Power aware dynamic scheduling in multiprocessor system employing voltage islands
Minimizing the overall power conservation in a symmetric multiprocessor system disposed in a system-on-chip (SoC) depends on using voltage islands operated at different voltages such that similar circuits will perform at significantly different levels because of the voltage differences. Otherwise identical processor cores of a symmetric multiprocessor system are placed in various ones of the voltage islands such that they consume differing operating powers because of the voltage differences. The slack-time experienced by each of a variety of tasks during execution by the processor cores is calculated and tabulated. Thereafter, each task is scheduled for a particular processor core according to its performance level as determined by its operating voltage, and depending on the corresponding slack-time calculation for the task. Such scheduling will minimize power consumption by selecting a minimum power processor core, and still allow for complete execution in the time available.
Field of the Invention
The present invention relates to symmetric multiprocessor systems implemented with voltage islands, and more particularly to methods and circuits to conserve system-on-chip (SoC) power consumption by measuring performance and estimation for run-time execution phases to automatically adapt to varying application workloads .
Description of Related Art
Symmetric multiprocessing (SMP) connects identical processors a single shared main memory. Most common multiprocessor systems today use an SMP architecture. Any task can be assigned for execution by any processor, because the data for that task is located in shared memory. Conventional SMP operating systems can move tasks between processors to balance the work load efficiently. The many individual processors in an SMP implementation can starve for data, because memory is typically much slower than each of processors accessing it. SMP has many applications in science, industry, and business where the software is custom programmed for multithreaded processing. But, word processors, computer games, and other most consumer products are not written in a way that they can benefit from SMP. Programs running on SMP systems can perform better even when they have been written for uniprocessor systems.
Hardware interrupts usually suspend program execution, while in an SMP system the kernel hands them off to be run on an idle processor instead. Given proper operating system (OS) support, some applications like software compilers and distributed computing projects, will see speed-ups nearly multiply by the number of additional processors.
When many jobs are being processed in an SMP environment, a loss of hardware efficiency can result. Software programs have been developed to schedule jobs in various ways so that processor utilization is optimized.
A given processor can generally increase its performance if clocked at a higher rate. The highest clocking rates are limited by the semiconductor technology and the operating voltage. For a given operating voltage and semiconductor technology, there will be a maximum clock rate. If the operating voltage is increased, the clocks can be proportionately increased to step up performance, within practical limits. But, the power consumption
will go up as the square of the voltage increase,
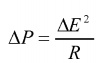 o
o
K increased performance is gained at a cost of much increased power consumption.
The prior art has used dynamic voltage scheduling based on the task execution phases computed off-line. What would be better would be to use a performance measurement and estimation unit to analyze the execution phases during run-time. That way the system could automatically adapt to varying application workloads. Static mapping of the tasks to a single processor is also not desirable. It would be best to schedule tasks dynamically onto a set of symmetric multiprocessors based on their estimated execution times . The prior art has also dealt with scheduling tasks onto a processor that supports different voltages, keeping the power consumption as the cost function. But such do not use DVS on a per task basis. Such conventional devices sort tasks by deadlines in ascending order. They are put in a reservation list of the target processing element. The slack time of the first
task is computed with both the highest and lowest voltage levels supported by the target processing element. The computation time of the task at the highest and lowest voltages is calculated. The voltage level of the target processing element is found at which the task can meet the deadline. Then DVS is used to change its voltage level and the task is scheduled onto it.
What is needed is a system in which different cores of an SoC are provided with different supply voltages. Voltage islands enable core-level power optimization for SoC design by utilizing a unique supply voltage for each core. In an SoC with homogeneous cores and voltage islands, then all tasks can be kept on one list. Each task is analyzed for its performance requirements. Then a particular processor whose supply voltage can already guarantee the performance requirement of the task is chosen to run the task. Next time, it is analyzed again, and the same task can be mapped onto a different processor having a different supply voltage that can guarantee its performance requirements .
SUMMARY OF THE INVENTION
Briefly, symmetric multiprocessor systems with voltage islands include dynamic scheduling of the application tasks onto the available processors. The voltage islands enable each processor to be supplied with different independent operating voltages and corresponding maximum clock frequencies. The difference between the available and actual processor task execution times are measured so the slack times of recurrences of these tasks can be estimated. The processing capabilities of the individual processors are cataloged according to particular operating voltages and frequencies. A dynamic scheduler chooses an appropriate processor and voltage island setting for the tasks
based on the apparent processor required. This yields optimal power consumption.
An advantage of the present invention is that a SoC implementation of a symmetric multiprocessor system is provided which will conserve power.
A further advantage of the present invention is a SoC implementation of a symmetric multiprocessor system is provided that uses voltage islands to avoid real time overheads associated with DVS power controls. A still further advantage of the present invention is that a SoC implementation of a symmetric multiprocessor system is provided that schedules tasks according to a slack-time calculator .
The above and still further objects, features, and advantages of the present invention will become apparent upon consideration of the following detailed description of specific embodiments thereof, especially when taken in conjunction with the accompanying drawings .
DETAILED DESCRIPTION OF THE INVENTION
Fig. 1 represents a symmetric multiprocessor system embodiment of the present invention, and is referred to herein by the general reference numeral 100. The symmetric multiprocessor system 100 comprises a plurality of voltage islands 102-104 disposed in a common semiconductor chip 106. These voltage islands are provided three different operating voltages, hi, mid, and lo-voltage. A plurality of identical processor cores 108-110 are respective disposed in the voltage islands 102-104, but the differing operating voltages results in processor core 108 having relatively high performance (hi-MIPS) , processor core 109 having medium performance (mid-MIPS) , and processor core 110 having relatively low performance (lo-MIPS) . All three processor cores 108-110 each have access to a shared memory 112.

Since all three processor cores 108-110 are operated at different voltage levels, their respective power consumptions also differ. The power consumption will go up as the square of the voltage increase. E.g.,
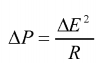 . So increased performance
. So increased performance
K is gained, e.g., in processor core 108, at a cost of much increased power consumption. In modern battery-operated portable devices, all power consumption waste must be strictly eliminated.
An operating system (OS) 114 provides for the selection of particular software tasks 116-120 to be executed by various ones of the processor cores 108-110. A slack time calculator 122 is connected to compare how much time an assigned task 116-120 took to be executed on a corresponding processor core 108-110. A processing capabilities and task loading table 124 is constructed from data obtained by the slack time calculator 122. It catalogs the processing capabilities of each of the processor cores 108- 110. A relative measure for the processing loads imposed by tasks previously executed is entered.
During operation, the performance required by a "task-a:e" can be tabulated, like in Table 124, in terms of millions- instruction-per-second (MIPS) . For example, heuristic evidence can be gathered to show "task-d" requires a medium MIPS performance. The second chart can be indexed to show "CPU-2" would be the appropriate choice for scheduling task-d. A message is sent from table 124 to scheduler 126 so that when OS 114 wants task-d 119 executed, it will be scheduled for dispatch to processor core 109. The slack-time calculator 122 can re-verify this was a good choice after the task executes. Since the higher power-consuming processor core 108 was avoided, power was saved by using a lower powered alternative processor core.
Different processor cores of the SoC are provided with different supply voltages. The voltage islands enable core-level power optimization for SoC design by providing a unique fixed supply voltage for each processor core. SoC ' s with voltage islands and homogeneous processor cores allow all the tasks to be kept in a single list that can be applied to all the cores in the SoC. Prior art devices prepare separate task lists for each processor core. Each task is gauged according to its performance requirements .
One-by-one, the tasks are matched up to a particular processor that can guarantee execution completion within the allotted time frame because its supply voltage is high enough. Every time the task presents itself, it is again analyzed and dynamically scheduled for the most appropriate processor core. In this way the dynamic scheduling is performed. DVS techniques have inherent overheads that may be too costly to employ on a task-by-task basis. The symmetric multiprocessor system 100 instead selects processor cores whose supply voltage can produce the necessary levels of performance in given window of time.
The slack time calculator and processing capabilities and task loading table 124 provide for performance measurement and estimation to capture the execution times of tasks in an application software. The performance measurements can be trace-based or accumulated from the execution times and the deadline requirement of individual tasks. The average/median values for slack times is computed, and multiple values of slack times in a certain time window are used to characterizes each slack time per task. Such characteristic information is thereafter used to predict a future execution and slack time of the task, thus dynamically scheduling tasks to the appropriate processors. The slack time calculator and processing capabilities and task loading table further provides for resetting of measurement information for a tasks when they have been newly scheduled on a different processor core.
Fig. 2 represents a symmetric multiprocessor system embodiment of the present invention that makes each voltage island adjustable with DVS, and is referred to herein by the general reference numeral 200. The symmetric multiprocessor system 200 comprises a plurality of voltage islands 202-204 disposed in a common semiconductor chip 206. These provide for independent and controllable dynamic voltage scaling (DVS) for each voltage island. Dynamic voltage scaling (DVS) has become a universal way to adjust the operating voltage and clocks to balance a circuit's performance with its concomitant power consumption. Voltage islands have been used in conventional designs to allow portions of a chip's circuitry to be subjected to independent DVS controls. But after the DVS has changed to a new value, settling times can be as long as 200-milliseconds . So it would be best not to change the DVS settings very often, or not at all after being initialized.
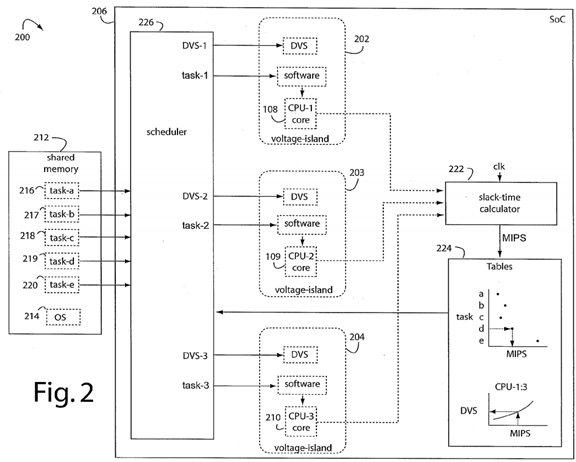
A plurality of processor cores 208-210 each have access to a shared memory 212. Each is disposed in a respective one of the voltage islands such that changes in the DVS will proportionately affect each processor core's performance and power consumption. An operating system (OS) 214 provides for the selection of particular software tasks 216-220 to be executed by various ones of the processor cores 208-210. A slack time calculator 222 is
connected to compare how much time an assigned task 216-120 took to be executed on a corresponding processor core 208-110 at a particular DVS setting.
A processing capabilities and task loading table 224 is constructed from data obtained by the slack time calculator 222. It catalogs the processing capabilities of each of the processor cores 208-210 at a variety of DVS settings. A relative measure for the processing loads imposed by tasks previously executed is entered. A scheduler 226 is controlled by the OS 214. It looks for an entry in the processing capabilities and task loading table 224 for each new next task to be scheduled. If previously characterized, then it sends the task to an appropriate, available processor core 208-110. A DVS control is issued for the corresponding voltage island to a value that will minimize power consumption and still allow for complete execution in the time available.
The dynamic scheduling assigns application tasks onto the available voltage island isolated processors of the symmetric multiprocessor system. Each of the processors is supplied with different independent operating voltages/frequencies. The slack times are measured by taking the time difference between the deadline and actual execution time of the task. These are placed in an application task graph. These measurement traces allow future slack times of tasks to be estimated. The individual processor processing capabilities are statically maintained. Such dynamic scheduling basically chooses the appropriate processor for the tasks based on their slack times to yield optimal power consumption. The processing capabilities table indicates the performance in MIPS provided by the individual processors. The MIPS offered by individual processors depends on the operating voltage and frequency of the processors. The table can be statically configured by looking at the voltage sources of the processors to
then estimate the expected performance. It can also compute the average slack times of tasks by making several, on-going observations .
The dynamic scheduler maps tasks onto the available processors using static estimates and profiling results. It gets slack information for all the application tasks from the performance measurement and estimation unit. Considering the first tasks mapped on the first processor, if the measured slack time of a first task on a first processor deviates from its average slack time, then such first task can be dynamically scheduled onto a second processor that matches the performance requirement. The mapping of tasks onto other processors is based on a processing capabilities table lookup.
In general, embodiments of the present invention are such that task assignment to an available processor assumes they are symmetrical but employ different supply voltages which make them capable of providing different throughputs. The task scheduling is based on the slack times of the task. Using voltage islands and dynamically scheduling the tasks based on their estimated performance requirements, or slack periods, provides substantial power savings.
SRC=https://www.google.com.hk/patents/WO2007077516A1
Power aware dynamic scheduling in multiprocessor system employing voltage islands的更多相关文章
- Thermally driven workload scheduling in a heterogeneous multi-processor system on a chip
Various embodiments of methods and systems for thermally aware scheduling of workloads in a portable ...
- PatentTips - Enhanced I/O Performance in a Multi-Processor System Via Interrupt Affinity Schemes
BACKGROUND OF THE INVENTION This relates to Input/Output (I/O) performance in a host system having m ...
- Parallelized coherent read and writeback transaction processing system for use in a packet switched cache coherent multiprocessor system
A multiprocessor computer system is provided having a multiplicity of sub-systems and a main memory ...
- Power control within a coherent multi-processing system
Within a multi-processing system including a plurality of processor cores 4, 6operating in accordanc ...
- Multiprocessing system employing pending tags to maintain cache coherence
A pending tag system and method to maintain data coherence in a processing node during pending trans ...
- Method and apparatus for providing total and partial store ordering for a memory in multi-processor system
An improved memory model and implementation is disclosed. The memory model includes a Total Store Or ...
- Unified shader model
https://en.wikipedia.org/wiki/Unified_shader_model In the field of 3D computer graphics, the Unified ...
- Extended symmetrical multiprocessor architecture
An architecture for an extended multiprocessor (XMP) computer system is provided. The XMP computer s ...
- A multiprocessing system including an apparatus for optimizing spin-lock operations
A multiprocessing system having a plurality of processing nodes interconnected by an interconnect ne ...
随机推荐
- Numpy库进阶教程(一)求解线性方程组
前言 Numpy是一个很强大的python科学计算库.为了机器学习的须要.想深入研究一下Numpy库的使用方法.用这个系列的博客.记录下我的学习过程. 系列: Numpy库进阶教程(二) 正在持续更新 ...
- JDBC高级特性(二)事务、并发控制和行集
一.事务 事务是指一个工作单元,它包括了一组加入,删除,改动等数据操作命令,这组命令作为一个总体向系统提交运行,要么都运行成功,要么所有恢复 在JDBC中使用事务 1)con.setAutoCommi ...
- Android实践 -- 对apk进行系统签名
对apk进行系统签名 签名工具 网盘下载 ,需要Android系统的签名的文件 platform.x509.pem 和 platform.pk8 这个两个文件在Android源码中的 ./build/ ...
- 如何使用 PyCharm 将代码上传到远程服务器上(详细图解)
说明:该篇博客是博主一字一码编写的,实属不易,请尊重原创,谢谢大家! 一丶测试说明 1.通过Windows电脑上的PyCharm,将代码上传到虚拟机Ubuntu系统中 需要在虚拟机中安装Ubuntu的 ...
- SiFive Unleashed启动
SiFive Unleashed启动 请仔细参看SiFive官网的文档HiFive Unleashed 使用串口连接过程 连接好硬件(电源+USB) 尝试打开电源键,检测硬件能被识别 配置minico ...
- RabbitMQ安全相关的网络资源介绍
无法用guest远程訪问RabbitMQ的的解决方式 Can't access RabbitMQ web management interface after fresh install http:/ ...
- js页面载入特效如何实现
js页面载入特效如何实现 一.总结 一句话总结:可以加选择器(里面的字符串)作为参数,这样函数就可以针对不同选择器,就很棒了. 1.特效的原理是什么? 都是通过标签的位置和样式来实现特效的. 二.js ...
- Android隐藏输入法
输入法隐藏两种方式: /** * 隐藏输入法 * * @param myActivity */ public static void hideInput(Activity myActivity,Edi ...
- HQL和SQL的区别
1.hql与sql的区别 sql 面向数据库表查询 hql 面向对象查询 hql : from 后面跟的 类名+类对象 where 后 用 对象的属性做条件 sql: from 后面跟的是表名 ...
- 安装Centos时“sda必须有一个GPT磁盘标签”
http://jingyan.baidu.com/article/c45ad29c272326051753e2d1.html