hadoop 序列化源码浅析
Hadoop 并没有使用 JAVA 的序列化,而是引入了自己实的序列化系统, package org.apache.hadoop.io 这个包中定义了大量的可序列化对象,这些对象都实现了 Writable 接口, Writable 接口是序列化对象的一个通用接口.我们来看下Writable 接口的定义。
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}
Writable接口抽象了两个序列化的方法Write和ReadFields,分别对应了序列化和反序列化,参数DataOutPut 为java.io包内的IO类,Writable接口只是对象序列化的一个简单声明。
2.WriteCompareable接口
WriteCompareable接口是Wirtable接口的二次封装,提供了compareTo(T o)方法,用于序列化对象的比较的比较。因为mapreduce中间有个基于key的排序阶段。
}
下面是io包简单的类图关系。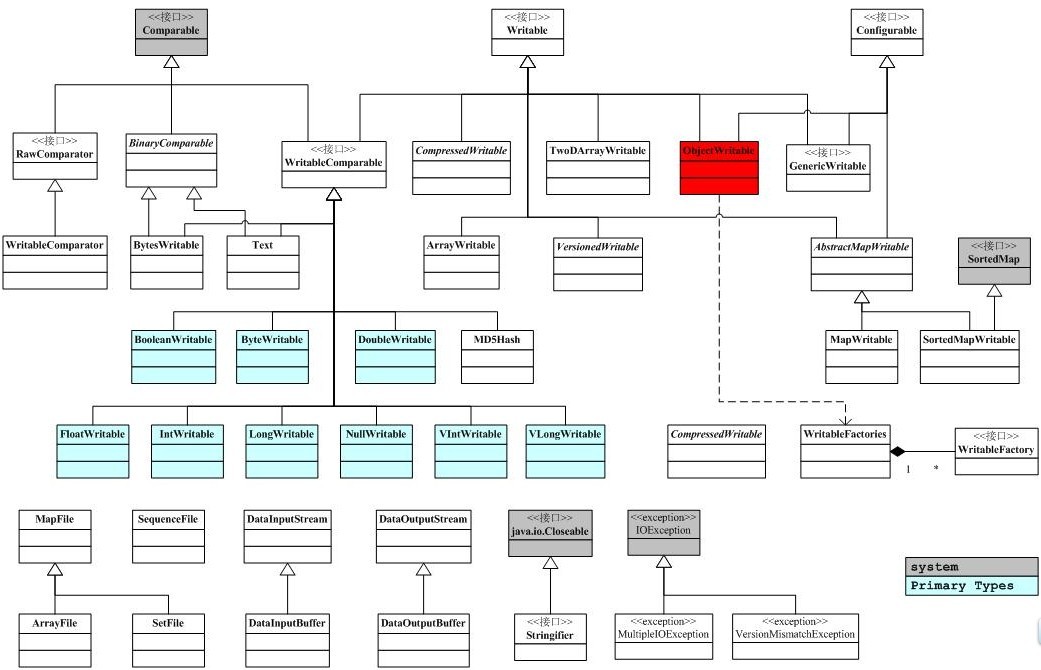
3.RawComparator接口
hadoop为序列化提供了优化,类型的比较对M/R而言至关重要,Key和Key的比较也是在排序阶段完成的,hadoop提供了原生的比较器接口RawComparator<T>用于序列化字节间的比较,该接口允许其实现直接比较数据流中的记录,无需反序列化为对象,RawComparator是一个原生的优化接口类,它只是简单的提供了用于数据流中简单的数据对比方法,从而提供优化:
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}
该接口并非被多数的衍生类所实现,其直接的子类为WritableComparator,多数情况下是作为实现Writable接口的类的内置类,提供序列化字节的比较。下面是RawComparator接口内置类的实现类图:
首先,我们看 RawComparator的直接实现类WritableComparator:
WritableComparator类似于一个注册表,里面通过静态map记录了所有WritableComparator类的集合。Comparators成员用一张Hash表记录Key=Class,value=WritableComprator的注册信息.
WritableComparator主要提供了两个功能
1. 提供了对原始compare()方法的一个默认实现
默认实现是 先反序列化为对像 再通过 对像比较(有开销的问题),所以一般都会被具体writeCompatable类的Comparator类覆盖以加快效率。
try {
buffer.reset(b1, s1, l1); // parse key1
key1.readFields(buffer);
buffer.reset(b2, s2, l2); // parse key2
key2.readFields(buffer);
} catch (IOException e) {
throw new RuntimeException(e);
}
return compare(key1, key2); // compare them
}
2. 充当RawComparable实例的工厂,以注册Writable的实现
例如,为了获取IntWritable的Comparator,可以直接调用其get方法。
4.WritableComparator类
接下来捡关键代码来分析writableComparator类,该类是RawComparator接口的直接子类。
代码1:registry 注册器
// registry 注册器:记载了WritableComparator类的集合
private static HashMap<Class, WritableComparator>comparators = new HashMap<Class, WritableComparator>();
----------------------------------------------------------------
代码2:获取WritableComparator实例
说
明:hashMap作为容器类线程不安全,故需要synchronized同步,get方法根据key=Class返回对应的
WritableComparator,若返回的是空值NUll,则调用protected
Constructor进行构造,而其两个protected的构造函数实则是调用了newKey()方法进行NewInstance
WritableComparator comparator = comparators.get(c);
if (comparator == null)
comparator = new WritableComparator(c, true);
return comparator;
}
----------------------------------------------------------------
代码3:WritableComparator构造方法
WritableComparator的构造函数源码如下:
/*
* keyClass,key1,key2和buffer都是用于WritableComparator的构造函数
*/
private final Class<? extends WritableComparable> keyClass;
private final WritableComparable key1; //WritableComparable接口
private final WritableComparable key2;
private final DataInputBuffer buffer; //输入缓冲流
protected WritableComparator(Class<? extends WritableComparable> keyClass,boolean createInstances) {
this.keyClass = keyClass;
if (createInstances) {
key1 = newKey();
key2 = newKey();
buffer = new DataInputBuffer();
} else {
key1 = key2 = null;
buffer = null;
}
}
上述的keyClass,key1,key2,buffer是记录HashMap对应的key值,用于WritableComparator的构造函数,但由其构造函数中我们可以看出WritableComparator根据Boolean createInstance来判断是否实例化key1,key2和buffer,而key1,key2是用于接收比较的两个key。在WritableComparator的构造函数里面通过newKey()的方法去实例化实现WritableComparable接口的一个对象,下面是newKey()的源码,通过hadoop自身的反射去实例化了一个WritableComparable接口对象。
return ReflectionUtils.newInstance(keyClass, null);
}
----------------------------------------------------------------
代码4:Compare()方法
(1). public int compare(Object a, Object b);
(2). public int compare(WritableComparable a, WritableComparable b);
(3). public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
三个compare()重载方法中,compare(Object a, Object b)利用子类塑形为WritableComparable而调用了第2个compare方法,而第2个Compare()方法则调用了Writable.compaerTo();最后一个compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2)方法源码如下:
try {
buffer.reset(b1, s1, l1); // parse key1
key1.readFields(buffer);
buffer.reset(b2, s2, l2); // parse key2
key2.readFields(buffer);
} catch (IOException e) {
throw new RuntimeException(e);
}
return compare(key1, key2); // compare them
}
Compare方法的一个缺省实现方式,根据接口key1,ke2反序列化为对象再进行比较。
利用Buffer为桥接中介,把字节数组存储为buffer后,调用key1(WritableComparable)的反序列化方法,再来比较key1,ke2,由此处可以看出,该compare方法是将要比较的二进制流反序列化为对象,再调用方法第2个重载方法进行比较。
----------------------------------------------------------------
代码5:方法define方法
该方法用于注册WritebaleComparaor对象到注册表中,注意同时该方法也需要同步,代码如下:
comparators.put(c, comparator);
}
----------------------------------------------------------------
代码6:余下诸如readInt的静态方法
这些方法用于实现WritableComparable的各种实例,例如 IntWritable实例:内部类Comparator类需要根据自己的IntWritable类型重载WritableComparator里面的compare()方法,可以说WritableComparator里面的compare()方法只是提供了一个缺省的实现,而真正的compare()方法实现需要根据自己的类型如IntWritable进行重载,所以WritableComparator方法中的那些readInt..等方法只是底层的封装的一个实现,方便内部Comparator进行调用而已。
下面我们着重看下BooleanWritable类的内置RawCompartor<T>的实现过程:
public Comparator() {//调用父类的Constructor初始化keyClass=BooleanWrite.class
super(BooleanWritable.class);
}
//重写父类的序列化比较方法,用些类用到父类提供的缺省方法
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
boolean a = (readInt(b1, s1) == 1) ? true : false;
boolean b = (readInt(b2, s2) == 1) ? true : false;
return ((a == b) ? 0 : (a == false) ? -1 : 1);
}
}
//注册
static {
WritableComparator.define(BooleanWritable.class, new Comparator());
}
总结:
hadoop
类似于Java的类包,即提供了Comparable接口(对应于writableComparable接口)和Comparator类(对应于
RawComparator类)用于实现序列化的比较,在hadoop
的IO包中已经封装了JAVA的基本数据类型用于序列化和反序列化,一般自己写的类实现序列化和反序列化需要继承WritableComparable接
口并且内置一个Comparator(继承于WritableComparator)的格式来实现自己的对象。
5.WritableFactory接口
作为工厂模式的WritableFactory,其抽象为一个接口,提供了具体的Writable对象创建实例的抽象方法newInstance(),代码如下:
public interface WritableFactory {
Writable newInstance();
}
WritableFactories类类似于WritableComparator类利用HashMap注册记录着所有实现上述接口的
WritableFactory的集合,与之不同的是WritableFactories是一个单例模式,所有的方法都是静态的。
关键代码:
private static final HashMap<Class, WritableFactory> CLASS_TO_FACTORY = new HashMap<Class, WritableFactory>();
public static Writable newInstance(Class<? extends Writable> c, Configuration conf) {
WritableFactory factory = WritableFactories.getFactory(c);
if (factory != null) {
//该方法的newInstanceof是调用了factory.newInstance()即你了实现的WritableFactory的newInstance()方法
Writable result = factory.newInstance();
if (result instanceof Configurable) {
((Configurable) result).setConf(conf);
}
return result;
} else {
return ReflectionUtils.newInstance(c, conf);
}
}
6.InputBuffer和DataInputBuffer类
类似于JAVA.IO 的装饰器模式, InputBuffer输入缓冲和DataInputBuffer数据缓冲的实现封装于内部类Buffer,该类的功能只是提供一个空的缓冲区,用于存储数据。Buffer代码如下:
public Buffer() {
super(new byte[] {});
}
public void reset(byte[] input, int start, int length) {
this.buf = input;
this.count = start+length;
this.mark = start;
this.pos = start;
}
public int getPosition() { return pos; }
public int getLength() { return count; }
}
InputBuffer和DataInputBuffer的方法委托于内部类private Buffer buffer,例如InputBuffer部分代码:
public int getPosition() { return buffer.getPosition(); }
/** Returns the length of the input. */
public int getLength() { return buffer.getLength(); }
DataInputBuffer 内置的Buffer代码如下
public Buffer() {
super(new byte[] {});
}
public void reset(byte[] input, int start, int length) {
this.buf = input;
this.count = start+length;
this.mark = start;
this.pos = start;
}
public byte[] getData() { return buf; }
public int getPosition() { return pos; }
public int getLength() { return count; }
}
两个类封装的Buffer一样,而其方法也都委托依赖于buffer,只是InputBuffer和DataInputBuffer继承于不同的类,如下:
DataInputBuffer:
}
InputBuffer:
}
7.OutputBuffer和DataOutputBuffe
类似于上文的InputBuffer和DataInputBuffer,hadoop 的OutputBuffer和DataOutputBuffer的实现与之相似,同样是利用内部类的引用,而关键的代码在于内部类Buffer:
public byte[] getData() { return buf; }
public int getLength() { return count; }
public void reset() { count = 0; }
public void write(InputStream in, int len) throws IOException {
int newcount = count + len;
if (newcount > buf.length) {
byte newbuf[] = new byte[Math.max(buf.length << 1, newcount)];
System.arraycopy(buf, 0, newbuf, 0, count);
buf = newbuf;
}
IOUtils.readFully(in, buf, count, len);
count = newcount;
}
}
先是判断buf数组的length,倘若空间不足,则new newbuf[] 利用Sysytem的数组拷贝实现内容的复制。
hadoop 序列化源码浅析的更多相关文章
- Android 手势识别类 ( 三 ) GestureDetector 源码浅析
前言:上 篇介绍了提供手势绘制的视图平台GestureOverlayView,但是在视图平台上绘制出的手势,是需要存储以及在必要的利用时加载取出手势.所 以,用户绘制出的一个完整的手势是需要一定的代码 ...
- spring源码浅析——IOC
=========================================== 原文链接: spring源码浅析--IOC 转载请注明出处! ======================= ...
- 【深入浅出jQuery】源码浅析--整体架构
最近一直在研读 jQuery 源码,初看源码一头雾水毫无头绪,真正静下心来细看写的真是精妙,让你感叹代码之美. 其结构明晰,高内聚.低耦合,兼具优秀的性能与便利的扩展性,在浏览器的兼容性(功能缺陷.渐 ...
- 【深入浅出jQuery】源码浅析2--奇技淫巧
最近一直在研读 jQuery 源码,初看源码一头雾水毫无头绪,真正静下心来细看写的真是精妙,让你感叹代码之美. 其结构明晰,高内聚.低耦合,兼具优秀的性能与便利的扩展性,在浏览器的兼容性(功能缺陷.渐 ...
- Struts2源码浅析-ConfigurationProvider
ConfigurationProvider接口 主要完成struts配置文件 加载 注册过程 ConfigurationProvider接口定义 public interface Configurat ...
- (转)【深入浅出jQuery】源码浅析2--奇技淫巧
[深入浅出jQuery]源码浅析2--奇技淫巧 http://www.cnblogs.com/coco1s/p/5303041.html
- HashSet其实就那么一回事儿之源码浅析
上篇文章<HashMap其实就那么一回事儿之源码浅析>介绍了hashMap, 本次将带大家看看HashSet, HashSet其实就是基于HashMap实现, 因此,熟悉了HashMap ...
- Android开发之Theme、Style探索及源码浅析
1 背景 前段时间群里有伙伴问到了关于Android开发中Theme与Style的问题,当然,这类东西在网上随便一搜一大把模板,所以关于怎么用的问题我想这里也就不做太多的说明了,我们这里把重点放在理解 ...
- 获取hadoop的源码和通过eclipse关联hadoop的源码
一.获取hadoop的源码 首先通过官网下载hadoop-2.5.2-src.tar.gz的软件包,下载好之后解压发现出现了一些错误,无法解压缩, 因此有部分源码我们无法解压 ,因此在这里我讲述一下如 ...
随机推荐
- java包和jar包
1.包 package pack; /*定义包,放在程序的第一行,包名所以字母小写*/ class PackageDemo{ publi ...
- STL标准模板库 向量容器(vector)
向量容器使用动态数组存储.管理对象.因为数组是一个随机访问数据结构,所以可以随机访问向量中的元素.在数组中间或是开始处插入一个元素是费时的,特别是在数组非常大的时候更是如此.然而在数组末端插入元素却很 ...
- Build Error 6041: Internal build error
Note: Following content is reprinted from the Original article Flexera : Build Error 6041. Only for ...
- 在Windows下用MingW 4.5.2编译live555
1.下载live555(http://www.live555.com/liveMedia/public/),解压. 2.进入MingW Shell,输入cd: F:/Qt/live(假定解压到F:/Q ...
- javascript变量
5种简单数据类型(基本数据类型) undefined null boolean number string (还有一种复杂的数据类型:object) 变量的两种不同的数据类型:基本类型(简单数 ...
- 青瓷qici - H5小游戏 抽奖机 “one-arm bandit”
写在前面 本文实现一个简单的抽奖效果,使用青瓷qici引擎,其中应用了Tween动画,粒子系统,遮罩,UI界面布局,项目设置,发布等功能呢. 目前开发采用1.0.7版本,后续如果界面有所变化请参考这个 ...
- inline-block的兼容性问题
inline-block的兼容性问题 Inline-block是元素display属性的一个值.这个名字的由来是因为,display设置这个值的元素,兼具行内元素( inline elements)跟 ...
- Python设计模式——设计原则
1.单一职责原则:每个类都只有一个职责,修改一个类的理由只有一个 2.开放-封闭远程(OCP):开放是指可拓展性好,封闭是指一旦一个类写好了,就尽量不要修改里面的代码,通过拓展(继承,重写等)来使旧的 ...
- cin、cin.get()、cin.getline()、getline()、gets()等函数的用法
学C++的时候,这几个输入函数弄的有点迷糊:这里做个小结,为了自己复习,也希望对后来者能有所帮助,如果有差错的地方还请各位多多指教(本文所有程序均通过VC 6.0运行)转载请保留作者信息:1.cin1 ...
- vim file save as
the command of vim to save as the file :w new_file_name