mysql查询orderby
/*
数据如下:
name val memo
a 2 a2(a的第二个值)
a 1 a1--a的第一个值
a 3 a3:a的第三个值
b 1 b1--b的第一个值
b 3 b3:b的第三个值
b 2 b2b2b2b2
b 4 b4b4
b 5 b5b5b5b5b5
*/
create table tb(name varchar(10),val int,memo varchar(20))
insert into tb values('a', 2, 'a2(a的第二个值)')
insert into tb values('a', 1, 'a1--a的第一个值')
insert into tb values('a', 3, 'a3:a的第三个值')
insert into tb values('b', 1, 'b1--b的第一个值')
insert into tb values('b', 3, 'b3:b的第三个值')
insert into tb values('b', 2, 'b2b2b2b2')
insert into tb values('b', 4, 'b4b4')
insert into tb values('b', 5, 'b5b5b5b5b5')
go
--一、按name分组取val最大的值所在行的数据。
--方法1: select a.* from tb a where val = (select max(val) from tb where name = a.name) order by a.name
--方法2:
select a.* from tb a where not exists(select 1 from tb where name = a.name and val > a.val)
--方法3:
select a.* from tb a,(select name,max(val) val from tb group by name) b where a.name = b.name and a.val = b.val order by a.name
--方法4:
select a.* from tb a inner join (select name , max(val) val from tb group by name) b on a.name = b.name and a.val = b.val order by a.name
--方法5
select a.* from tb a where 1 > (select count(*) from tb where name = a.name and val > a.val ) order by a.name
/*
name val memo
---------- ----------- --------------------
a 3 a3:a的第三个值
b 5 b5b5b5b5b5 */
本人推荐使用1,3,4,结果显示1,3,4效率相同,2,5效率差些,不过我3,4效率相同毫无疑问,1就不一样了,想不搞了。
--二、按name分组取val最小的值所在行的数据。
--方法1: select a.* from tb a where val = (select min(val) from tb where name = a.name) order by a.name
--方法2:
select a.* from tb a where not exists(select 1 from tb where name = a.name and val < a.val)
--方法3:
select a.* from tb a,(select name,min(val) val from tb group by name) b where a.name = b.name and a.val = b.val order by a.name
--方法4:
select a.* from tb a inner join (select name , min(val) val from tb group by name) b on a.name = b.name and a.val = b.val order by a.name
--方法5
select a.* from tb a where 1 > (select count(*) from tb where name = a.name and val < a.val) order by a.name
/*
name val memo
---------- ----------- --------------------
a 1 a1--a的第一个值
b 1 b1--b的第一个值 */
--三、按name分组取第一次出现的行所在的数据。
select a.* from tb a where val = (select top 1 val from tb where name = a.name) order by a.name
/*
name val memo
---------- ----------- --------------------
a 2 a2(a的第二个值)
b 1 b1--b的第一个值
*/
select a.* from tb a where val = (select top 1 val from tb where name = a.name order by newid()) order by a.name /*
name val memo
---------- ----------- --------------------
a 1 a1--a的第一个值
b 5 b5b5b5b5b5 */
--五、按name分组取最小的两个(N个)val
select a.* from tb a where 2 > (select count(*) from tb where name = a.name and val < a.val ) order by a.name,a.val select a.* from tb a where val in (select top 2 val from tb where name=a.name order by val) order by a.name,a.val
select a.* from tb a where exists (select count(*) from tb where name = a.name and val < a.val having Count(*) < 2) order by a.name
/*
name val memo
---------- ----------- --------------------
a 1 a1--a的第一个值
a 2 a2(a的第二个值)
b 1 b1--b的第一个值
b 2 b2b2b2b2 */
--六、按name分组取最大的两个(N个)val
select a.* from tb a where 2 > (select count(*) from tb where name = a.name and val > a.val ) order by a.name,a.val
select a.* from tb a where val in (select top 2 val from tb where name=a.name order by val desc) order by a.name,a.val
select a.* from tb a where exists (select count(*) from tb where name = a.name and val > a.val having Count(*) < 2) order by a.name
/*
name val memo
---------- ----------- --------------------
a 2 a2(a的第二个值)
a 3 a3:a的第三个值
b 4 b4b4
b 5 b5b5b5b5b5
*/
1 /*
2 数据如下:
3 name val memo
4 a 2 a2(a的第二个值)
5 a 1 a1--a的第一个值
6 a 1 a1--a的第一个值
7 a 3 a3:a的第三个值
8 a 3 a3:a的第三个值
9 b 1 b1--b的第一个值
10 b 3 b3:b的第三个值
11 b 2 b2b2b2b2
12 b 4 b4b4
13 b 5 b5b5b5b5b5
14
15 */
16
附:mysql “group by ”与"order by"的研究--分类中最新的内容
这两天让一个数据查询难了。主要是对group by 理解的不够深入。才出现这样的情况
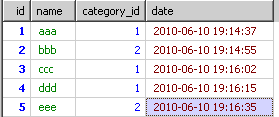
我现在需要取出每个分类中最新的内容
结果如下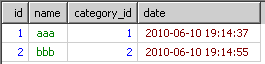
明显。这不是我想要的数据,原因是msyql已经的执行顺序是
执行顺序:from... where...group by... having.... select ... order by...
所以在order by拿到的结果里已经是分组的完的最后结果。
由from到where的结果如下的内容。
到group by时就得到了根据category_id分出来的多个小组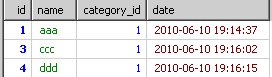
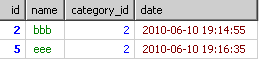
到了select的时候,只从上面的每个组里取第一条信息结果会如下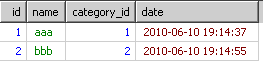
即使order by也只是从上面的结果里进行排序。并不是每个分类的最新信息。
回到我的目的上 --分类中最新的信息
根据上面的分析,group by到select时只取到分组里的第一条信息。有两个解决方法
1,where+group by(对小组进行排序)
2,从form返回的数据下手脚(即用子查询)
由where+group by的解决方法
对group by里的小组进行排序的函数我只查到group_concat()可以进行排序,但group_concat的作用是将小组里的字段里的值进行串联起来。
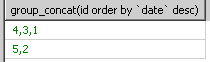
再改进一下
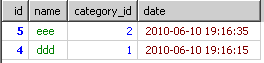
子查询解决方案
mysql查询orderby的更多相关文章
- Swoole 实战:MySQL 查询器的实现(协程连接池版)
目录 需求分析 使用示例 模块设计 UML 类图 入口 事务 连接池 连接 查询器的组装 总结 需求分析 本篇我们将通过 Swoole 实现一个自带连接池的 MySQL 查询器: 支持通过链式调用构造 ...
- mysql查询性能优化
mysql查询过程: 客户端发送查询请求. 服务器检查查询缓存,如果命中缓存,则返回结果,否则,继续执行. 服务器进行sql解析,预处理,再由优化器生成执行计划. Mysql调用存储引擎API执行优化 ...
- Mysql查询——深入学习
1.开篇 之前上一篇的随笔基本上是单表的查询,也是mysql查询的一个基本.接下来我们要看看两个表以上的查询如何得到我们想要的结果. 在学习的过程中我们一起进步,成长.有什么写的不对的还望可以指出. ...
- Mysql 查询练习
Mysql 查询练习 ---创建班级表 create table class( cid int auto_increment primary key, caption ) )engine=innodb ...
- mysql 查询去重 distinct
mysql 查询去重 distinct 待完善内容..
- MySQl查询区分大小写的解决办法
通过查询资料发现需要设置collate(校对) . collate规则: *_bin: 表示的是binary case sensitive collation,也就是说是区分大小写的 *_cs: ca ...
- 【转】mysql查询结果输出到文件
转自:http://www.cnblogs.com/emanlee/p/4233602.html mysql查询结果导出/输出/写入到文件 方法一: 直接执行命令: mysql> select ...
- MySQL查询缓存
MySQL查询缓存 用于保存MySQL查询语句返回的完整结果,被命中时,MySQL会立即返回结果,省去解析.优化和执行等阶段. 如何检查缓存? MySQL保存结果于缓存中: 把SELECT语句本身做h ...
- mysql 查询数据时按照A-Z顺序排序返回结果集
mysql 查询数据时按照A-Z顺序排序返回结果集 $sql = "SELECT * , ELT( INTERVAL( CONV( HEX( left( name, 1 ) ) , 16, ...
随机推荐
- C# 7.0新加特性
以下将是 C# 7.0 中所有计划的语言特性的描述.随着 Visual Studio “15” Preview 4 版本的发布,这些特性中的大部分将活跃起来.现在是时候来展示这些特性,你也告诉借此告诉 ...
- Oracle存储过程给变量赋值的方法
截止到目前我发现有三种方法可以在存储过程中给变量进行赋值: 1.直接法 := 如:v_flag := 0; 2.select into 如:假设变量名为v_flag,select count( ...
- Linux while和for循环简单分析
一.循环重定向 最近遇到了一种新的循环重定向写法,由于没看懂,说以网上搜索了一下,然后再此分享一下: while read line do ...... done < file 刚开始看,不明 ...
- sql 查询替换字符
Select A,B,C from Tb1 –查询所有 Select A,replace(B,’1’,’壹’),C from Tb1 替换查询 Tb1 A B C AA1 1 CC A ...
- Linux 之根目录介绍
1. /bin binary二进制 存放系统许多可执行程序文件 执行的相关指令,例如ls pwd whoami,后台的支持文件目录 2. /sbin super binary超级的二进制 存放系统许多 ...
- [CodeForces1059E] Split the Tree
树形DP. 用倍增处理出来每个点往上能延伸出去的最远路径,nlogn 对于每个节点,如果它能被后代使用过的点覆盖,就直接覆盖,这个点就不使用,否则就ans++,让传的Max改成dp[x] #inclu ...
- iptables 实现内网转发上网
介绍 通过iptables做nat转发实现所有内网服务器上网. 操作 首先开启可以上网的服务器上的内核路由转发功能.这里我们更改/etc/sysctl.conf 配置文件. [root@web1 /] ...
- 3分钟实现小程序唤起微信支付 Laravel教程
微信支付的接入,如果不使用成熟的开发包,将是巨大的工作量. 依赖 EasyWechat 先在 laravel 项目中依赖 easywechat 这个包 composer require "o ...
- mysql5.7忘记root密码
systemctl stop mysqld.service vi /etc/my.cnf [mysqld] skip-grant-tables skip-networking mysql -uroot ...
- uva 11624
#include<stdio.h> #include<string.h> #include<queue> using namespace std; #define ...