Summary: Depth-first Search(DFS)
There are generally two methods to write DFS algorithm, one is using recursion, another one is using stack. (reference from Wiki Pedia)
Pseudocode for both methods:
A recursive implementation of DFS:
procedure DFS(G,v):
label v as discovered
for all edges from v to w in G.adjacentEdges(v) do
if vertex w is not labeled as discovered then
recursively call DFS(G,w)
A non-recursive implementation of DFS(using stack):
procedure DFS-iterative(G,v):
let S be a stack
S.push(v)
while S is not empty
v ← S.pop()
if v is not labeled as discovered:
label v as discovered
for all edges from v to w in G.adjacentEdges(v) do
S.push(w)
The non-recursive implementation is similar to breadth-first search but differs from it in two ways: it uses a stack instead of a queue, and it delays checking whether a vertex has been discovered until the vertex is popped from the stack rather than making this check before pushing the vertex.
Here's another good explenation: http://www.algolist.net/Algorithms/Graph/Undirected/Depth-first_search
Depth-first search, or DFS, is a way to traverse the graph. Initially it allows visiting vertices of the graph only, but there are hundreds of algorithms for graphs, which are based on DFS. Therefore, understanding the principles of depth-first search is quite important to move ahead into the graph theory. The principle of the algorithm is quite simple: to go forward (in depth) while there is such possibility, otherwise to backtrack.
Algorithm
In DFS, each vertex has three possible colors representing its state:
 white: vertex is unvisited;
white: vertex is unvisited;
 gray: vertex is in progress;
gray: vertex is in progress;
 black: DFS has finished processing the vertex.
black: DFS has finished processing the vertex.
NB. For most algorithms boolean classification unvisited / visited is quite enough, but we show general case here.
Initially all vertices are white (unvisited). DFS starts in arbitrary vertex and runs as follows:
- Mark vertex u as gray (visited).
- For each edge (u, v), where u is white, run depth-first search for u recursively.
- Mark vertex u as black and backtrack to the parent.
Example. Traverse a graph shown below, using DFS. Start from a vertex with number 1.
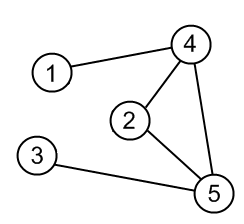 |
Source graph. |
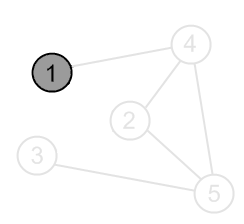 |
Mark a vertex 1 as gray. |
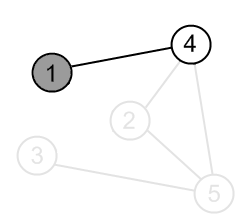 |
There is an edge (1, 4) and a vertex 4 is unvisited. Go there. |
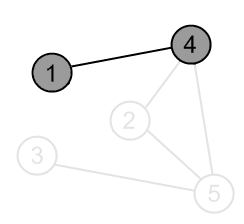 |
Mark the vertex 4 as gray. |
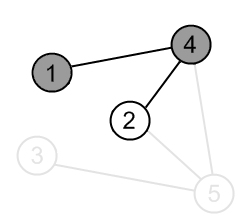 |
There is an edge (4, 2) and vertex a 2 is unvisited. Go there. |
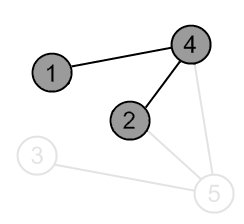 |
Mark the vertex 2 as gray. |
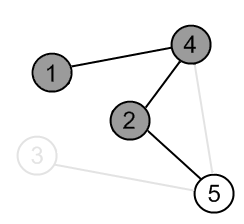 |
There is an edge (2, 5) and a vertex 5 is unvisited. Go there. |
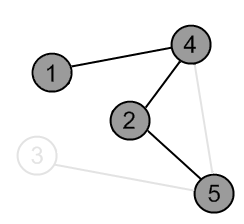 |
Mark the vertex 5 as gray. |
 |
There is an edge (5, 3) and a vertex 3 is unvisited. Go there. |
 |
Mark the vertex 3 as gray. |
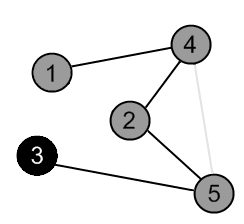 |
There are no ways to go from the vertex 3. Mark it as black and backtrack to the vertex 5. |
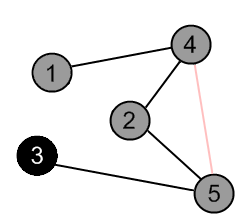 |
There is an edge (5, 4), but the vertex 4 is gray. |
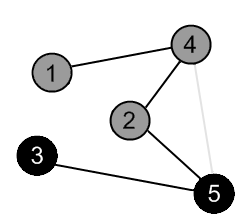 |
There are no ways to go from the vertex 5. Mark it as black and backtrack to the vertex 2. |
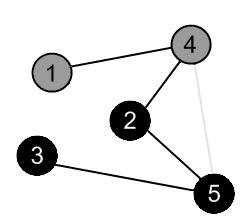 |
There are no more edges, adjacent to vertex 2. Mark it as black and backtrack to the vertex 4. |
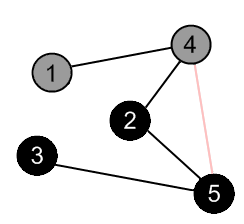 |
There is an edge (4, 5), but the vertex 5 is black. |
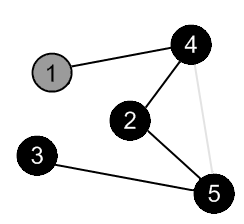 |
There are no more edges, adjacent to the vertex 4. Mark it as black and backtrack to the vertex 1. |
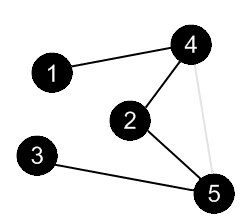 |
There are no more edges, adjacent to the vertex 1. Mark it as black. DFS is over. |
Complexity analysisIf a graph is disconnected, DFS won't visit all of its vertices. For details, see finding connected components algorithm.As you can see from the example, DFS doesn't go through all edges. The vertices and edges, which depth-first search has visited is a tree. This tree contains all vertices of the graph (if it is connected) and is called graph spanning tree. This tree exactly corresponds to the recursive calls of DFS.
Assume that graph is connected. Depth-first search visits every vertex in the graph and checks every edge its edge. Therefore, DFS complexity is O(V + E). As it was mentioned before, if an adjacency matrix is used for a graph representation, then all edges, adjacent to a vertex can't be found efficiently, that results in O(V2)complexity. You can find strong proof of the DFS complexity issues in [1].
Java Implementation
public class Graph {
…
enum VertexState {
White, Gray, Black
}
public void DFS()
{
VertexState state[] = new VertexState[vertexCount];
for (int i = 0; i < vertexCount; i++)
state[i] = VertexState.White;
runDFS(0, state);
}
public void runDFS(int u, VertexState[] state)
{
state[u] = VertexState.Gray;
for (int v = 0; v < vertexCount; v++)
if (isEdge(u, v) && state[v] == VertexState.White)
runDFS(v, state);
state[u] = VertexState.Black;
}
}
Summary: Depth-first Search(DFS)的更多相关文章
- [Algorithm] Write a Depth First Search Algorithm for Graphs in JavaScript
Depth first search is a graph search algorithm that starts at one node and uses recursion to travel ...
- [算法&数据结构]深度优先搜索(Depth First Search)
深度优先 搜索(DFS, Depth First Search) 从一个顶点v出发,首先将v标记为已遍历的顶点,然后选择一个邻接于v的尚未遍历的顶点u,如果u不存在,本次搜素终止.如果u存在,那么从u ...
- 幸运的袋子(深度优先遍历(Depth First Search,DFS))
题目描述 一个袋子里面有n个球,每个球上面都有一个号码(拥有相同号码的球是无区别的).如果一个袋子是幸运的当且仅当所有球的号码的和大于所有球的号码的积. 例如:如果袋子里面的球的号码是{1, 1, 2 ...
- Non recursive Depth first search
深度优先非递归实现算法: 1 递归算法: //初始化相关数据结构 DFS(G) ------------------------------------------------------------ ...
- Recursive Depth first search graph(adj matrix)
1 深度优先遍历邻接矩阵 1 邻接矩阵初始化 2 访问数组初始化 3 深度优先遍历邻接矩阵图 算法如下: bool MGraph[128][128]; bool visit[128]; int vex ...
- 深度优先搜索(Depth First Search)
Date:2019-07-01 15:31:11 通俗点理解就是不撞南墙不回头的那种,用栈来实现 算法实现 /* 题目描述: 有n件物品,每件物品的重量为w[i],价值为c[i].现在需要选出若干件物 ...
- 深度优先搜索 DFS(Depath First Search, DFS)
深度优先搜索是一种枚举所有完整路径以遍历所有情况的搜索方法.(不撞南墙不回头) DFS一般用递归来实现,其伪代码思路过程一般如下: void DFS(必要的参数){ if (符和遍历到一条完整路 ...
- [MIT6.006] 14. Depth-First Search (DFS), Topological Sort 深度优先搜索,拓扑排序
一.深度优先搜索 它的定义是:递归探索图,必要时要回溯,同时避免重复. 关于深度优先搜索的伪代码如下: 左边DFS-Visit(V, Adj.s)是只实现visit所有连接某个特定点(例如s)的其他点 ...
- 数据结构学习笔记05图 (邻接矩阵 邻接表-->BFS DFS、最短路径)
数据结构之图 图(Graph) 包含 一组顶点:通常用V (Vertex) 表示顶点集合 一组边:通常用E (Edge) 表示边的集合 边是顶点对:(v, w) ∈E ,其中v, w ∈ V 有向边& ...
随机推荐
- Android 反编译Apk提取XML文件
Apktool https://ibotpeaches.github.io/Apktool/install/ 下载地址:Apktool https://bitbucket.org/iBotPeache ...
- Centos重新启动网络配置文件,/etc/resolv.conf被覆盖或清空问题解决
Centos在执行命令 yum update时报错如下: Could not get metalink https://mirrors.fedoraproject.org/metalink?repo= ...
- 提高VS2010运行速度的技巧
任务管理器,CPU和内存都不高,为何?原因就是VS2010不停地读硬盘导致的; 写代码2/3的时间都耗在卡上了,太难受了; 研究发现,VS2010如果你装了VC等语言,那么它就会自动装SQL Serv ...
- State Server实现多机器多站点 Session 共享 全手记
网络环境有2台windows 2008 (192.168.1.71,192.168.1.72) 需要部署成 WebFarm,提高容错性. 网站部署在2台机器上的2个站点,如何才能做到Session的共 ...
- github使用密钥登录
注册github之后 初次使用git的用户要使用git协议大概需要三个步骤: 一.生成密钥对 二.设置远程仓库(本文以github为例)上的公钥 一.生成密钥对 再window系统中可以通过x ...
- tomcat+redis会话共享
1.基础环境: jdk1. tomcat7 redis nginx 2.添加依赖的jar包到tomcat的lib目录(http://pan.baidu.com/s/1eRAwN0Q) 3.配置tomc ...
- centos6.9环境下JDK安装部署
1.准备jdk安装文件: 这里我使用的是 jdk-7u79-linux-x64.tar.gz 2.在 /usr/local 目录下创建 sotfware目录,并上传JDK文件: 解压文件并修改文件夹为 ...
- ajax跨域获取返回值
js代码 $.ajax({ async:false, url: 'https://***/api/prepareApi.getDanMu?sqlMapId=findBarrage', // 跨域URL ...
- Sublime Text3注册激活和部分配置
1. 更改hosts文件(参照:sublime text3 破解方法,亲测有效) windows系统的hosts文件在C:\Windows\System32\drivers\etc在hosts文件中 ...
- 计蒜客 31001 - Magical Girl Haze - [最短路][2018ICPC南京网络预赛L题]
题目链接:https://nanti.jisuanke.com/t/31001 题意: 一带权有向图,有 n 个节点编号1~n,m条有向边,现在一人从节点 1 出发,他有最多 k 次机会施展魔法使得某 ...