mysql查询orderby
/*
数据如下:
name val memo
a 2 a2(a的第二个值)
a 1 a1--a的第一个值
a 3 a3:a的第三个值
b 1 b1--b的第一个值
b 3 b3:b的第三个值
b 2 b2b2b2b2
b 4 b4b4
b 5 b5b5b5b5b5
*/
create table tb(name varchar(10),val int,memo varchar(20))
insert into tb values('a', 2, 'a2(a的第二个值)')
insert into tb values('a', 1, 'a1--a的第一个值')
insert into tb values('a', 3, 'a3:a的第三个值')
insert into tb values('b', 1, 'b1--b的第一个值')
insert into tb values('b', 3, 'b3:b的第三个值')
insert into tb values('b', 2, 'b2b2b2b2')
insert into tb values('b', 4, 'b4b4')
insert into tb values('b', 5, 'b5b5b5b5b5')
go
--一、按name分组取val最大的值所在行的数据。
--方法1: select a.* from tb a where val = (select max(val) from tb where name = a.name) order by a.name
--方法2:
select a.* from tb a where not exists(select 1 from tb where name = a.name and val > a.val)
--方法3:
select a.* from tb a,(select name,max(val) val from tb group by name) b where a.name = b.name and a.val = b.val order by a.name
--方法4:
select a.* from tb a inner join (select name , max(val) val from tb group by name) b on a.name = b.name and a.val = b.val order by a.name
--方法5
select a.* from tb a where 1 > (select count(*) from tb where name = a.name and val > a.val ) order by a.name
/*
name val memo
---------- ----------- --------------------
a 3 a3:a的第三个值
b 5 b5b5b5b5b5 */
本人推荐使用1,3,4,结果显示1,3,4效率相同,2,5效率差些,不过我3,4效率相同毫无疑问,1就不一样了,想不搞了。
--二、按name分组取val最小的值所在行的数据。
--方法1: select a.* from tb a where val = (select min(val) from tb where name = a.name) order by a.name
--方法2:
select a.* from tb a where not exists(select 1 from tb where name = a.name and val < a.val)
--方法3:
select a.* from tb a,(select name,min(val) val from tb group by name) b where a.name = b.name and a.val = b.val order by a.name
--方法4:
select a.* from tb a inner join (select name , min(val) val from tb group by name) b on a.name = b.name and a.val = b.val order by a.name
--方法5
select a.* from tb a where 1 > (select count(*) from tb where name = a.name and val < a.val) order by a.name
/*
name val memo
---------- ----------- --------------------
a 1 a1--a的第一个值
b 1 b1--b的第一个值 */
--三、按name分组取第一次出现的行所在的数据。
select a.* from tb a where val = (select top 1 val from tb where name = a.name) order by a.name
/*
name val memo
---------- ----------- --------------------
a 2 a2(a的第二个值)
b 1 b1--b的第一个值
*/
select a.* from tb a where val = (select top 1 val from tb where name = a.name order by newid()) order by a.name /*
name val memo
---------- ----------- --------------------
a 1 a1--a的第一个值
b 5 b5b5b5b5b5 */
--五、按name分组取最小的两个(N个)val
select a.* from tb a where 2 > (select count(*) from tb where name = a.name and val < a.val ) order by a.name,a.val select a.* from tb a where val in (select top 2 val from tb where name=a.name order by val) order by a.name,a.val
select a.* from tb a where exists (select count(*) from tb where name = a.name and val < a.val having Count(*) < 2) order by a.name
/*
name val memo
---------- ----------- --------------------
a 1 a1--a的第一个值
a 2 a2(a的第二个值)
b 1 b1--b的第一个值
b 2 b2b2b2b2 */
--六、按name分组取最大的两个(N个)val
select a.* from tb a where 2 > (select count(*) from tb where name = a.name and val > a.val ) order by a.name,a.val
select a.* from tb a where val in (select top 2 val from tb where name=a.name order by val desc) order by a.name,a.val
select a.* from tb a where exists (select count(*) from tb where name = a.name and val > a.val having Count(*) < 2) order by a.name
/*
name val memo
---------- ----------- --------------------
a 2 a2(a的第二个值)
a 3 a3:a的第三个值
b 4 b4b4
b 5 b5b5b5b5b5
*/
1 /*
2 数据如下:
3 name val memo
4 a 2 a2(a的第二个值)
5 a 1 a1--a的第一个值
6 a 1 a1--a的第一个值
7 a 3 a3:a的第三个值
8 a 3 a3:a的第三个值
9 b 1 b1--b的第一个值
10 b 3 b3:b的第三个值
11 b 2 b2b2b2b2
12 b 4 b4b4
13 b 5 b5b5b5b5b5
14
15 */
16
附:mysql “group by ”与"order by"的研究--分类中最新的内容
这两天让一个数据查询难了。主要是对group by 理解的不够深入。才出现这样的情况
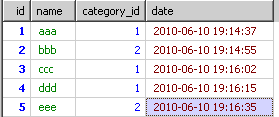
我现在需要取出每个分类中最新的内容
结果如下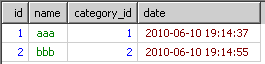
明显。这不是我想要的数据,原因是msyql已经的执行顺序是
执行顺序:from... where...group by... having.... select ... order by...
所以在order by拿到的结果里已经是分组的完的最后结果。
由from到where的结果如下的内容。
到group by时就得到了根据category_id分出来的多个小组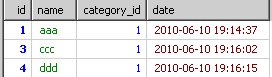
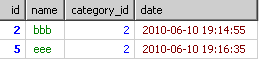
到了select的时候,只从上面的每个组里取第一条信息结果会如下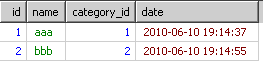
即使order by也只是从上面的结果里进行排序。并不是每个分类的最新信息。
回到我的目的上 --分类中最新的信息
根据上面的分析,group by到select时只取到分组里的第一条信息。有两个解决方法
1,where+group by(对小组进行排序)
2,从form返回的数据下手脚(即用子查询)
由where+group by的解决方法
对group by里的小组进行排序的函数我只查到group_concat()可以进行排序,但group_concat的作用是将小组里的字段里的值进行串联起来。
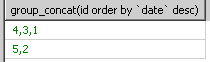
再改进一下
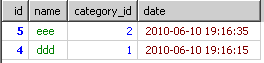
子查询解决方案
mysql查询orderby的更多相关文章
- Swoole 实战:MySQL 查询器的实现(协程连接池版)
目录 需求分析 使用示例 模块设计 UML 类图 入口 事务 连接池 连接 查询器的组装 总结 需求分析 本篇我们将通过 Swoole 实现一个自带连接池的 MySQL 查询器: 支持通过链式调用构造 ...
- mysql查询性能优化
mysql查询过程: 客户端发送查询请求. 服务器检查查询缓存,如果命中缓存,则返回结果,否则,继续执行. 服务器进行sql解析,预处理,再由优化器生成执行计划. Mysql调用存储引擎API执行优化 ...
- Mysql查询——深入学习
1.开篇 之前上一篇的随笔基本上是单表的查询,也是mysql查询的一个基本.接下来我们要看看两个表以上的查询如何得到我们想要的结果. 在学习的过程中我们一起进步,成长.有什么写的不对的还望可以指出. ...
- Mysql 查询练习
Mysql 查询练习 ---创建班级表 create table class( cid int auto_increment primary key, caption ) )engine=innodb ...
- mysql 查询去重 distinct
mysql 查询去重 distinct 待完善内容..
- MySQl查询区分大小写的解决办法
通过查询资料发现需要设置collate(校对) . collate规则: *_bin: 表示的是binary case sensitive collation,也就是说是区分大小写的 *_cs: ca ...
- 【转】mysql查询结果输出到文件
转自:http://www.cnblogs.com/emanlee/p/4233602.html mysql查询结果导出/输出/写入到文件 方法一: 直接执行命令: mysql> select ...
- MySQL查询缓存
MySQL查询缓存 用于保存MySQL查询语句返回的完整结果,被命中时,MySQL会立即返回结果,省去解析.优化和执行等阶段. 如何检查缓存? MySQL保存结果于缓存中: 把SELECT语句本身做h ...
- mysql 查询数据时按照A-Z顺序排序返回结果集
mysql 查询数据时按照A-Z顺序排序返回结果集 $sql = "SELECT * , ELT( INTERVAL( CONV( HEX( left( name, 1 ) ) , 16, ...
随机推荐
- Excel的用到的常规的技巧
这几天在做各种发票的报表,好几百的数据当然离不开EXCel,自己又是个白班,就记录下啦! EXCEL 判断某一单元格值是否包含在某一列中 就在Excel的表格中加入这个函数:=IF(ISERROR(V ...
- C# Datetime 使用详解
获得当前系统时间: DateTime dt = DateTime.Now; Environment.TickCount可以得到“系统启动到现在”的毫秒值 DateTime now = DateTime ...
- Yoga710笔记本Win10和Ubuntu系统共存
联想yoga710默认安装了win10系统,且使用EFI分区格式,安装Ubuntu不是一般的困难,经公司小哥的帮助下,几次终于完成了Ubuntu和Win10 共存. 经过多次安装测试,暂时能运行成功的 ...
- OpenCV:OpenCV目标检测Boost方法训练
在古老的CNN方法出现以后,并不能适用于图像中目标检测.20世纪60年代,Hubel和Wiesel( 百度百科 )在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈 ...
- AI.框架理论.语义网.语言间距.孤单
刷个博客,转载自于科学网:AI.框架理论.语义网.语言间距.孤单 一:引言: AI几乎是计算机科学家的梦想,自动化比计算机发展的要早的多.早期的自动化节省了大量人力,激发了人类懒惰的滋长和对自身进化缓 ...
- Postgresql_最新版11.2源码编译安装
pg官网:https://www.postgresql.org/ yum -y gcc gcc-c++ cmake ncurses-devel perl zlib* .去官网下载源码包. 下载地址:h ...
- 基于MATLAB的多功能语音处理器
一.设计功能 录制音频,保存音频 对录制的语音信号进行频谱分析,确定该段语音的主要频率范围: 利用采样定理,对该段语音信号进行采样,观察不用采样频率(过采样.欠采样.临界采样)对信号的影响: 实现语音 ...
- [系统资源攻略]IO第一篇-磁盘IO,内核IO概念
几个基本的概念 在研究磁盘性能之前我们必须先了解磁盘的结构,以及工作原理.不过在这里就不再重复说明了,关系硬盘结构和工作原理的信息可以参考维基百科上面的相关词条--Hard disk drive(英文 ...
- php curl选项列表(超详细)
第一类:对于下面的这些option的可选参数,value应该被设置一个bool类型的值:选项可选value值备注 CURLOPT_AUTOREFERER当根据Location:重定向时,自动设置hea ...
- 08.Web服务器-1.浏览器访问服务器显示页面的网络模型步骤解析