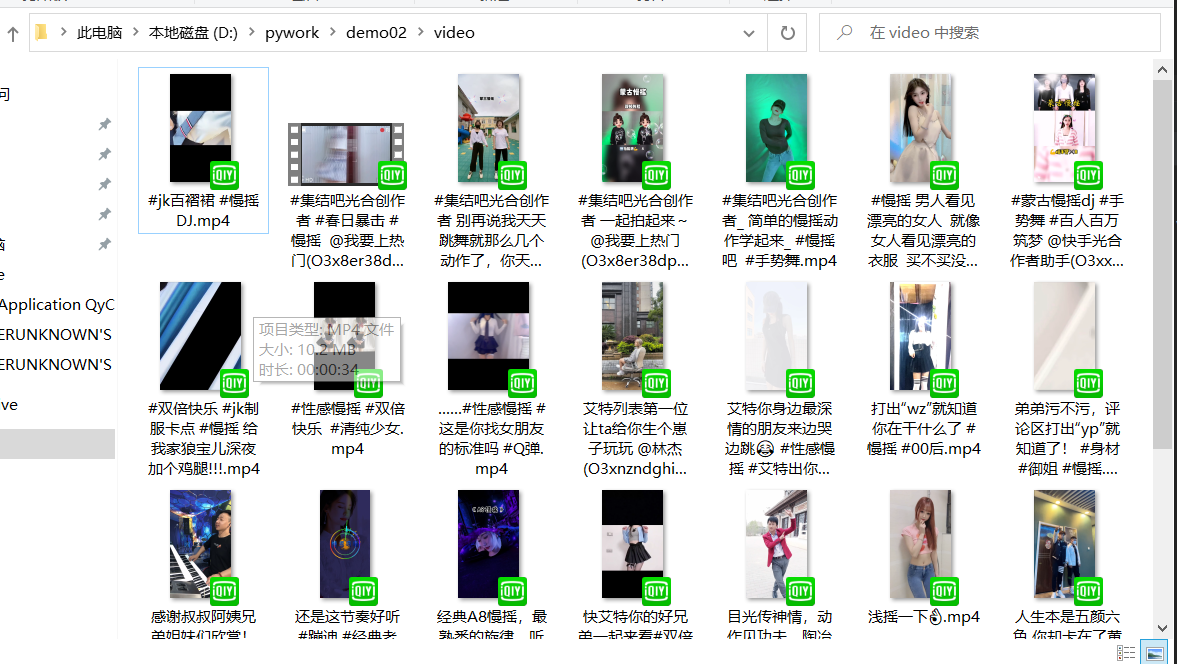
总结
这次爬取的流程以及源代码是从bili的课程中学到的,大概用了3个小时左右,个人感觉第一次爬取动态网页还是找到数据是比较难的。通过这次实践我终于体会到了程序员的快乐(谁不喜欢看小姐姐呢),嘿嘿嘿!
如果有问题可以私聊我,如果对你有帮助的话,记得个赞哦!
python爬取快手小姐姐视频的更多相关文章
- Python爬虫:爬取美拍小姐姐视频
最近在写一个应用,需要收集微博上一些热门的视频,像这些小视频一般都来自秒拍,微拍,美拍和新浪视频,而且没有下载的选项,所以只能动脑想想办法了. 第一步 分析网页源码. 例如:http://video. ...
- python爬取微信小程序(实战篇)
python爬取微信小程序(实战篇) 本文链接:https://blog.csdn.net/HeyShHeyou/article/details/90452656 展开 一.背景介绍 近期有需求需要抓 ...
- Python爬取微信小程序(Charles)
Python爬取微信小程序(Charles) 本文链接:https://blog.csdn.net/HeyShHeyou/article/details/90045204 一.前言 最近需要获取微信小 ...
- python爬取快手ios端首页热门视频
最近快手这种小视频app,特别的火,中午吃过午饭,闲来无聊,想搞下快手的短视频,看能不能搞到. 于是乎, 打开了fiddler,开始准备抓包, 设置代理,重启,下一步,查看本机ip 手机打开网络设置 ...
- 教你用python爬取抖音app视频
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思 ...
- python爬取快手视频 多线程下载
就是为了兴趣才搞的这个,ok 废话不多说 直接开始. 环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为htt ...
- 用python写一个爬虫——爬取性感小姐姐
忍着鼻血写代码 今天写一个简单的网上爬虫,爬取一个叫妹子图的网站里面所有妹子的图片. 然后试着先爬取了三页,大概有七百多张图片吧!各个诱人的很,有兴趣的同学可以一起来爬一下,大佬级程序员勿喷,简单爬虫 ...
- python爬取b站排行榜视频信息
和上一篇相比,差别不是很大 import xlrd#读取excel import xlwt#写入excel import requests import linecache import wordcl ...
- 没有内涵段子可以刷了,利用Python爬取段友之家贴吧图片和小视频(含源码)
由于最新的视频整顿风波,内涵段子APP被迫关闭,广大段友无家可归,但是最近发现了一个"段友"的app,版本更新也挺快,正在号召广大段友回家,如下图,有兴趣的可以下载看看(ps:我不 ...
随机推荐
- 请说说你对Struts2的拦截器的理解?
Struts2拦截器是在访问某个Action或Action的某个方法,字段之前或之后实施拦截,并且Struts2拦截器是可插拔的,拦截器是AOP的一种实现. 拦截器栈(Interceptor Stac ...
- Mybatis框架基础入门(三)--Mapper动态代理方式开发
使用MyBatis开发Dao,通常有两个方法,即原始Dao开发方法和Mapper动态代理开发方法. 原始Dao开发方法需要程序员编写Dao接口和Dao实现类,此方式开发Dao,存在以下问题: Dao方 ...
- vue开发chrome扩展,数据通过storage对象获取
开发chrome插件时遇到一个问题,那就是单文件组件的data数据需要从chrome提供的storage对象中获取,但是 chrome.storage.sync.get 方法是异步获取数据的,需要通过 ...
- 怎么理解 Redis 事务?
1)事务是一个单独的隔离操作:事务中的所有命令都会序列化.按顺序地执行.事务在执行的过程中,不会被其他客户端发送来的命令请求所打断. 2)事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执 ...
- java-idea创建maven管理web项目不能解析EL的解决方法
默认会原样输出: 这是由于这样子创建的web.xml的版本不够高 2.5之前web.xml文件中的头定义中,el表达式默认是忽略不解析的,故需要显示声明解析el表达式 所以我们要修改版本: 再< ...
- spring @Bean和@Order 官方doc理解
今天阅读了spring的官方代码,(大概)理解了@Bean和@Order如何使用. @Bean 官方代码解读: 0.@Bean的注入,用于表示这个bean被spring容器管理(创建.销毁)(官方英文 ...
- servlet中的HttpServletRequest对象
HttpServletRequest对象表示客户端浏览器发起的请求,当客户端浏览器通过HTTP协议访问服务器时,Tomcat会将HTTP请求中的所有信息解析并封装在HttpServletRequest ...
- Docker镜像构建之docker commit
我们可以通过公共仓库拉取镜像使用,但是,有些时候公共仓库拉取的镜像并不符合我们的需求.尽管已经从繁琐的部署工作中解放出来了,但是在实际开发时,我们可能希望镜像包含整个项目的完整环境,在其他机器上拉取打 ...
- 决策树3:基尼指数--Gini index(CART)
既能做分类,又能做回归.分类:基尼值作为节点分类依据.回归:最小方差作为节点的依据. 节点越不纯,基尼值越大,熵值越大 pi表示在信息熵部分中有介绍,如下图中介绍 方差越小越好. 选择最小的那个0.3 ...
- CSS学习(二):背景图片如何定位?
我们都知道background-position属性用来指定背景图片应该出现的位置,可以使用关键字.绝对值和相对值进行指定.在CSS Sprites中,这个属性使用比较频繁,使用过程中,我常混淆,经常 ...